退職時の年金戦略
昨年12月に会社勤めをやめ,個人事業主になった.5ヶ月たって やっと退職関連の手続きが終わったので,なんでこんな面倒なことになったのかメモっておく.
はー長かった…
企業年金の移換に時間がかかった
会社員だと 企業年金や厚生年金基金の積立をしている場合がある.これを個人型の確定拠出年金(DC) に移換しようとしていたため,ものすごい時間かかった.
なんでそんなことしたの?
雑にいえば,税金を取られたくなかったから.
退職時点で 規約型企業年金と企業型確定拠出年金の積立があった.勤務中に年金制度が変わったためにいろんな年金が混ざっているが,
- 企業年金 → 退職一時金として全額もらうか,個人型DC に移換できる
- 企業型DC → 個人型DC に移換
前者には選択肢があるが,会社の担当者いわく「みなさん,ほとんど一時金を選択します」とのこと.それ終身雇用の名残なのでは… よく考えないと 自分にあってるかわからないよ? 損するかもよ?
退職一時金を選んだ場合
国民年金と厚生年金の上の3階部分なので 額は大きくないかもしれないが,それでも勤続年数が長いと100万のケタに乗る場合がある.それを受け取ってなにかの資金にするのもアリだが,問題はガッツリ税金をとられること.
退職一時金は退職所得なので,退職金と合算の上 源泉徴収される.所得が増えるので,翌年の住民税が高くなる.
自分の場合は160万の原資に対して,源泉徴収分だけで10% ほど持っていかれる計算だった.
個人型DC に移換する場合
現金が少なくなるのはイタいが,積み立てた原資をそのまま移せる.所得にならないので 翌年の住民税を抑えられる.
自分の場合は150万の使いみちが決まってなかったし,収入が不安定になるから老後とかめちゃくちゃ心配だし,年金運用の資金を少しでも増やすためにこっちを選んだ.
税金って言っても,たかだか15万円とかでしょ?
個人型DC は課税を繰り延べできるので 複利で効いてくる.仮に年5% で運用できたら,30年後には
- 原資 145万円 → 145 x (1.05 ^ 30) = 626万円
- 原資 160万円 → 160 x (1.05 ^ 30) = 691万円
65万円のちがいになってる計算.目減りさせないことが鉄則なのです.
繰り延べと言っても,いまの制度だと公的年金と同じ控除 が受けられるので 受給時には税金がかからない可能性もある.
もちろん65歳までに死ぬかもしれないし,運用成績がマイナスになる可能性もあるが,まあそこは目をつぶろう.
まとめ
会社勤めからフリーランスになった場合,もしすぐ現金を必要としてなかったら,企業年金とか厚生年金基金は個人型確定拠出年金に移換したほうが有利そう.
ちなみに,よく知らないが転職の場合も同じように選択できるはず.
BGP Flowspec のバリデーション
BGP ルーターには,Flowspec という機能があります.2009年にRFC5575 として標準化されたもので,ざっくり言えば「遠くのルーターでパケットフィルターを発動させる」機能.
最近 注目されているこのFlowspec のうち,とくにバリデーションについて調べました.
2015-05-28 追記
@shtsuchi さんに指摘をもらい,IOS-XRv の実装が分かりましたので 追記しました.Flowspec ちゃんと動きます.コメントありがとうございました!
2023-01-31 追記
@a16tochjp さんに JUNOS 実装についてコメントをもらい,RFC9117 について追記しました.ありがとうございました!
ところで,使われてるの?
当初脚光を浴びましたが 大規模にデプロイする事業者がなく,その後しばらく下火でした.ここ数年でコンテンツプロバイダー中心にアーリーアダプターが使いはじめ,少しずつ注目されてきたのが現状です.

https://www.slideshare.net/Arbor_Networks/aol-flowspec-2015
BGP Flowspec とは
JANOG35 のセッション が詳しいです.
簡単に言えば
をBGP に乗せて伝搬させます.
