inet-henge が出力する SVG の変更点
TL; DR
問題: リンクラベルがノードの裏に回ってしまう
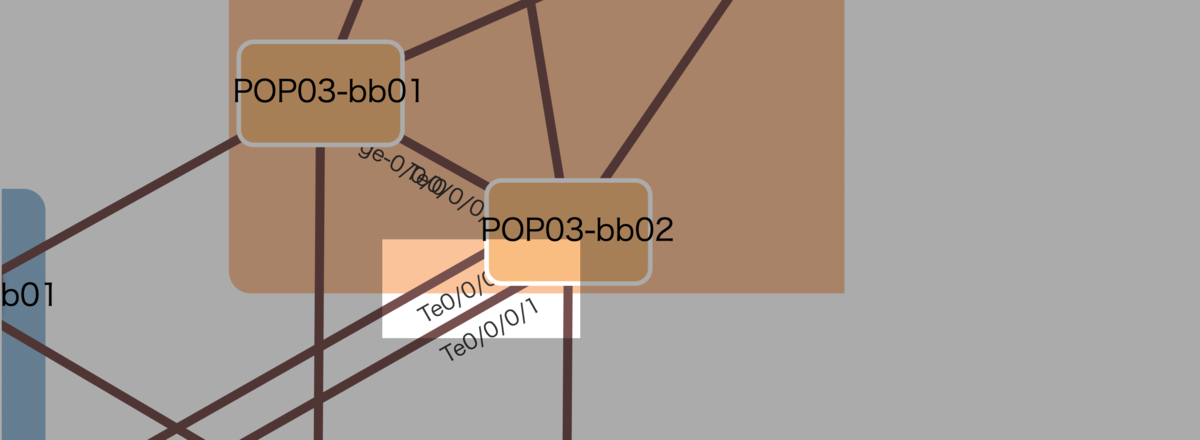
これまでのinet-hengeには、上のように「リンクラベルがノードの裏に回ってしまって読めない」問題がありました。
下の2点を満たすためにやむなくこうなっていたものです。
線をノードの裏に隠すために先に定義すると、リンクラベルは線にひきずられてノードの裏に回ってしまっていました。
解決策: リンクを 線レイヤー / ラベルレイヤー に分割する
次のような修正を入れました。
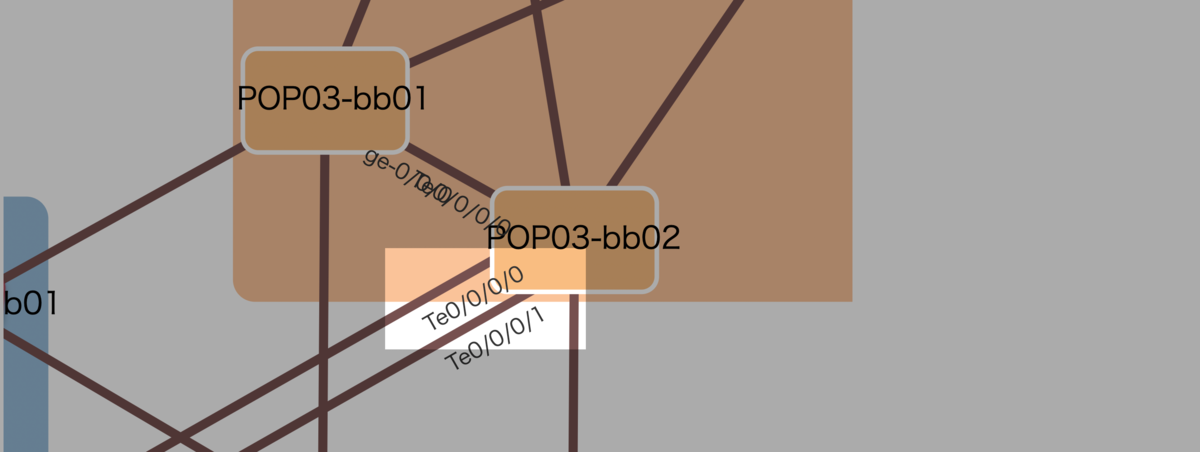
- リンク(線)
- ノード
- リンクラベル(テキスト)
の順に定義することで、リンクラベルだけをノードの表に描画します。SVGに z-index プロパティがないためこうするしかありませんが、
例: 線をポイントしたとき、ラベルを強調したい
のようなことをCSSで実現できなくなってしまいます。 この部分は後述します。
この修正により、inet-henge が出力する SVG DOM が変わっています。
CSS を適用している場合は、修正する必要があるかもしれません。
SVG DOM
参考までに、SVG DOM の変更点を抜粋します。
これまで
<svg width="960" height="600"> <g> <g transform="translate(-1339.7071035665983,-516.1007538206986) scale(3.4533582342976468)"> <rect width="9600" height="6000" transform="translate(-4800, -3000)" style="opacity: 0;"></rect> <!-- グループ定義 --> <g class="group pop03" transform="translate(462.13786327372185, 31.609395906680902)"> <rect rx="8" ry="8" width="224.02789064247673" height="218.51666231118884" style="fill: rgb(255, 127, 14);"></rect> <text>POP03</text> </g> <!