RIB / FIB コンバージェンスを可視化する方法論
高価なテスターを使わず、なんとかRIB / FIB コンバージェンスを計測することを考えています。
コンバージェンスとは
ネットワークにBGP イベントが到着してから、さまざまな計算を行い、イベントを送信し、定常状態に落ち着くまでのプロセスをコンバージェンスと呼びます。
インターネットルーティングではその所要時間 = コンバージェンスタイムに注目しながら、ネットワークや経路の設計、パラメーターチューニングをします。
RIB コンバージェンスという場合、多くはBGP Update を受信してからのコンバージェンスを指します。
ルーターデバイス単体でみれば
1 . BGP Update を受信する
2 . Adj-RIB-In を更新する
3 . 受信フィルターを適用する
4 . Best Path を計算する
5 . Loc-RIB を更新する
6 . FIB を更新する
さらに、BGP Update を伝搬させるべき全てピアについて
7 . 送信フィルターを適用する
8 . Adj-RIB-Out を更新する
9 . BGP Update を送信する
このようなプロセスです。 1~6 を区別して「FIB コンバージェンス」と呼ぶことがあります。
原理的には 6 と 7~9 は並列処理可能ですが、パケットのループやブラックホールを避けるため、一般には 6 の完了を待って 7~9 を処理することが期待されます。
AS 単位 / インターネット全体でみると
一段マクロな視点では、AS にBGP イベントが到着してからAS 全体として処理するべきプロセスを完了することを BGP コンバージェンスと呼ぶことが多いです。インターネット全体でも同じです。
BGP イベント数について
RIB コンバージェンスという言葉のニュアンスには、イベント数の大小は含まれていません。「Prefix x.x.x.x/y のRIB コンバージェンス」「フルルートのRIB コンバージェンス」のように文脈によります。
「BGP コンバージェンス」の定義については、Informational なRFC4098、RFC7747 などにまとまっています。
なぜコンバージェンスに注目するのか
ネットワークとしてのインターネットを制御するのに、AS 運用者はピアをし、経路フィルターを更新します。これによってBGP イベントを発生 / 伝搬させるわけですが、最近はコンバージェンスタイムが予測しづらくなってきました。
AS 内部においては
L3 スイッチに代表されるマーチャントシリコン製品が増え、ネットワークとしてカスタムシリコンのような機敏な動きが期待できない場合があります。
フルルートを食えない製品はもちろんのこと、RIB / FIB のハードウェアコンフィグレーションの個体差が大きくなっていると感じます。FIB のLPM (Longest Prefix Match) / LEM (Largest Exact Match) の塩梅まで制御するような取り組みも見られます。
正直なところ、やってみないとわからない。とくに「IPv4 unicast は128k routes までですっ」という製品に、ミスってフルルート入っちゃった場合のRIB / FIB のふるまいなどは予測できません。
また、VM ベースのルーター製品を使うことも増えました。思わぬボトルネックが存在することがあり、ネットワークに組み込む際にはコンバージェンスを気にしておく必要があります。
このような製品が悪というわけではなくて、利用可能な通信技術とハードウェアとソフトウェアをつかって、CAPEX + OPEX を最小化しつつ、要件を満たすネットワークをつくるのがネットワークエンジニアの腕の見せどころなので、避けて通るわけにはいきません。
頭の弱い製品を使ったとしても ネットワークとして安定すればいいわけです。
AS 外 / インターネット全体として
AS 内部のコンバージェンスがうまくいったとしても、インターネット全体として最適でない場合があります。コンバージェンスタイムは短いことが正義ではなく、お隣さんの処理速度に合わせてイベントをフロー制御することが理想です。
コンバージェンスが速すぎてNeighbor ルーターで無駄にCPU リソースを使い、かえって遅くなることもありますし、保守的に長く取りすぎてパケットロスを引き起こす こともあります。
ここでのフォーカス
うまくフィードバックをいれつつ インターネット全体で、特に自分のAS近辺で最適化することがゴールですが、まずはデバイス単体のRIB / FIB コンバージェンス観測を目的とします。
RIB / FIB コンバージェンスを計測する方法論
RFC7747 を参考にします。
eBGP の場合は
+------------+ +-----------+ +-----------+
| | | | | |
| | | | | |
| HLP | | DUT | | Emulator |
| (AS-X) |--------| (AS-Y) |-----------| (AS-Z) |
| | | | | |
| | | | | |
| | | | | |
+------------+ +-----------+ +-----------+
| |
| |
+--------------------------------------------+
Figure 2: Three-Node Setup for eBGP and iBGP Convergence
(https://tools.ietf.org/html/rfc7747)
このようなセットアップを使い、
5.1.2. RIB-OUT Convergence
Objective:
This test measures the convergence time taken by an implementation
to receive, install, and advertise a route using BGP.