- 通常のBGP で言えば「10.0.0.0/8」が入っていたところに「dst prefix=172.16.0.0/16, src prefix=any, proto=1」のような情報が
- BGP community のところに「rate-limit させる」のような情報が
入っているイメージです.*1
show route すれば「ああ,素直に出力してるんだな」と分かる程度にそのまま表示されます.
バリデーション?
Flowspec は パケット操作方法をeBGP にも乗せられる強力な機能なので,標準にも厳しくバリデーション方法が指定されています.各ルーターでは,Flowspec 経路それぞれをバリデーションし,valid であればそこに記述されているパケットフィルターを発動させます.
A flow specification NLRI must be validated such that it is considered feasible if and only if:
a) The originator of the flow specification matches the originator of the best-match unicast route for the destination prefix embedded in the flow specification.
b) There are no more specific unicast routes, when compared with the flow destination prefix, that have been received from a different neighboring AS than the best-match unicast route, which has been determined in step a).
By originator of a BGP route, we mean either the BGP originator path attribute, as used by route reflection, or the transport address of the BGP peer, if this path attribute is not present.
けっこう重要そうな項目なのに,これだけだと意味がわかりませんね.メーカーサイトにもわかりやすいドキュメントがなかったので「いくつかの実装を試して確かめました」というのが今回の趣旨です.
試したのはJuniper vSRX (12.1X47-D15.4),Cisco IOS-XRv (5.2.2).ともにFlowspec をFIB にインストールする部分が実装されていないようで,今回はルーティングだけの確認です.
Flowspec のオリジネーターとDestination Prefix
a) Flowspec のオリジネーターは,Flowspec 中のdestination prefix に対するベストマッチ経路のものと一致する必要がある
意味がわからない その1.
とあります.
BGP originator パスアトリビュートには,ORIGINATOR_ID のことですが,ルートリフレクターがクライアントのrouter ID を格納します.トランスポートアドレスは,ピアを張るIPアドレスそのものを指します.ですのでFlowspec ルーターは,RR 構成であれば経路のrouter ID を,そうでなければneighbor IP アドレスを使ってオリジネーターを識別していることになります.
なるほど.iBGP だけの世界なら単純そう.ところがiBGP とeBGP を混ぜて考えると少しわかりにくいかもしれません.
トランスポートアドレスが一致する,とは?
iBGP とeBGP がある構成を考えます.
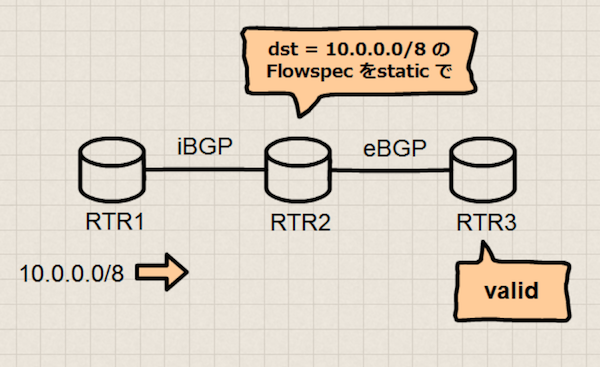
上の構成では どこにも経路フィルターを設定していません.RTR1 から10.0.0.0/8 の経路を広告し,RTR3 まで伝えます.
この構成でRTR2 にstatic なFlowspec (dst=10.0.0.0/8) を設定したとすると,RTR3 にも伝搬しますが,そこでは該当のFlowspec 経路はvalid になります.通常の経路はRTR1 でオリジネートし,Flowspec はRTR2 でオリジネートしたにも関わらず,です.
これは経路の向きを逆にして,RTR1 上で考えたとしても同じです.
このような動作になるのは,Flowspec ルーターがトランスポートアドレスによってオリジネーターを識別しているからです.ようするに「オリジネーターが同じ」とは,「同じBGP セッションから受信した」と解釈して構いません.*2
ベストマッチ経路とは?
該当のprefix を含有する最小の経路のことです.
たとえばBGP テーブル上に10.0.0.0/8 と10.0.0.0/16 がある場合,dst=10.0.0.0/24 なFlowspec 経路に対するベストマッチ経路は10.0.0.0/16 です.
また,ベストマッチ経路が存在しない場合はFlowspec 経路はinvalid です.
