yaml validator としてのCUE
設定やデータをファイルにするとき、どんなフォーマットを使いますか?
ファイルにアクセスする言語が決まっているなら その言語で直に書く場面も多いと思います。不特定の言語から扱うなら .json とか .yaml ですか?
可読性の観点で 個人的には .yaml が好みですが、いくつか困っていることがありました。
その困りごとを CUE で解決できそうだったので 紹介したいと思います。
yaml を扱う上での困りごと
一言でいえば「スキーマ定義の標準、もしくは強力なツールセットがない」です。スキーマは、
- 人間が読めること
- 実行できること (スキーマをもとに validate できること)
が望ましいと考えています。
yaml を書きたいが 書くべきデータ構造がわからない場合、おそらくドキュメントを参照しますよね。 逆に、データ構造を決める側はドキュメントをメンテしないといけません。とてもめんどくさく、普通は更新を忘れます。 人間が読めるスキーマファイルがあって、それ自体を使って簡単に validate できる = 更新忘れに気づける ことが理想です。
これは json であれば満たせます。 一方で「人間が何度も読むデータは可読性重要」という思いがあり、迷ったあげく yaml を選択し、がんばってドキュメントを書くということをやっていました。
CUE を使うとどうなる?
CUE が何か、何ができるかの詳細についてはここでは触れません。公式の "Use Cases" が参考になると思います。日本語であれば 👇 がわかりやすいです。
Apache License 2.0、"This is not an officially supported Google product" です。これは yaml スキーマの標準ではありませんが、少し使ってみたところ十分強力だと感じました。 4年間 active に開発が続いています。
では、具体的なデータとスキーマを使って CUE がどんな感じか見てみましょう。
validate 対象となるデータ
ネットワーク機器の設定をイメージしています。スキーマは適当に考えました。
# ./config.yaml os: junos platform: qfx10002 interfaces: - name: et-0/0/1 type: transit # 物理にだけ type / speed を書く speed: 100g description: very fast transit # optional - name: et-0/0/1.0 ipv4: # unit にだけ ip を書く address: 10.0.0.2/30 - name: et-0/0/3 type: globe wide ix speed: 40g - name: et-0/0/3.0 ipv4: address: 10.0.1.1/24
CUE によるスキーマ
# ./schemas/config.cue package config os: "junos" | "ios" platform: string
# ./schemas/interface/interface.cue
package config
import "net"
#interface: {
name: =~"^..-\\d+/\\d+/\\d+(\\.\\d+)?$"
// physical interface like et-0/0/0
if name !~ "\\." {
type: "transit" | "peer"
speed: "40g" | "100g"
description?: string
}
// sub-interface like et-0/0/0.0
if name =~ "\\." {
ipv4: {
address: net.IPCIDR & !~":"
}
}
}
interfaces: [...#interface]
interfaces: 配下はごちゃごちゃしがちなため、ファイルを分けておきます。