-- リンク定義 --> <g class="path-group"> <line class="link pop03-bb01 pop03-bb02 pop03-bb01-pop03-bb02 " x1="493.13786327372185" y1="183.41381777944147" x2="574.8771135543029" y2="229.12605821786974" stroke="#7a4e4e" stroke-width="3" id="link2" transform="translate(0, 0)"></line> <path class="path" d="M 493.13786327372185 183.41381777944147 L 574.8771135543029 229.12605821786974" id="path2" transform="translate(0, 0)"></path> <text class="path-label" pointer-events="none" style="visibility: visible;" transform="rotate(0)"> <textPath xlink:href="#path2"> <tspan x="20" dy="1.5em" class="interface">ge-0/0/0</tspan> </textPath> </text> <text class="path-label" pointer-events="none" style="visibility: visible;" transform="rotate(0)"> <textPath xlink:href="#path2" class="reverse" text-anchor="end" startOffset="100%"> <tspan x="-20" dy="1.5em" class="interface">Te0/0/0/0</tspan> </textPath> </text> </g> <!-- ノード定義 --> <g id="pop03-bb02" name="POP03-bb02" transform="translate(547.8771135543029, 212.12605821786974)" class="node rect pop03-bb02 "> <rect width="54" height="34" rx="5" ry="5" style="fill: rgb(255, 187, 120);"></rect> <text text-anchor="middle" x="30" y="20"> <tspan x="30">POP03-bb02</tspan> </text> </g> ... </g> </g> </svg>
<line> 要素と <text> 要素が隣接していたため、CSSによる操作が簡単でした。
/* リンクにマウスオーバーしたとき、対応するラベルを操作 */ .link:hover ~ .path-label { ... }
これから
<svg width="960" height="600"> <g> <g transform="translate(-1336.8725605988434,-477.80660514393185) scale(3.448574180070414)"> <rect width="9600" height="6000" transform="translate(-4800, -3000)" style="opacity: 0;"></rect> <!-- グループ定義 --> <g id="groups"> ... <g class="group pop03" transform="translate(462.13786327372185, 31.609395906680902)"> <rect rx="8" ry="8" width="224.02789064247673" height="218.51666231118884" style="fill: rgb(255, 127, 14);"></rect> <text>POP03</text> </g> </g> <!-- リンク定義 --> <g id="links"> ... <g class="link pop03-bb01 pop03-bb02 pop03-bb01-pop03-bb02 "> <line x1="493.13786327372185" y1="183.41381777944147" x2="574.8771135543029" y2="229.12605821786974" stroke="#7a4e4e" stroke-width="3" id="link2" transform="translate(0, 