逆に言うとBGP テーブル上に10.0.0.0/8 がある場合は,dst=10.0.0.0/8~/32 までのFlowspec 経路がベストマッチ経路を持ち,valid になる可能性があります.
Destination Prefix が指定されていなかった場合は?
「dst 条件がなかったらどうなんの?」と思った方はするどいですね.
- Juniper vSRX の場合
- dst=0.0.0.0/0 相当です.この場合のベストマッチ経路はデフォルトルート(0.0.0.0/0) です.なので,dst 条件のないFlowspec 経路をvalid にするには,デフォルトルートが必要になります.
- Cisco IOS-XRv の場合
- オリジネーターバリデーションしません.なので,dst 条件のないFlowspec 経路をvalid にするために,デフォルトルートは必要ありません.
ここまでのまとめ
a) Flowspec のオリジネーターは,Flowspec 中のdestination prefix に対するベストマッチ経路のものと一致する必要がある
というのは,言いかえると
Flowspec 経路と,そのdestination prefix を含む最小の経路は,同じBGP セッションから受信する必要がある
2015-05-28 追記
Cisco IOS-XRv は「iBGP からFlowspec 経路を受信した場合に限り,上のオリジネーターバリデーションをスキップする」という実装になっています.詳しくは後述しますが,Juniper vSRX と動作が違うので注意です.
More Specific な経路があってはいけない,とは?
b) 異なるAS から受信する,more specific な経路がないこと
意味がわからない その2.

こちらも経路フィルターがない構成で,RTR1 とRTR3 から経路を注入します.すると,RTR2 のBGP テーブルに10.0.0.0/8 と10.0.0.0/24 が乗ります.
この状態ではRTR2 上でdst=10.0.0.0/8 なFlowspec 経路はinvalid になり,Flowspec テーブルには乗りません.more specific な/24 の経路があるためです.
「割り当てられた/8 から/24 を他者に割り振る」ような状況も考慮すると,「/8 単位での制御は危険だからやめとくべき」という意図だと思われますが,ちょっと窮屈ですね.
また,今回のテストではなぜか「異なるAS かどうか」は評価されないように見えました.10.0.0.0/24 をiBGP から受信しようが,eBGP から受信しようが,static な経路だろうが,dst=10.0.0.0/8 なFlowspec 経路はinvalid になります.
RFC によると「異なるAS からmore specific 経路が広告された場合のみinvalid」になりそうですが,そのような動作はしません.*3
Destination Prefix が指定されていなかった場合は?
- Juniper vSRX の場合
- dst=0.0.0.0/0 相当なので,デフォルトルート以外の経路が存在しない場合に限り 該当のFlowspec 経路はvalid になります.通常そんなことはありえないので,destination prefix が指定されていないFlowspec は常にinvalid です.
- Cisco IOS-XRv の場合
- more specific バリデーションしません.destination prefix が指定されていないFlowspec もvalid になる可能性があります.
Flowspec をstatic に設定することができる
ここまでで,Flowspec のバリデーションは
- Flowspec 経路と,そのdestination prefix を含む最小の経路は,同じBGP セッションから受信している
- BGP テーブル上に,destination prefix よりmore specific な経路がない
ことを確認するものだ,と理解できます.
この動作に不都合を感じる場合は,Flowspec をstatic に設定することで,設定したルーター上に限りバリデーションをスキップすることができます.
たとえばJUNOS でdst prefix を指定せずFlowspec を有効にしたい場合,該当ルーターすべてにstatic 設定することで実現できます.ただ,「そこまでするならパケットフィルターを書いて回ったほうがいいんでは」と感じます.
ほかにstatic 設定はFlowspec をオリジネートするためにも使われますが,通常はこっちがメインだと思います.
Neighbor やピアグループ単位でバリデーションを無効にできる (2015-05-28 追記)
AS内だけでFlowspec を使う場合など,厳しいバリデーションが邪魔になることがあります.その場合はNeighbor やピアグループ単位でバリデーションをスキップすることができます.