パッと見て、どういう文脈でどういうキーが使えるか・どういう値を取りえるか なんとなくイメージできると思います。
しかも JSON Schema よりだいぶ読みやすい。
$ cue vet schemas/config.cue schemas/interface/interface.cue config.yaml
のようにして .yaml を直接 validate できます。
通常は拡張子からファイルタイプを推測しますが、指定することも可能です。
$ cue vet schemas/config.cue schemas/interface/interface.cue yaml: config
サポートされているファイルタイプは cue filestypes で一覧できます。
追加の制約を適用する
CUE の面白いところは、既にあるスキーマを変更することなく外から制約を追加できる点です。 たとえば「peer は 100GE であるはず」という制約を追加します。
# ./schemas/fast-peer.cue
package config
#interface: {
type: string
speed: string
if type == "peer" {
speed: "100g"
}
}
.cue ファイルを追加指定すればOK。
$ cue vet schemas/config.cue schemas/interface/interface.cue schemas/fast-transit.cue config.yaml
わかりにくくて完全にやりすぎですが、QFX Port Mapping をCUEで表現した例。
# ./schemas/interface/qfx.cue
package config
import "list"
if platform == "qfx10002" {
#interface: {
name: string
speed?: string
if name !~ "\\." {
{
_invalid_100g: [
for i in list.Range(0, 36, 6) if name =~ "-0/0/\(i)$" && speed == "100g" {true},
for i in list.Range(0, 36, 6) if name =~ "-0/0/\(i+2)$" && speed == "100g" {true},
for i in list.Range(0, 36, 6) if name =~ "-0/0/\(i+3)$" && speed == "100g" {true},
for i in list.Range(0, 36, 6) if name =~ "-0/0/\(i+4)$" && speed == "100g" {true},
false,
][0]
} & {_invalid_100g: false}
}
}
}
_checks: {
invalid_port_mapping: {
list.Contains([ for i in list.Range(0, 36, 6) {
if [ for intf in interfaces if intf.name =~ "-0/0/\(i+1)$" {true}, false][0] {
[
for intf in interfaces if intf.name =~ "-0/0/(\(i)|\(i+2))$" {true},
false,
][0]
}
if [ for intf in interfaces if intf.name =~ "-0/0/\(i+5)$" {true}, false][0] {
[
for intf in interfaces if intf.name =~ "-0/0/(\(i+3)|\(i+4))$" {true},
false,
][0]
}
}], true)
}
} & {invalid_port_mapping: false}
ビジネスロジックよりの制約だけではなく、ネットワーキングではハードウェア制約が多いため「 platform == "qfx10002" ならばこう」のような表現ができると便利です。