0)"></line> <path d="M 493.13786327372185 183.41381777944147 L 574.8771135543029 229.12605821786974" id="path2" transform="translate(0, 0)"></path> </g> ... </g> <!-- ノード定義 --> <g id="nodes"> ... <g id="pop03-bb02" name="POP03-bb02" transform="translate(547.8771135543029, 212.12605821786974)" class="node rect pop03-bb02 "> <rect width="54" height="34" rx="5" ry="5" style="fill: rgb(255, 187, 120);"></rect> <text text-anchor="middle" x="30" y="20"> <tspan x="30">POP03-bb02</tspan> </text> </g> ... </g> <!-- リンクラベル定義 --> <g id="link-labels"> ... <g class="link pop03-bb01 pop03-bb02 pop03-bb01-pop03-bb02 "> <text class="path2" transform="rotate(0)" style="visibility: visible;"> <textPath xlink:href="#path2"> <tspan x="20" dy="1.5em" class="interface">ge-0/0/0</tspan> </textPath> </text> <text class="path2" transform="rotate(0)" style="visibility: visible;"> <textPath xlink:href="#path2" class="reverse" text-anchor="end" startOffset="100%"> <tspan x="-20" dy="1.5em" class="interface">Te0/0/0/0</tspan> </textPath> </text> </g> ... </g> </g> </g> </svg>
