プログラムから高速に経路ルックアップするアプローチ
やりたいこと
開発中のプログラム内で、高速に経路ルックアップしたい場合があります。
私の場合、いま直面しているのは「netflow なり sflow なりを収集するとき、collector 側で経路ルックアップして Origin AS を解決したい」です。
デフォルトルートや MPLS を利用しているなど、そもそも exporter (ルーター / スイッチ) が必要な経路情報を持っていない場合があるためです。
TL; DR
- ホスト内に gobgpd が動いているという前提で gRPC する、簡易実装でベンチマークした
- ruby クライアントでも、 6k ルックアップ/s くらいはいけそう
- たとえば go にしても劇的に速くはならない
- 速いとは言えないが、間に合うケースもある気がする
- gobgpd に gRPC する簡易実装で、これ以上はつらそう
2018-06-08 追記
アプローチ
考えられるアプローチは大きく2つ。
- collector プロセスがフルルートを持つ
- collector プロセスが、bgpd の経路をAPI でルックアップする
それぞれ pros/cons を考えてみます。
- ネットワーク遅延の観点から、フルルートは collector ホスト内に持っておきたい
- フルルートの注入は BGP が楽
というのは共通です。
1. collector プロセスがフルルートを持つ
collector プロセスが外部のルーター(図中の右ルーター)と BGP セッションを張り、自分自身でフルルートの RIB を持つアプローチです。

この場合、問題になりそうなのは collector プロセスのスケールアウトでしょう。collector は fluentd + fluent-plugin-netflow (or fluent-plugin-sflow) あるいは goflow + flow-pipeline を想定しますが、1 ホスト上に複数プロセス待ち受けたいです。
複数 collector プロセスが 各々 TCP ポートを分けつつ同じ外部ルーターとピアできるかというと、疑問があります。 *1 一回ソフトウェアルーターで経路受信するなど 工夫が必要でしょう。
別の問題として、RIB の実装があります。Patricia Trie が一般的ですが、これを自前でやる必要があります。
実装は複雑そうですが collector としては良いパフォーマンスが期待できます。
2. collector プロセスが、API 経由で経路ルックアップする
collector プロセスが、ホスト内で動作する bgpd の API を利用して経路ルックアップするアプローチです。
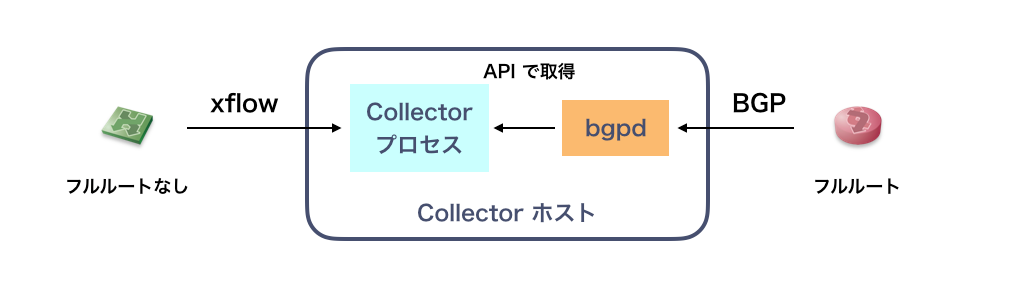
この場合、問題になりそうなのは bgpd の経路ルックアップパフォーマンスです。フルルートの注入に 10~20秒かかりそうなのはどちらのアプローチでも同じですが、bgpd の経路探索スピードは簡単にボトルネックになりえます。
一方で collector プロセスの実装はかなりシンプルになります。
まずトライするべきはこちらでしょうか。すごく高速に動く気はしませんが、十分なスピードで動いてくれる可能性はあります。
API で経路ルックアップできる bgpd (たとえば gobgpd)
まず思いつくのがgobgpd です。
今回は gobgpd に注目して、経路ルックアップのパフォーマンスを調査しますが… 「これもいけるらしいですよ」という実装がありましたら ぜひ教えてください!