(https://tools.ietf.org/html/rfc7747)
を計測します。
EmulatorからrouteA向けのパケットをHLPに流すEmulatorからrouteAをDUTに広告するDUTはrouteAをHLPに広告する- (1 . のパケットが
DUTに届き)DUTはrouteA向けのパケットをEmulatorに転送する
3. - 2. を routeA のRIB コンバージェンス、4. - 2. をrouteA のFIB コンバージェンスとします。
フルルートについて言えば、
最後の経路の 3. - 最初の経路の 2. がRIB コンバージェンス、最後の経路の 4. - 最初の経路の 2. がFIB コンバージェンスです。
処理するべき経路数によってふるまいが変わる場合があるため、コンバージェンスタイムの値だけで評価するのではなく、
- 単位時間あたりに受信した経路数 (上の2. に対応)
- 単位時間あたりに広告した経路数 (上の3. に対応)
- 単位時間あたりにFIB インストールした経路数
の時間変化をプロットするのがよさそうです。
単位時間あたりにFIB インストールした経路数?
これを実現する妙案が浮かんでいません。ブラックボックステストで実現するべきなので「外部からパケットを入れて出てくるか確認する」アプローチなのは間違いありませんが、全アドレス空間宛てのパケットを常時生成するのは困難なため、
- BGP Update 直前か ほぼ同時に、該当Prefix に含まれるいくつかのアドレス宛てにパケットを送信
- DUT (Device Under Test) がフォワードするかを確認
おそらくこの形になります。
ただし、1. でどのアドレスを選択するべきかはLPM ベースなのか / LEM ベースなのかで異なりますし、100,000コ目の経路を処理した瞬間に1コ目の経路がRIB / FIB に存在するかも確認したほうがいいかもしれません。
今のところ、このあたりちょっとアイデアがありません。
デバイスのstats を取っておきたい
計測中、デバイスのCPU 使用率、メモリ / RIB / FIB 使用量などを同時取得しておくとよさそう。
実装
機敏に動き、API を備えるgobgp を中心に実装してみます。
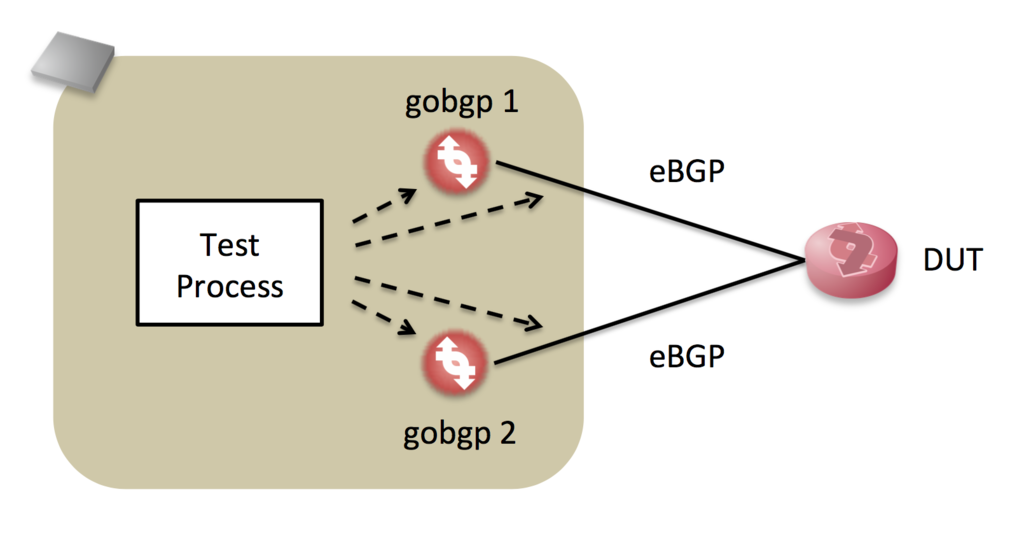
DUT で
- 新しい経路を受信した場合
- Best Path が変わった場合
- 経路がなくなった場合