リンク側 <path id="path2"> とラベル側 <text class="path2"> を対応させています。 ひとつの <text/> に複数 <line/> というケースがあるため、<text/> に対応するのはあくまで <path/> です。
「個別のラベル(テキスト)がどのリンク(線)に対応するか」は表現できますが、「マウスオーバーした線に対応するラベルだけを操作」がCSSだけでは実現できなくなります。
inet-henge に入れたハック
上記の対処のため、線にマウスオーバーした場合は対応するリンクラベル要素に hover クラスを付与する処理を入れました。十分ではありませんが、とりあえず。
前述のCSSは、👇のように変えれば動きます。
/* リンクにマウスオーバーしたとき、対応するラベルを操作 */ .link text.hover { ... }
サンプル: http://inet-henge.herokuapp.com/issue09.html
また、リンク(線) のスタイルには .link ではなく .link line を、ラベルテキストのスタイルには .path-label ではなく .link text を使ってください。バージョンアップ後は、おそらく以前の.css ではうまく動かないと思います。
Versioning 始めました
SVG DOM が変更になることで、下位互換が崩れてしまいました 😢
互換性のない変更をいれたのはおそらく初めてのはずですが、いまさらながらCHANGELOG をきちんと書くために今後はVersion を振っていきます。
SVG の z-index property
2009年にProposalが出され、当初は、いまCandidate Recommendationまで進んでいるSVG2で入る予定であったようです。 History を辿ってみると、2018-08-07版 で省かれてしまっています。
当時の議論によれば、「重要なプロパティなのはわかるし、よくリクエストを貰うんだけど、render順 = 定義順 と仮定してしまってる既存コードをチェックして回るのが超大変。SVG2.1 でやるわ」ということのようでした。
z-index が入ればこのように泥臭いことをやらなくてよくなります。ぜひ欲しいですね! 楽しみに待ちたいと思います。
Vagrant Box の Juniper vQFX を、VMWare ESXi で起動するメモ