ruby + gRPC で gobgpd 経路ルックアップ
collector として たとえば fluentd を利用する場合、ruby で gRPC することになります。
- MacBook Pro (Mid 2015) / Intel(R) Core(TM) i7-4980HQ CPU @ 2.80GHz
- ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-darwin16]
- grpc (1.12.0 universal-darwin)
- go1.10.2 darwin/amd64
- gobgpd v1.32
の環境で
$ gobgpd & $ gobgp global as 65000 router-id 10.0.0.1 listen-port 10179 $ wget http://archive.routeviews.org/route-views.wide/bgpdata/2018.06/RIBS/rib.20180604.0000.bz2 $ bunzip2 rib.20180604.0000.bz2 $ gobgp mrt inject global rib.20180604.0000
して
Table ipv4-unicast Destination: 704550, Path: 1394586
をロードし、以下の ruby クライアントから接続します。
$ gem install grpc-tools grpc
$ GOBGP_API=$GOPATH/src/github.com/osrg/gobgp/api
$ protoc -I $GOBGP_API --ruby_out=. --grpc_out=. --plugin=protoc-gen-grpc=`which grpc_tools_ruby_protoc_plugin` $GOBGP_API/gobgp.proto
$ bgpdump -M rib.20180604.0000 | grep 202.249.2.86 | awk -F \| 'NR%1000==0 { print $6 }' > routes
$ ruby -I. bench.rb
# bench.rb require 'benchmark' require 'ipaddr' require 'gobgp_pb' require 'gobgp_services_pb' def request(prefix) Gobgpapi::GetRibRequest.new( table: Gobgpapi::Table::new( family: Gobgpapi::Family::IPv4, destinations: [ Gobgpapi::Destination.new(prefix: prefix) ] ) ) end stub = Gobgpapi::GobgpApi::Stub.new('localhost:50051', :this_channel_is_insecure) stub.get_rib(request('1.1.1.1')) # The first call is super slow puts File.read('routes').split.map {|prefix| prefix = IPAddr.new(prefix).succ.to_s Benchmark.realtime { 10.times do stub.get_rib(request(prefix)) end } / 10 }.join(', ')
何をしているかというと、
- 1000 経路にひとつの割合で prefix をピックアップ
- prefix の先頭のアドレスについて、10回ルックアップ
- 平均の応答時間を出力
です。

横軸に prefix を並べていますが 値に意味はありません。「prefix が違っても応答時間はほぼ一定」という点がポイントです。gobgpd の RIB は単純な Hash であり、理屈は通っています。
さて、ここで気になるのは「longest match による経路ルックアップを、Hash でどのように実現しているか」ですね。たとえば 1.1.1.1 をルックアップした場合に 1.1.1.0/24 を返してほしい。
gobgpd (v1.32) では、若干力技の実装になっています。IPv4 であれば /32、/31、... のように prefix length を縮めながらマッチするまで探索します。RIB に存在する prefix そのものを探索した場合(赤) とRIB に存在しない longer prefix を探索した場合(緑) で特徴的な差があるのはこれが原因でしょう。
ここまでで、この環境なら ruby クライアントで 3~4k lookup/s くらいのパフォーマンスが期待できることがわかりました。
go + gRPC でgobgpd 経路ルックアップ
比較のために、go クライアントでも試してみます。goflow を利用する場合はおそらく go になるでしょう。
# bench.go package main import ( "github.com/osrg/gobgp/client" "os" "bufio" "github.com/osrg/gobgp/packet/bgp" "github.com/osrg/gobgp/table" ) func main() { client, _ := client.New("localhost:50051") fp, _ := os.Open("routes") scanner := bufio.NewScanner(fp) for scanner.Scan() { for i := 0; i < 10; i++ { client.GetRIB(bgp.RF_IPv4_UC, []*table.LookupPrefix{ &table.LookupPrefix{scanner.Text(), table.LOOKUP_EXACT}, }) } } }
$ go build bench.go $ time ./bench ./bench 0.81s user 0.76s system 112% cpu 1.399 total
これは 5k lookup/s くらいに相当しますが 劇的に高速になるわけではなさそうです。原因とししてはgRPC のオーバーヘッド、あるいは gobgpd 自身のパフォーマンスが考えられます。