エントリーポイントを量産せず、制約を付け外しできるのは良い
ここまで
- データ構造の定義
- ビジネス上の制約
- ハードウェア上の制約
それぞれ例を書きました。これを組み合わせて適用する場合、たとえば JSON Schema では 1~3 を呼び出すエントリーポイントを別に書く必要があります。 現実の制約はもっと多岐にわたり、組み合わせ数は爆発します。
一方 CUE ではエントリーポイント自体が不要です。 *1 入口に限らず どのような階層でも不要です。ここが気に入りました。
package として制約(スキーマ) に名前をつけ、ディレクトリ構成を絡めて指定できるパッケージシステムがあり、カンタンに制約を付け外しできるのは強力なアプローチです。
Standard Packages
CUE 自体に Standard Package がついており、簡単な演算ができます。
残念なのは iteration 関数が少ないこと。先ほどの QFX Port Mapping の例のように list を扱おうとするといきなり複雑になります。 半順序関係をユーザーが定義できればスッキリ書けるかもしれませんが、可読性とのトレードオフがあります。
「計算が必要なものはスキーマに含めない」くらいがバランスとしてちょうどいいのかもしれません。
スキーマとデータとlattice(束)
制約を後付けできるしくみは、特徴的なスキーマとデータの扱い方によるものです。
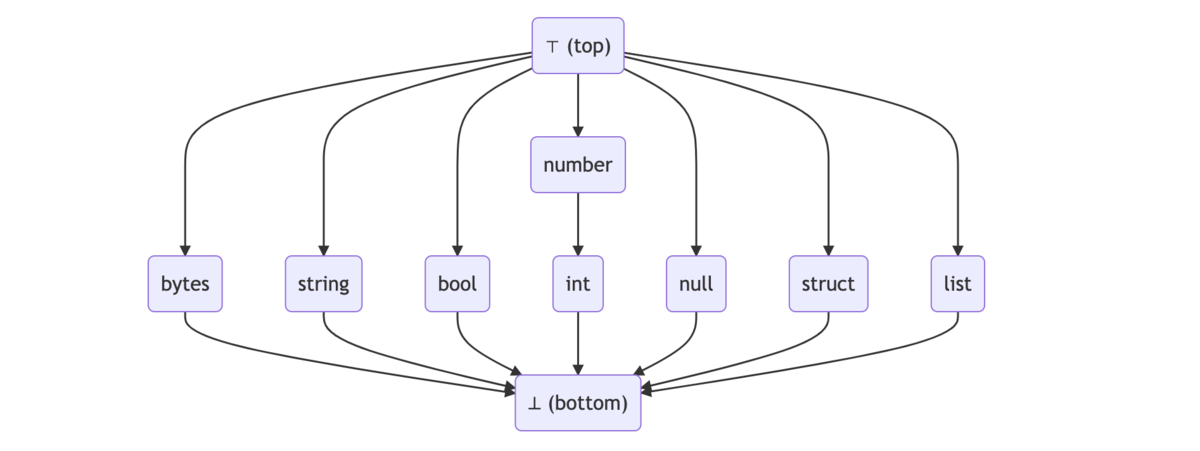
CUE ではスキーマもデータも lattice(束) として扱います。同じ key が現れるたびに交わり(∧、積)を取ることで評価します。
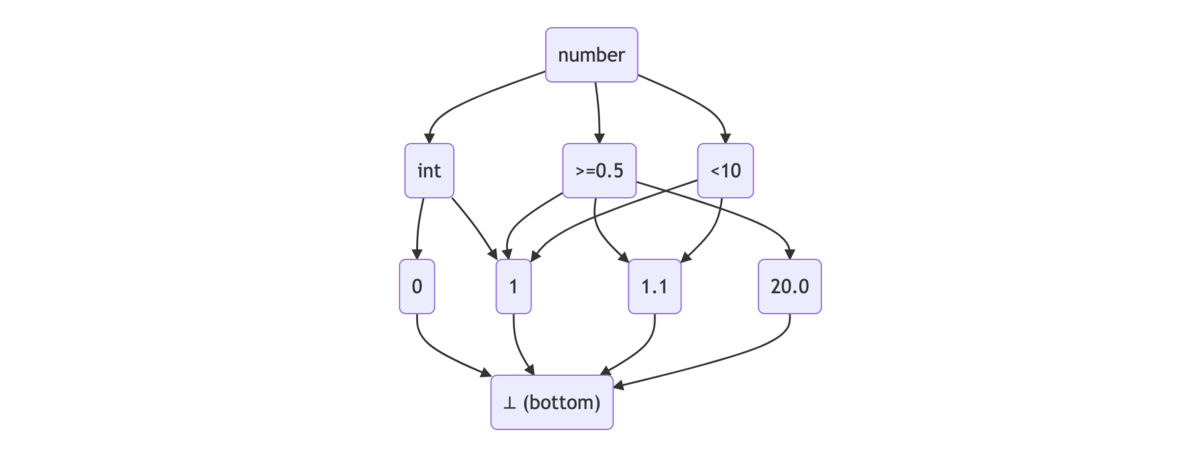
# ./valid.cue // スキーマ a: int // a: int 全体の集合 b: int // データ a: 1 // a: int 全体の集合 ∧ 1
$ cue eval valid.cue a: 1 b: int
交わりが最小元(⊥)であることは validation 失敗を意味します。
# ./invalid.cue a: string a: 1
$ cue eval invalid.cue
a: conflicting values string and 1 (mismatched types string and int):
./a.cue:1:4
./a.cue:2:4
lattice の定義から 結び(∨、和)も存在し、集合の演算が可能です。発想がすごいですね。
スキーマとデータをlatticeとみなしてよいかについては、このブログが参考になります。
CUE の学び方
ドキュメントが少ない中、Cuetorials がわかりやすいです。
👇 をざっと流し読みして
1 . Cuetorials "Overview", "First Steps"
2 . 公式 "Language Specification"
コンセプトに戻り 👇
3 . 公式 "About"
4 . 公式 "The Logic of CUE"
package, attributes, open / closed の概念で詰まったら 👇
5 . 公式 "Modules, Packages, and Instances"
6 . Cuetorials "Attributes"
7 . Cuetorials "Open and Closedness"
最後に
8 . Curtorials "Useful Patterns"
の順がオススメ。
まとめ
CUE の良い点について改めて。
- 人間にとって読みやすく、
.yamlデータを直接 validate 可能 - 演算ができる
- 制約をカンタンに付け外しできる。JSON Schema のように エントリーポイントを量産する必要がない
参考
*1:「cue コマンドがたまたまそういう仕様」と区別しにくいのですが「CUE のコンセプトレベルでこれを狙っています」との記載があり、おそらく CUE 自体の仕様です。