Juniper の vQFX10000 トライアル版 は community supported project として Vagrant で利用可能です。ただ VirtualBox provider のみのサポートであり、他ベンダーの VM と組み合わせてテストすることを考えると、ネットワーク設定が簡単な VMWare ESXi などで起動できると便利です。
設定を忘れて何度か試行錯誤してしまったため、メモしておきます。
本来はイメージを Juniper から直接入手すべきなのですが、
- 評価版をすんなりダウンロードできない。サポートに連絡しないといけない
- 面倒なので、Vagrant Cloud にあるバージョンで OK な場合は流用する
というだけの話です。
.vmdk のダウンロード
RE / PFE イメージをダウンロードします。
$ vagrant box add juniper/vqfx10k-re $ vagrant box add juniper/vqfx10k-pfe
少ないですがバージョン選択肢があって、
| box version | RE Junos version | PFE Junos version | Note |
|---|---|---|---|
| 0.4.0 | 19.4R1.10 | 19.4R1.10 | 2021-04-06 更新 |
| 0.3.0 | 17.4R1.16 | 17.4R1.16 | |
| 0.2.0 | 15.1X53-D63.9 | revoked | |
| 0.1.0 | 15.1X53-D60.4 | 15.1X53-D60.4 |
から選べます。
~/.vagrant.d/boxes/juniper-VAGRANTSLASH-vqfx10k-{re,pfe}/0.3.0/virtualbox/ に .vmdk が展開されます。同じ場所に VirtualBox 向け .ovf があり、これを参考にしつつ ESXi に設定する流れになります。
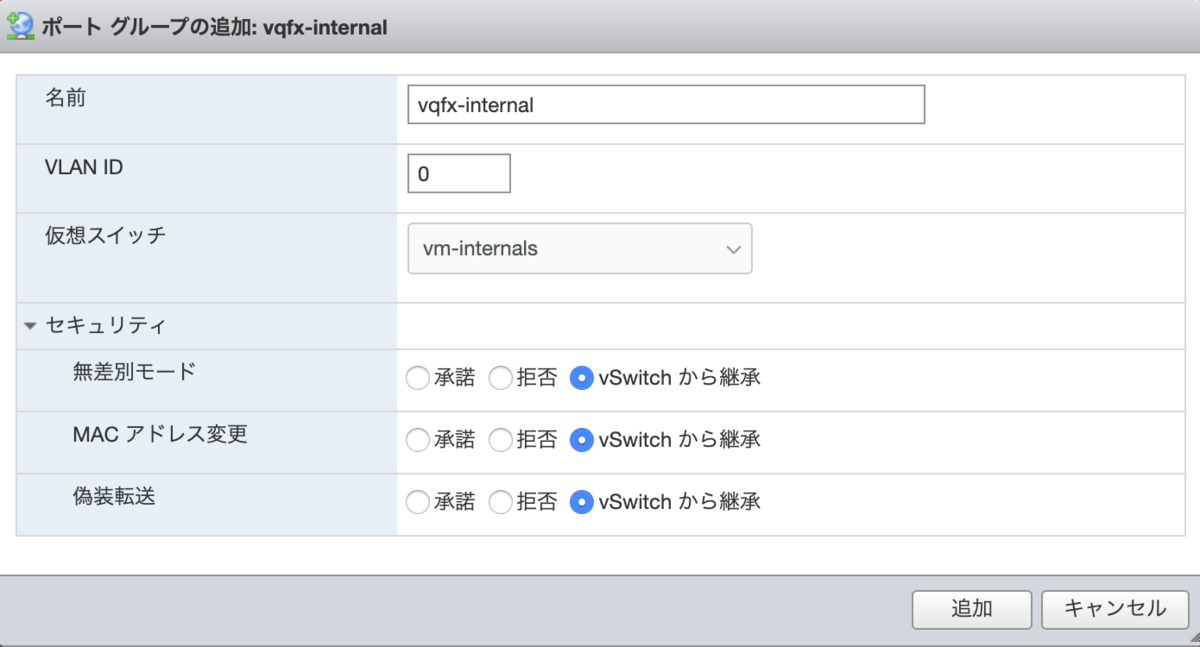
vSwitch / Port Group の作成
RE -- PFE 間で使う、内部接続の準備をします。
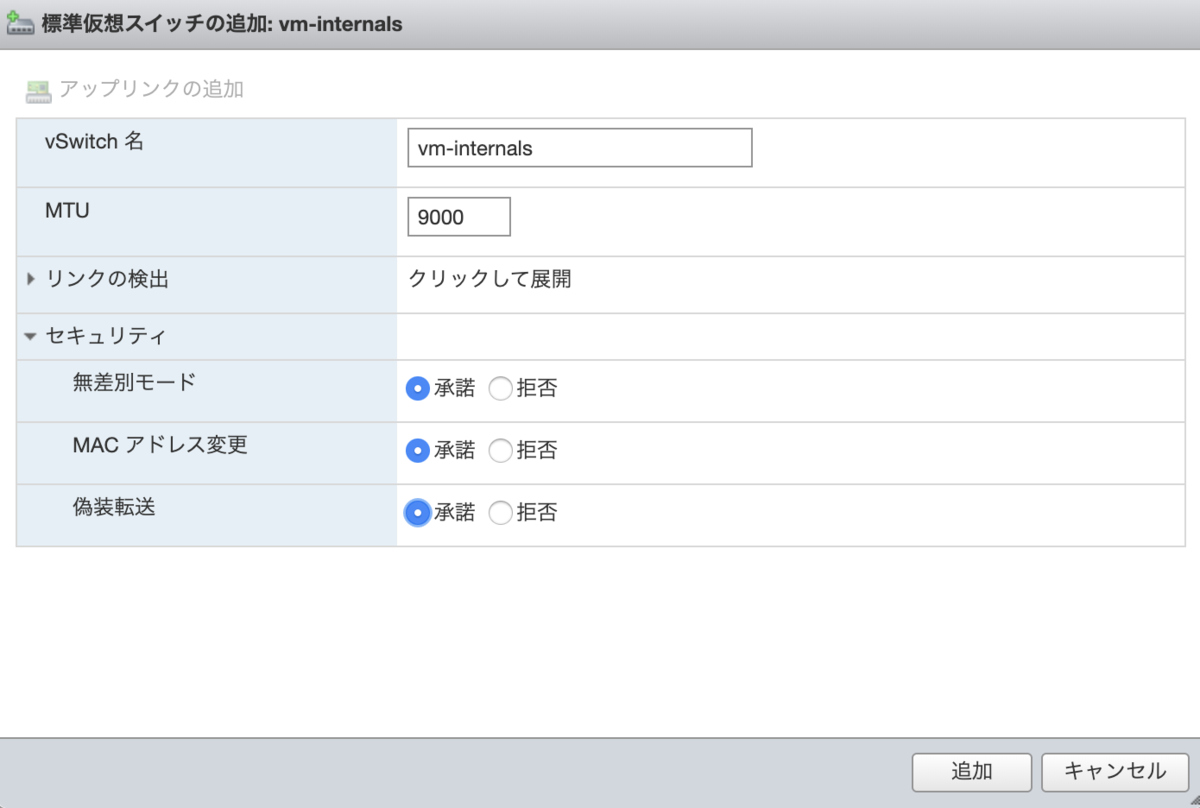
標準仮想スイッチの作成。VM 側で Mac Address をアサインできるよう、セキュリティポリシーを設定します。