Juniper vSRX:
protocols {
bgp {
group ibgp {
family inet {
flow {
no-validate skip-validation;
}
}
}
}
}
policy-options {
policy-statement skip-validation {
then accept; # フィルター条件をいろいろ書ける
}
}
router bgp 64600 neighbor 192.168.1.20 address-family ipv4 flowspec validation disable
Juniper vSRX とCisco IOS-XRv のちがい (2015-05-28 追記)
destination prefix 指定のないFlowspec の扱いなどに違いはありますが,一番大きな差は
@codeout メールしまーす。簡単にいうと、RFC5575の部分、draft-ietf-idr-bgp-flowspec-oidでiBGPはリラックスさせる。eBGPだとknobで無効化しなきゃいけないって感じ
— Shishio Tsuchiya (@shtsuchi) 2015年5月26日
です.Cisco IOS-XRv はdraft-ietf-idr-bgp-flowspec-oid-02 が実装されており,オリジネーターバリデーションが一部変更されています.
Step (a) of the validation procedure specified in RFC 5575, section 6 is redefined as follows:
a) One of the following conditions MUST hold true: o The originator of the flow specification matches the originator of the best-match unicast route for the destination prefix embedded in the flow specification. o The AS_PATH and AS4_PATH attribute of the flow specification are empty. o The AS_PATH and AS4_PATH attribute of the flow specification does not contain AS_SET and AS_SEQUENCE segments.
簡単に言えば「iBGP からFlowspec 経路を受信した場合に限り,上のオリジネーターバリデーションをスキップする」です.オリジネーターがベストマッチ経路と一致しない場合や,ベストマッチ経路が存在しない場合でもvalid になる可能性があります.
RFC9117 (2023-01-31 追記)
現在👆のI-Dは RFC9117 になっています.
未確認ですが,多くの実装で iBGP から受信したFlowspec 経路に関するバリデーションをスキップすると思われます。@a16tochjp さんのコメントによると「JUNOSもそうなっている」とのことです.
その他
- JUNOS の場合,特定のPFE やVRF だけにインストールすることはできないようです.インターフェイスを指定して設定するパケットフィルターとは考え方が変わる点に注意
- Flowspec 経路にも BGP community をつけることができます.いつものようにBGP community を見る経路フィルターを作れば,Flowspec 経路を選択的にvalid にすることができます
- Juniper とCisco で実装が違うので注意
どう使うか?
今回のIOS-XRv のように期待通り動かないことや,CloudFlare でのトラブル のような例もあります.議論の余地はありますが,現状だと まだ「コミュニティに知見が足りないため検証するしかないが,コストに対して得られるメリットが小さい」場合が多そうです.
一方で「用途を限ればすごく便利で,コスト問題も解決できるかも」と感じています.
たとえば,次のような使い方はよさそう.

DDoS 対策など,小さいdst prefix を守るために使う
- dst prefix が広い場合,more specific バリデーションで落とされる可能性が高い
- more specific 経路が無ければ大きいdst prefix でも動くが,いちいち確認するのが手間
exabgp のようなAPI 豊富なソフトウェアルーターを使い,Flowspec を注入する
- 自動化のため
AS ボーダーでフィルターする目的で,ソフトウェアルーターは1段階だけ下流のルーターとピアする
- 小さいdst prefix を守りたい場合,その経路はおそらく下流からくる
- トランスポートアドレスバリデーションにより,AS ボーダーでのみFlowspec が動くと期待できる
特定のルーターでのみ発動させたい場合は,BGP community で制御
強力なので,ハマれば便利そうですが…どうでしょうかね. 「こういう使い方できそう」「こうやってる」などなど,ぜひご意見ください!
VirtualBox 上の IOS-XRv コンソールに接続する
Cisco IOS-XRv は ハイパーバイザーが開くTTY にコンソールを接続してくれないので,自分で設定する必要がある.
たとえばVMWare Fusion はコンソールをPTY に繋ぐ機能があるので簡単だが,VirtualBox は面倒.
コンソールをドメインソケットとして出す
下のような設定をする.