それぞれ ふるまいが違う可能性があるため、次のようなシナリオでテストします。
gobgp 1からフルルートをDUTに送信gobgp 2からより強いフルルートをDUTに送信gobgp 2から2. のWithdraw をDUTに送信gobgp 1から1. のWithdraw をDUTに送信
2つのgobgp を制御して それぞれのシナリオに応じた経路を生成しつつ、それぞれの受信NLRI、送信NLRI を観測するプログラムを書きました。
経路は逐次生成ではなく、フルルートをロードしておいて送信ポリシーを reject → accept に変える、または accept → reject に変える、という方法で実装しています。
- gobgp 制御はgRPC でやる
- gobgp の動作を阻害したくないため、NLRI 観測にはlibpcap をつかう
- なるべくリアルタイムに処理し、将来的にはFIB コンバージェンス計測にパケットを生成するため、go で実装
- gobgp のgo APIとBGP パーサーを流用できるメリットもある
TCP を終端せず 観測者として動作させるためだけにTCP Reassemble を実装するのはアホらしいのですが、黙って実装します。
残念ながら、いまのところFIB コンバージェンスは計測できていません。
結果
このプログラムは上の4つのシナリオを順次実行し、結果をjson で保存します。
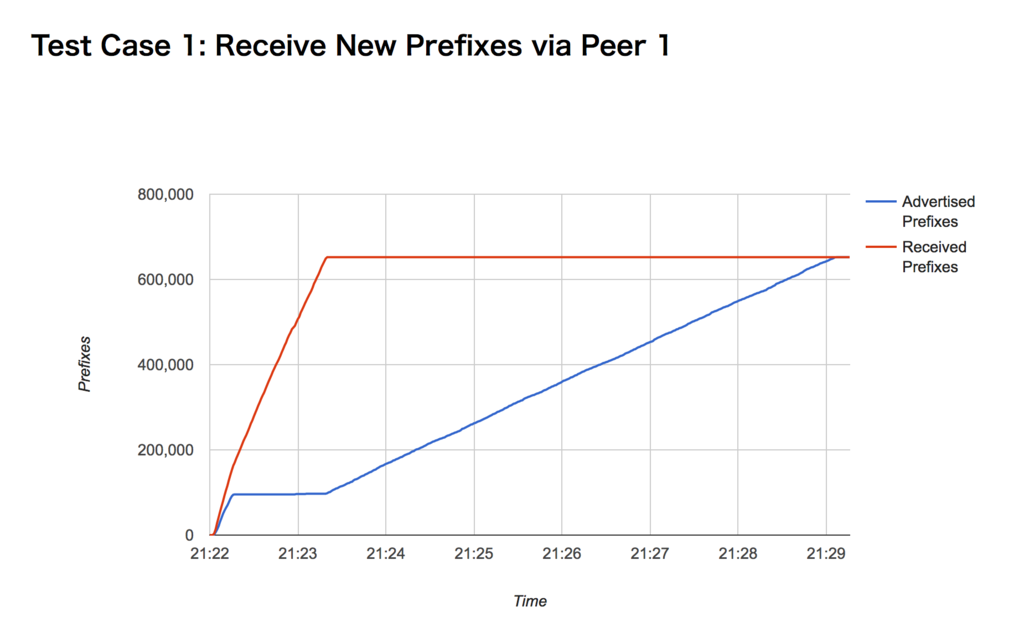
このチャートは あるVM ルーター製品のもので、毎秒の累積 送信/受信Prefix 数を描いています。テスト環境ではRIB コンバージェンスに7分かかることを示していて、経路数に対してほぼ線形であると予想できます。
コマンドラインオプションで経路数を指定できるので、実際に線形であるか確かめるシェルスクリプトも書けると思います。
余談ではありますが、この製品では、コンバージェンスまでの間CLI 上の送信経路数と実際の観測NLRI 数が大きく違っていました。
まとめ / これからやること
- 昨今のルーター製品、とくにL3 スイッチ製品のRIB コンバージェンスが予測できないため、ブラックボックステストを行う必要があると考えています
- その方法論について検討し、実装しました
- FIB コンバージェンス計測のためのアイデアがありません…コメントお待ちします!!
- gobgp がテストのボトルネックになる可能性があります。判断のヒントとなりそうな指標をチャートに載せるべきかもしれません