| セキュリティ ポリシー | |
|---|---|
| 無差別モードを許可 | はい |
| 偽装転送を許可 | はい |
| MAC 変更を許可 | はい |
イメージのアップロード
後ほど vqfx-re / vqfx-pfe という名前で VM を作るとしてディレクトリーを作っておき、各々アップロードしておきます。
ディスク上にあまりファイルを書かないため さほど意味ないかもしれませんが、 thin provisiong に変換しつつイメージを置き換えます。
# ESXi にssh して [root@esxi:~] cd /vmfs/volumes/datastore1/vqfx-re [root@esxi:/vmfs/volumes/5d34e31a-944e599a-5f49-94c691ae50a2/vqfx-re] vmkfstools -i packer-virtualbox-ovf-1520879272-disk001.vmdk vqfx-re.vmdk -d thin [root@esxi:/vmfs/volumes/5d34e31a-944e599a-5f49-94c691ae50a2/vqfx-re] rm packer-virtualbox-ovf-1520879272-disk001.vmdk [root@esxi:/vmfs/volumes/5d34e31a-944e599a-5f49-94c691ae50a2/vqfx-re] cd ../vqfx-pfe/ [root@esxi:/vmfs/volumes/5d34e31a-944e599a-5f49-94c691ae50a2/vqfx-pfe] vmkfstools -i packer-virtualbox-ovf-1520878605-disk001.vmdk vqfx-pfe.vmdk -d thin [root@esxi:/vmfs/volumes/5d34e31a-944e599a-5f49-94c691ae50a2/vqfx-pfe] rm packer-virtualbox-ovf-1520878605-disk001.vmdk
VM の作成
RE VM
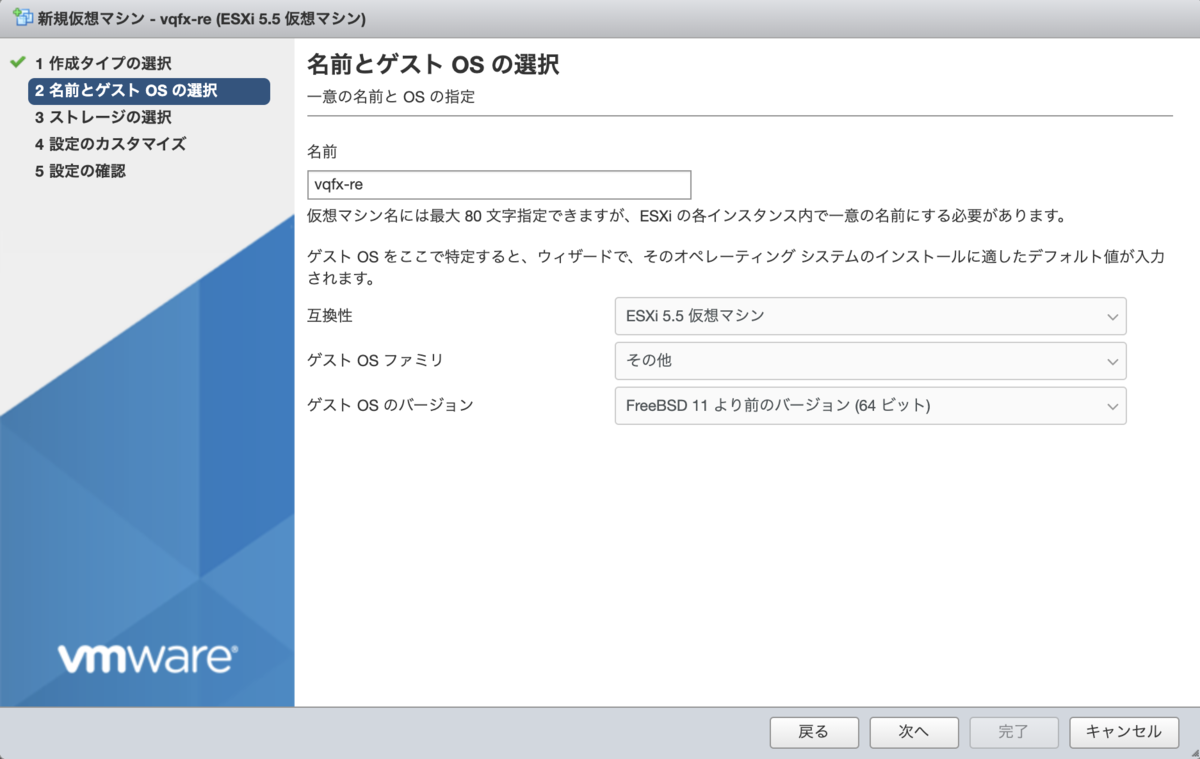
「新規仮想マシンの作成」を行います。
ESXi 5.5 仮想マシン ( virtualHW.version = "10" ) にする必要があることに注意してください。