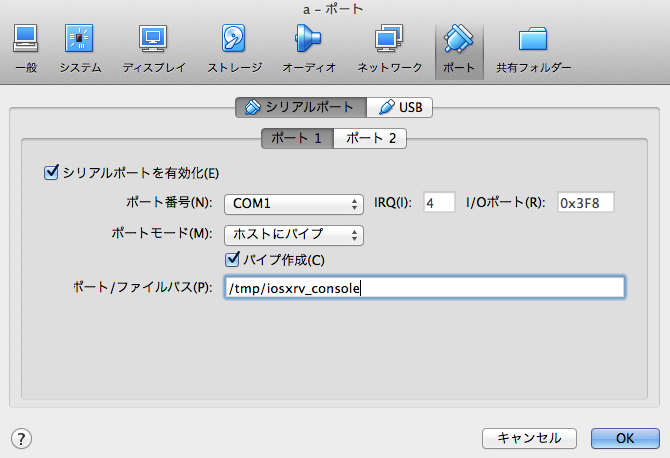
socat で接続する
brew install socat socat UNIX-CONNETCT:/tmp/iosxrv_console stdio,raw,echo=0,escape=0x1a
こんな感じで標準入出力をドメインソケットに接続できる.escape=0x1a は^Z で接続を切るための設定.このへん を参考にしながら好みで変えるといいと思う.
ネットワークエンジニアリングはアジャイルじゃない
リーン・スタートアップと言ってもいい.Web 界隈ではあたりまえの開発手法を ネットワークの開発に使うのはむずかしい.
自分はインターネットが得意で (ネットワークとしてのインターネットね!) たかだかIP と上下レイヤーくらいしか分からないんだけど,なにか新機能を作るときの事情はだいたい共通していると思うし,幅広く「ネットワーク」とくくってしまう.実際は共通どころか,エンタープライズネットワークのほうが制約が多いし,IP よりPHY のほうがつらい.まだ自由度があるインターネットでさえ,Web 界隈やミドルウェア,サーバーインフラ界隈のようなスピードで動けない.
うらやましいことに,それらの開発についてはオンライン/オフラインいろんなところで議論され,本が出版され,ノウハウが溜まっていく.一方でネットワーク開発は 低いギアでアクセル踏みっぱなしのような,なんか「タスクこなしてるんだけど進んでない感じ」がする.なんですかこの違い.アプリレイヤーの仕事をしているときとは違ったストレスを感じる.
ネットワークエンジニアリングの現場
ハードウェア / ソフトウェアを使ってネットワークに新機能を足したり,地理的に / 帯域的に拡張したり,運用を変えたりする場合,
- どういう技術があるか調査する
- テスト環境で粗く試す
- 設計する
- 必要なハードウェア,ソフトウェアを調達する
- 検証環境でちゃんと試す
- 必要な回線を調達する
- ユーザーから借用をとる
- ハードウェア,ソフトウェア,回線をインストールする
- デプロイする
みたいなことが必要だが,あるあるネタとして
- 調達のリードタイムが予測できない / 長い
- やってみないと,実網にどんな影響が出るかわからない
- 借用に要する時間が予測できない / 長い
こういう問題をよく見る.たとえばソフトウェア開発と比較すると「ソフトウェアには起こらない問題」と「起こってるんだけど頑張って回避している問題」が含まれていて,ネットワークエンジニアはソフトウェアエンジニアが頑張っているところを盗まないといけないと思う.
もちろん「コード書いて自動化しましょう」もその1つなんだけど,生産性が低い原因はたぶんそれだけではない.
生産性の低さ
自分は,デプロイまでの待ち時間が大きな原因だと思っている.調達とか 会社をまたいで調整しないといけないタスクが挟まっていたり,借用 (お客さんに「メンテしていいですか」と聞いて回る営み) のようなタスクがあるかもしれない.契約上は1ヶ月前に通知すればメンテできるが,慣例で一部法人ユーザーにお伺いを立てたりすることがある.「これ!と決めたやつをデプロイするまでに1ヶ月待たないといけない」なんて普通にある.
そのせいで 年間のデプロイ回数が限られ,フィードバックがないから試行錯誤できず,一発で大成功させようとして準備の時間が増え,待っている間にネットワークが変わって手戻りが発生する. 他者との調整が主なボトルネックだから,ミーティングが増え,資料を作りまくり,調整能力だけがグングン伸びる.