一般に netflow / sflow には複数のフローエントリーが含まれ、さらに src ip address / dst ip address 双方を検索すると… 10 entries/flow としても flow packet あたり20回のルックアップが必要です。この場合 5k lookup/s = 250 pkt/s 程度であり、不安が残ります。
マルチスレッドで若干改善できるはず
ruby でも go でも遅いのですが、gRPC オーバーヘッドを考えるとマルチスレッド化することで改善が期待できるはずです。
たとえば ruby クライアントのスレッド数を 2 にすると
# bench.rb require 'benchmark' require 'ipaddr' require 'gobgp_pb' require 'gobgp_services_pb' require 'thread' def request(prefix) Gobgpapi::GetRibRequest.new( table: Gobgpapi::Table::new( family: Gobgpapi::Family::IPv4, destinations: [ Gobgpapi::Destination.new(prefix: prefix) ] ) ) end stub = Gobgpapi::GobgpApi::Stub.new('localhost:50051', :this_channel_is_insecure) stub.get_rib(request('1.1.1.1')) # The first call is super slow queue = Queue.new File.read('routes').split.each do |prefix| 10.times do queue << prefix end end puts Benchmark::CAPTION puts Benchmark::measure { threads = [] 2.times do threads << Thread.new { while !queue.empty? stub.get_rib(request(queue.pop)) end } end threads.each {|t| t.join} }
こんな感じなります。
1 スレッド
$ gobgp_performance $ ruby -I . bench.rb user system total real 0.877157 0.564896 1.442053 ( 1.707599)
2 スレッド
$ gobgp_performance $ ruby -I . bench.rb user system total real 1.139738 0.852233 1.991971 ( 1.258576)
若干ですが速くなっていますね。グラフにするとこんな感じ 👇 になります。

さらに ごくわずかですが処理をブロックしているスキマがありそうなので、ruby クライアント側で Origin AS をデコードしてみます。
def origin_as(table) path_attrs = table.table.destinations[0].paths.find {|p| p.best}.pattrs.map {|i| i.unpack('C*')} as_path = path_attrs.find {|a| a[1] == 2} case as_path[0] when 64 # 2 byte AS (as_path[-2] << 8) + as_path[-1] when 80 # 4 byte AS (as_path[-4] << 24) + (as_path[-3] << 16) + (as_path[-2] << 8) + as_path[-1] end end
クライアント側でデコードしているのは gRPC を待つ CPU 時間をデコードにあてたいからで、ruby でやっているのは FFI + GC を ruby <-> go 間で面倒みたくないためです。
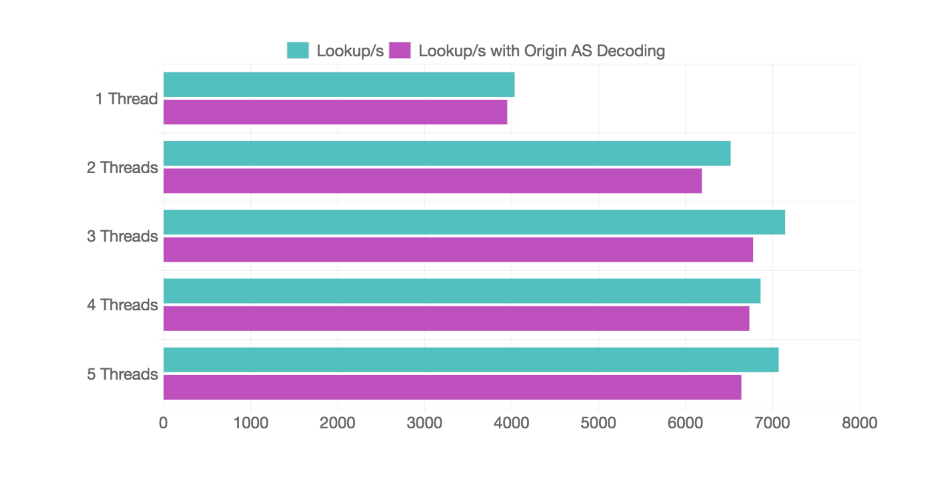
マルチスレッドにすることで、6k lookup/s くらいはいけそうです 🎉
まとめ
プログラムから経路ルックアップする場合のアプローチはいくつか考えられますが、簡易な実装で gobgpd を題材にベンチマークしてみました。
ruby クライアントであっても 6k lookup/s くらいのパフォーマンスは出そうですが、十分とは言えません。flow collector と一緒に使った場合、ここでつまる可能性があります。 しばらく運用してみて問題があったら RIB を内包するパターンの実装をトライする予定です。
また、実際の fluent plugin コード、flow-pipeline 向け kafka consumer は後日公開できるかもしれません。
2018-06-08 追記
tamihiro さんに「gobgpd の GetRib API、複数 prefix 渡せますよ」とご指摘いただき、再計測しました。
完全に見過ごしていた!

パラメーターが多くて見づらいのですが、1~5 スレッドごとに 8 本のバーチャートを引いてあり、上から順に
| gRPC あたりの prefix 数 | Origin AS デコード |
|---|---|
| 1 | ❌ |
| 1 | ⭕️ |
| 5 | ❌ |
| 5 | ⭕️ |
| 10 | ❌ |
| 10 | ⭕️ |
| 20 | ❌ |
| 20 | ⭕️ |
です。
- worker スレッドを増やしても さほど効果はないのは同じ
- gRPC あたりの prefix 数を増やす = gRPC 数を減らす と劇的にパフォーマンス改善する
- gobgpd の経路ルックアップというよりは、gRPC オーバーヘッドが効いていたと予想できる
- クライアントでOrigin AS デコードした場合、ある程度のところまではいくが頭打ちになる
という結果です。私には reasonable に見えます。
いずれにせよ、カンタンに 4~5倍 のスピードが手に入りました。🎉 ご指摘ありがとうございました!