PeeringDBの過去データを読む
インターネットルーティングに関わっていると、まれに PeeringDB の過去データを集計したくなります。
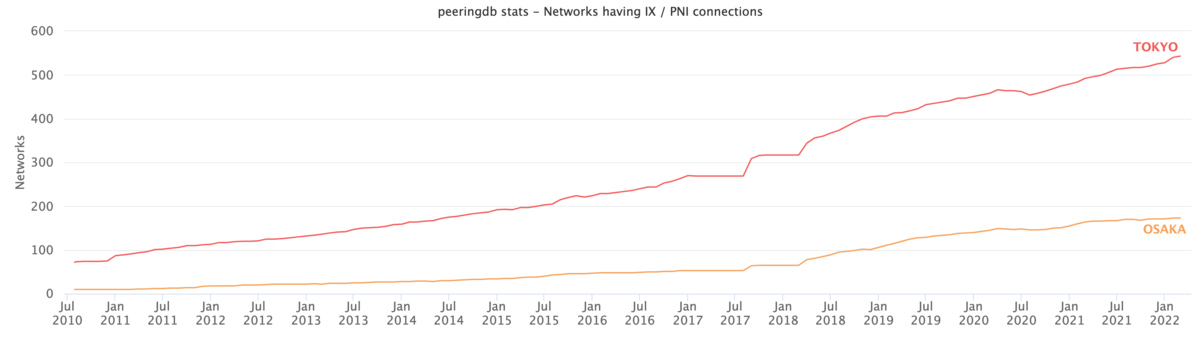
https://www.peeringdb.com から現在の情報は取れますが、「過去に遡りたい」「特定の国・地域・事業者に注目して時間推移を見たい」といった要望を満たせません。そこで CAIDAが公開してくれている PeeringDB の daily snapshot を読み、集計し、下のようなグラフを描いてみます。東京・大阪の事業者数の推移です。
CAIDA PeeringDB Dataset
CAIDA Acceptable Use Agreement に同意し コンタクト情報と利用用途をsubmitすれば、PeeringDB アーカイブをダウンロードできます。
PeeringDBは 2016-03-15 にv2になり、スキーマが新しくなりました。バージョンごとに利用可能なアーカイブ種別も異なります。
| 時期 | PeeringDB v1 | PeeringDB v2 |
|---|---|---|
| 2010-07-29 ~ 2015-12-31 | .sql, .sqlite |
|
| 2016-01-01 ~ 2016-03-14 | .sql, .sqlite |
.sql, .sqlite |
| 2016-05-27 ~ 2018-03-10 | .sqlite |
|
| 2018-03-11 ~ | .json |
- v2 リリース直後はアーカイブがありません
- 2016-03-14 以前のv2データはβリリース版のものです
アーカイブをどう読むか
SQLで好きに集計できそうなのですが、最近の v2 データはAPIダンプになっていてDBに書き戻せず、 JOIN するのが厳しいです。また、古い v1 データは DBダンプがありますが 対応するappが公開されていません。
- 試行錯誤しつつ検索条件・集計方法・出力を変えたいので、言語は何でもいいがプログラム処理したい
- ORM があると便利
なので、ORMが使えるフレームワークを使い 最低限アーカイブを読めるappをでっちあげ、集計プログラムを書くのがよさそうです。
アーカイブを読むためのapp
DBスキーマからよしなにモデルを生成してくれる ( DBにある情報はプログラム側に書かなくてもよい ) フレームワークのひとつにRailsがあります。PeeringDB v2は Django 製ですが、v1 流用を考えた場合アーカイブを読むだけならRailsのほうがたぶんラクです。
v2 期間だけでよければ、 公式Django モデル 向けloaderを書くのが早いと思います。
Railsで読む場合、たぶんこんな感じになります。
v2 データを読む例を記載しますが、もし興味があれば使い方は README を見てください。