ソフトウェア開発はどうやっているか
アジャイル「イテレーションを小さく回せ」リーン・スタートアップ「MVP から始めよ」両方とも,デプロイに時間をかけず フィードバックを短期間で得るための努力があってのことだと思う.大規模にやれば「マージに時間がかかる」「QA チームが求める品質にならない」いろんな問題が出るところを,「CI を回す」「毎週火曜日にリリースすることにする」「組織を変えて,QA 機能をプロジェクト内に持つ」「ベータ提供するしくみ」「一部ユーザーにのみデプロイし,小さく失敗して早く直す」など,技術で解決するのはもちろんのこと 組織 / ワークフロー / ポリシーを見直して頑張ってる.
ネットワーク開発は何ができるか
「調達のリードタイムが予測できない / 長い」というのはしょうがない.でも「在庫を持つコスト」と「持たないことによる生産性の低下」は天秤にかけられるかもしれない.
「やってみないと,実網にどんな影響が出るかわからない」とくにインターネットルーティングは生き物だからしょうがないけど「自分たちのネットワークは複雑だから,やってみないとわかりません」は避けないといけない.シンプルに保つ努力は必要だし,インターネットの端っこにテストベッドを持つ選択肢もあるし,堅く作る前のベータサービスに付き合ってくれるユーザーがいるかもしれない.
「借用に要する時間が予測できない / 長い」レイヤーが低いほど上に乗っているものが多い = 影響範囲が大きいので,メンテナンスには慎重になるべき.でもメンテナンスポリシーが曖昧だと「うーん,分からんけど安全側に倒して…」ってなるし「契約ではできることになってるけど,いままでそうしてなかったから…」みたいなのも癌だと思う.
ちなみに
いま,週のうち数日はフリーのネットワークエンジニアとして働いており,タスクをガッとこなす日と何もしない日が極端に分かれている.それでも自分がボトルネックになるケースは少ない (はず!) ので,待ちが多いと時間を区切って生産性を上げるという手が効く.そういう意味では,トヨタのリーン生産方式の方は勉強しないとなあ,と思ってる.
Time Attack: bgpsimple vs exabgp 2nd Heat
After @exabgp thankfully gave me an advice on my previous post, I carried out performance tests of bgpsimple and exabgp again.
@codeout Great blog entry: http://t.co/FHKPp9DXN6 . It would be great if you could check how much faster our API is to send the routes out.
— ExaBGP (@exabgp) May 15, 2015Right, API might be faster than massive config loading.
Full Route Advertisement
Service providers are struggling with the growing IPv4 full route and recently some people abandon default-free zone due to TCAM space problem. But they still sometimes need full route for analysis and forensic purpose. So, I'm curious, in such a case, is there good toolbox to inject full route into their network?
I think that simple BGP daemons are good options,
- bgpsimple
- exabgp with mrtparse
can read a full-table bgpdump archive and advertise to neighbor routers. Then, how fast are they?
Test Equipments
- MacBook Pro (Retina, Mid 2012) + VMWare
- Guest
Firefly was configured as a dumb BGP neighbor rejecting any route so that it couldn't affect route injector's performance.
Benchmark
| bgpsimple | exabgp with config file | exabgp with API | |
|---|---|---|---|
| Until BGP turnup | 0'00" | 2'58" | 0'02" |
| To complete advertising since BGP turnup | 2'38" | 1'13" | 4'13" |
| To complete advertising since "clear bgp neighbor" | 2'43" | 2'09" | 2'31" |
Version tested: *1
It took bgpsimple 2'38" to advertise full route, while exabgp required 4'11" ~ 4'15" in total.
exabgp shows different behavior depending on its configuration. exabgp with config file in the table above means "a bunch of static routes configured in .conf converted by mrtparse", exabgp with API means "configured to run an external script for route injection". The script looks like:
import sys import time messages = [ 'announce route 1.0.0.0/24 origin IGP as-path [2497 15169 ] next-hop 192.168.0.78', ... ] while messages: message = messages.pop(0) sys.stdout.write( message + '\n') sys.stdout.flush() while True: time.sleep(1)
See exabgp's wiki for more details.
Conclusion
bgpsimple is handier and faster way to inject full route from bgpdump archive. It simply assumes that the route information is given as a file in bgpdump -m format, read it with no signal handling and process routes in a simple loop with generating a minimal set of objects.
*1:Different version of exabgp from the previous post
ruby で pcap を読む
tcpdump やtshark などでキャプチャーしたパケットを,ruby で読むためのライブラリがあります.
The Ruby Toolbox などで検索すると山のように出てきますが,いくつか良さそうなのを紹介します.
PacketFu
例: IP パケットのsource address だけを抽出したい場合:
require 'packetfu' packets = PacketFu::PcapPackets.new.read(File.read('sample.pcap')) packets.each do |p| packet = PacketFu::Packet.parse(p.data) puts packet.respond_to?(:ip_saddr) && packet.ip_saddr end
PacketFu::Packet#inspectがちゃんとあってprint デバッグしやすい
[1] pry(main)> p packet --EthHeader------------------------------------------------- eth_dst fe:ff:20:00:01:00 PacketFu::EthMac eth_src 00:00:01:00:00:00 PacketFu::EthMac eth_proto 0x0800 StructFu::Int16 --IPHeader-------------------------------------------------- ip_v 4 Fixnum ip_hl 5 Fixnum ip_tos 0 StructFu::Int8 ip_len 48 StructFu::Int16 ip_id 0x0f41 StructFu::Int16 ip_frag 16384 StructFu::Int16 ip_ttl 128 StructFu::Int8 ip_proto 6 StructFu::Int8 ip_sum 0x91eb StructFu::Int16 ip_src 145.254.160.237 PacketFu::Octets ip_dst 65.208.228.223 PacketFu::Octets --TCPHeader------------------------------------------------- tcp_src 3372 StructFu::Int16 tcp_dst 80 StructFu::Int16 tcp_seq 0x38affe13 StructFu::Int32 tcp_ack 0x00000000 StructFu::Int32 tcp_hlen 7 PacketFu::TcpHlen tcp_reserved 0 PacketFu::TcpReserved tcp_ecn 0 PacketFu::TcpEcn tcp_flags ....S. PacketFu::TcpFlags tcp_win 8760 StructFu::Int16 tcp_sum 0xc30c StructFu::Int16 tcp_urg 0 StructFu::Int16 tcp_opts MSS:1460,NOP,NOP,SACKOK PacketFu::TcpOptions
- C拡張ではないため 遅い
pcap / ruby-pcap
例: IP パケットのsource address だけを抽出したい場合:
require 'pcap' packets = Pcap::Capture.open_offline('sample.pcap') packets.each do |packet| puts packet.ip? && packet.ip_src end
このgem はruby 2.2 に対応してません.(2015-07-27 追記: 対応されました)
本体に取り込まれるまでは
gem install specific_install gem specific_install https://github.com/codeout/ruby-pcap
or
git clone https://github.com/codeout/ruby-pcap cd ruby-pcap gem build pcap.gemspec gem install --local pcap-0.7.7.gem
でインストールできます.
ほか
いろいろありますが,各種プロトコルヘッダーにアクセスするAPI が少なくて使いやすいとは言えません.
ベンチマーク: PacketFu vs. pcap
10,000 パケットの処理時間:
user system total real PacketFu 3.760000 0.040000 3.800000 ( 3.857046) pcap 0.010000 0.000000 0.010000 ( 0.012067)
やはり差が出ます.パフォーマンスが要求される場合は pcap オススメ.
ベンチマーク用コード:
require 'packetfu' require 'pcap' require 'benchmark' Benchmark.bm do |x| packets = PacketFu::PcapPackets.new.read(File.read('sample.pcap')) x.report('PacketFu') do packets.each do |p| packet = PacketFu::Packet.parse(p.data) packet.respond_to?(:ip_saddr) && packet.ip_saddr end end packets = Pcap::Capture.open_offline('sample.pcap') x.report('pcap') do packets.each do |packet| packet.ip? && packet.ip_src end end end
別途PacketFu をプロファイリングしてみても,パケットのparse が遅そうです.