$ git switch peeringdb-v2 $ bundle install $ sqlite3 db/development.sqlite3 < db/598a658.sql # Download any json file of v2 as archive.json for example, then $ rails runner script/load.rb archive.json
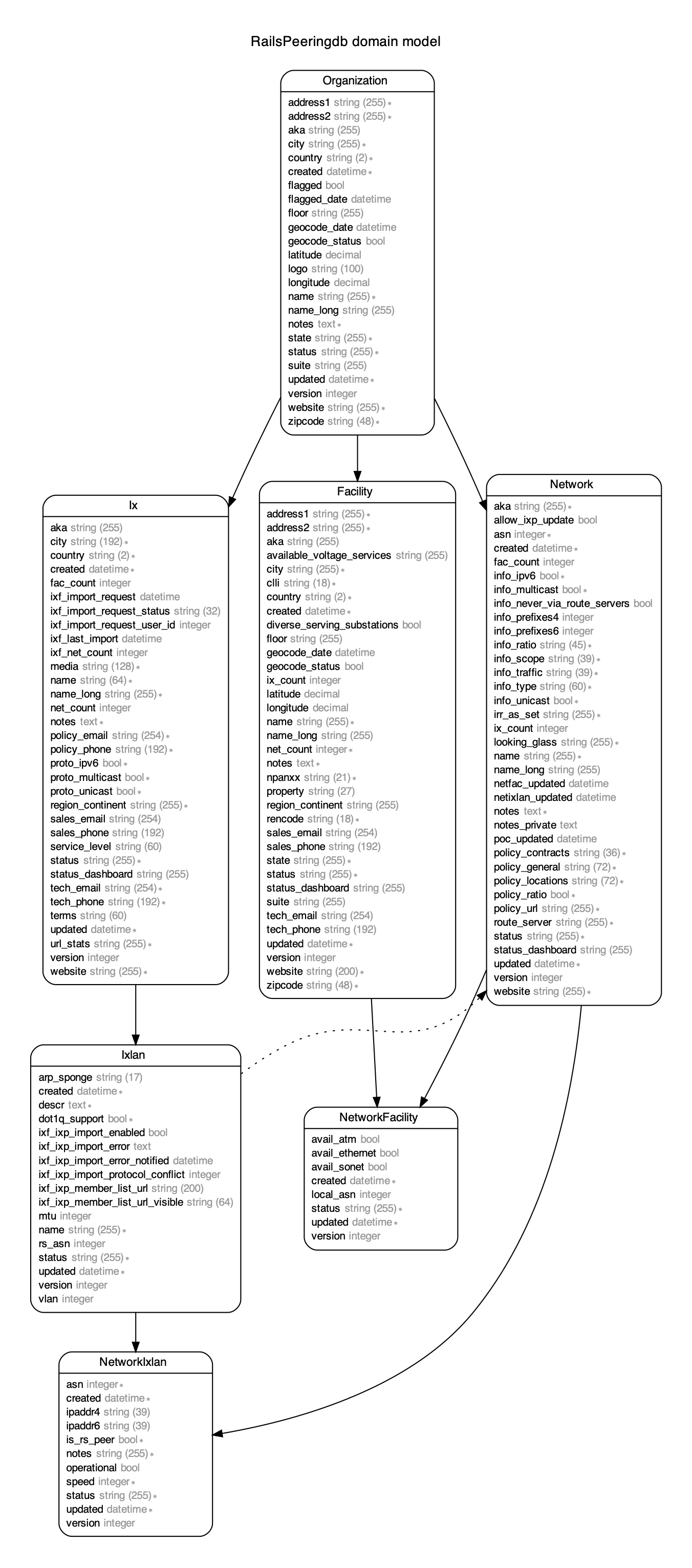
v2 データをロードするとDBスキーマはこうなります。公式Django PeeringDB モデルと同じはずです。
データをロードできたら、集計プログラムを書きます。たとえば「日本の都市ごとに、POPがある or IX接続がある事業者を数える」場合はこんな感じになると思います。
require 'json' ixs = Hash[Ixlan.joins(:ix).includes(:networks).where(ix: { country: 'JP' }).group_by { |i| i.ix.city }.map { |c, ixlans| [c, ixlans.map(&:networks).flatten.uniq] }] privates = Hash[Facility.includes(:networks).where(country: 'JP').group_by(&:city).map { |c, facilities| [c, facilities.map(&:networks).flatten.uniq] }] cities = (ixs.keys + privates.keys).uniq stats = Hash[cities.map { |c| [c, { ix: ixs[c]&.count || 0, private: privates[c]&.count || 0, total: ((ixs[c] || []) + (privates[c] || [])).uniq.count }] }] def upcase_keys(hash) normalized = {} hash.each do |k1, v| if normalized.has_key?(k1.upcase) v.keys.each do |k2| normalized[k1.upcase][k2] += v[k2] end else normalized[k1.upcase] = v.dup end end normalized end print JSON.dump(upcase_keys(stats))
v1 データを読みたい場合は、GitHubレポジトリに スキーマ と サンプル があります。
グラフを描画する
ここでは省略しますが、PeeringDBアーカイブから任意の時点・検索条件・集計方法でjson出力を得られるので、好きな方法でグラフ化してください。