% cumulative self self total time seconds seconds calls ms/call ms/call name 6.44 10.16 10.16 297491 0.03 0.05 StructFu::Int#read 4.46 17.20 7.04 171613 0.04 0.06 PacketFu::EthPacket.can_parse? 3.33 22.45 5.25 70757 0.07 0.15 PacketFu::IPPacket.can_parse? 3.02 27.22 4.77 296710 0.02 0.02 PacketFu.force_binary 3.00 31.96 4.74 44296 0.11 0.18 PacketFu::EthOui#read 2.45 35.83 3.87 12958 0.30 4.20 PacketFu::IPHeader#read 2.30 39.46 3.63 8866 0.41 2.22 PacketFu::TCPPacket#tcp_calc_sum 2.17 42.89 3.43 1149060 0.00 0.00 String#[] 2.09 46.19 3.30 17732 0.19 1.64 PacketFu::TcpOptions#read 2.09 49.49 3.30 27390 0.12 0.30 PacketFu::TcpOption#read 2.08 52.77 3.28 79465 0.04 0.06 PacketFu::Packet.layer 1.93 55.81 3.04 155600 0.02 0.03 StructFu::Int#to_i 1.84 58.72 2.91 966615 0.00 0.00 Struct#[] 1.83 61.61 2.89 159701 0.02 1.18 PacketFu::Packet.parse 1.80 64.45 2.84 8866 0.32 4.71 PacketFu::TCPHeader#read 1.79 67.28 2.83 278978 0.01 0.03 Struct#force_binary
Time Attack: bgpsimple vs exabgp
お手軽フルルート環境に興味が出て,どの程度お手軽にできるのか試しました.
(参考: Other OSS BGP implementations · Exa-Networks/exabgp Wiki · GitHub)
をざっと見て
ので選ぶと,bgpsimple / exabgp が候補になります.
bgpsimple,Google Code にしかないっぽいんだけど 大丈夫か...
フルルート広告の所要時間が気になる
bgpsimple はbgpdump でMRT table dump をテキスト化すれば入力できるし,exabgp はmrtparser で設定ファイルを出力できます.両方お手軽なんですが,経路広告の所要時間が気になるので計測してみました.
環境
- MacBook Pro (Retina, Mid 2012) + VMWare
- Guest
- 4x Intel(R) Core(TM) i7-3820QM CPU @ 2.70GH
- 2GB RAM
経路受信側は別Hypervisor のfirefly.ボトルネックにならないよう,経路はすべてreject する設定.
結果
| bgpsimple | exabgp | |
|---|---|---|
| ピアが上がるまで | 数秒 | 3'59" |
| フルルート広告し終わるまで | 2'39" | 1'15" |
| clear bgp 後,フルルート広告し終わるまで | 2'34" | 2'57" |
bgpsimple のほうがトータル速そう.exabgp は設定ファイルをload → parse するのに4分もかかるため,全体として2倍遅いです.
注意
bgpsimple を使うときはholdtimer を長く
bgpsimple は経路を広告し終わるまでKEEPALIVE メッセージを送らないため,経路広告が終わるまえにHold Timer Expire する可能性が高い.
exabgp は適宜KEEPALIVE してくれます.
bgpsimple は,経路リストの全エントリーについて広告
bgpdump -m によってMRTをテキスト変換してbgpsimple に入力しますが,もとのMRT には複数neighbor 分の経路が保存されています.そのため,テキスト変換された経路リストには同じprefix の経路が複数含まれている場合があります.これを順次UPDATE メッセージとして送信すると,対向のfirefly では後に受け取ったpath だけがAdj-RIBs-In に残ります.
ムダですね.
exabgp はMRT ファイル上で先に現れた経路のみ広告
mrtparser の仕様により,prefix が同じであれば先に読まれたpath のみUPDATE メッセージとして送信します.ムダはありませんが,bgpsimple で経路広告した場合と比べて 対向のAdj-RIBs-In の中身が変わってくることに注意です.