| 設定 | |
|---|---|
| 互換性 | ESXi 5.5 仮想マシン |
| ゲスト OS ファミリ | その他 |
| ゲスト OS のバージョン | FreeBSD 11 より前のバージョン (64 ビット) |
一旦ストレージを追加しておいて…
後から削除、さきほどアップロードした .vmdk を新規追加します。
( 追加直後はシックプロビジョニングと表示されますが、一度起動すればシンプロビジョニングとして認識されます )
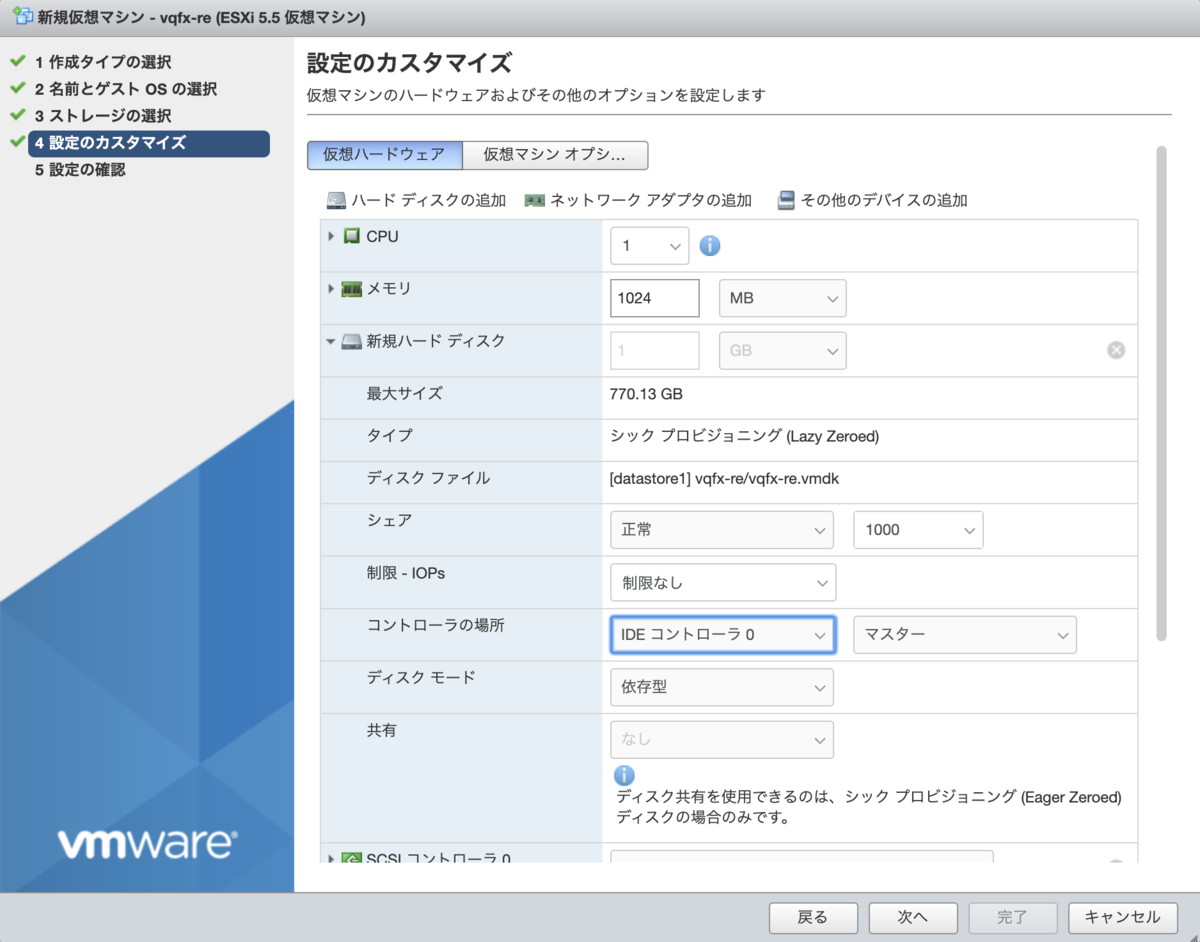
CPU やメモリ設定は .ovf のものを転記。
| 設定 | |
|---|---|
| CPU | 1 |
| メモリ | 1024MB |
| 新規ハードディスク コントローラの場所 | IDE コントローラ 0 マスター |
後からの NIC 追加が非常に面倒なため、必要分を先に作成します。
| 設定 | |
|---|---|
| アダプタタイプ | E1000 |
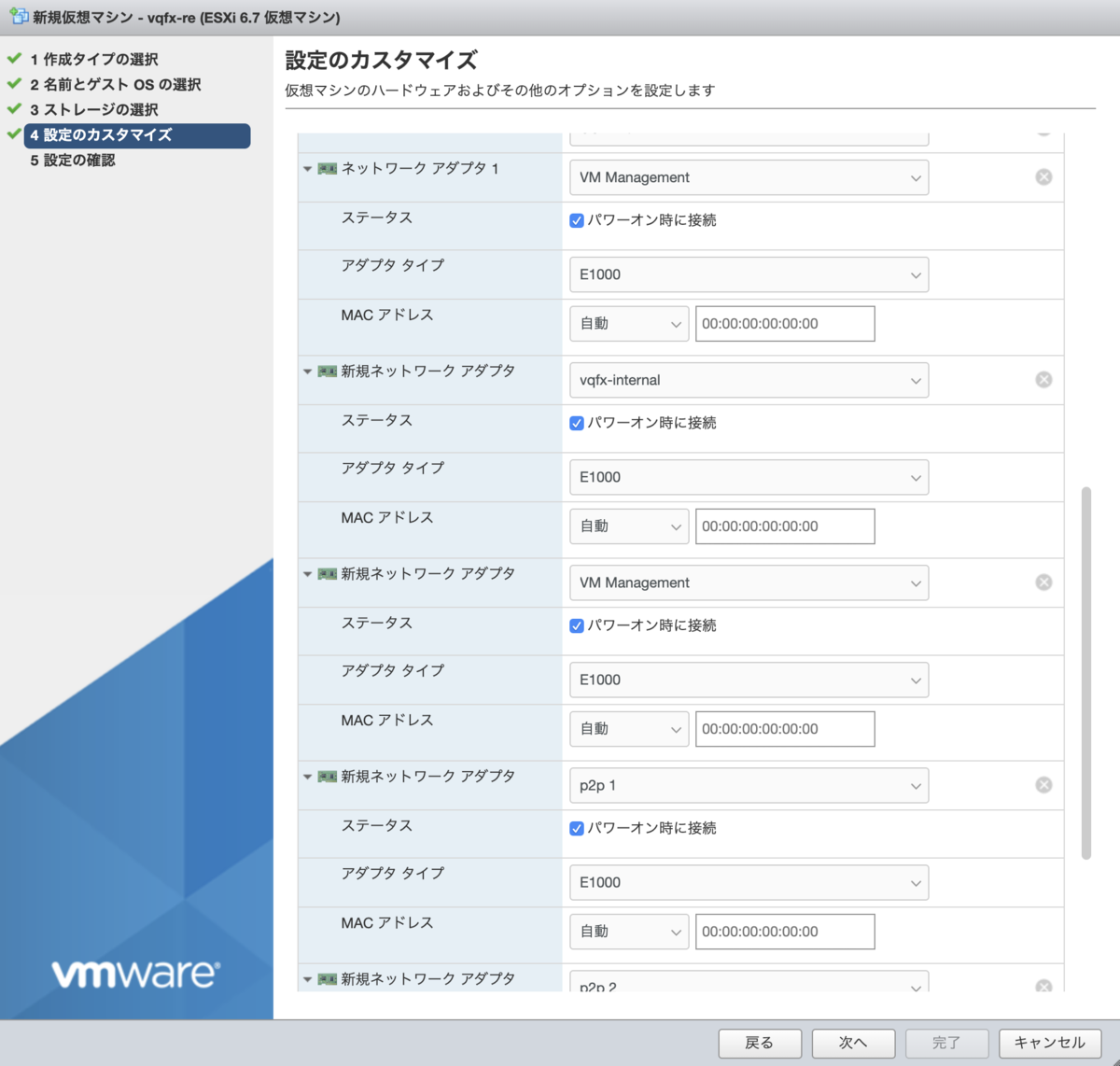
それぞれの NIC は、Junos 上からは上から順に 👇 のような対応になります。
- 上から 1つめ、3つめがマネージメントインターフェイス
- 上から 2つめが先ほど作成した RE--PFE 接続
xe-0/0/xは上から4 つめ以降
なことに注意してください。
| NIC # | Junos から見たInterface | メモ |
|---|---|---|
| 1 | em0 | マネージメント |
| 2 | em1 | RE--PFE間接続 |
| 3 | em2 | マネージメント |
| 4 | em3, xe-0/0/0 | 10GE インターフェイス |
| 5 | em4, xe-0/0/1 | 10GE インターフェイス |
| ... | ... | ... |
( RE 起動直後は em3 として認識した NIC が、PFE 接続後 xe-0/0/0 にマッピングされる )
PFE VM
こちらも「新規仮想マシンの作成」
| 設定 | |
|---|---|
| 互換性 | ESXi 5.5 仮想マシン |
| ゲスト OS ファミリ | LInux |
| ゲスト OS のバージョン | Ubuntu Linux (64 ビット) |
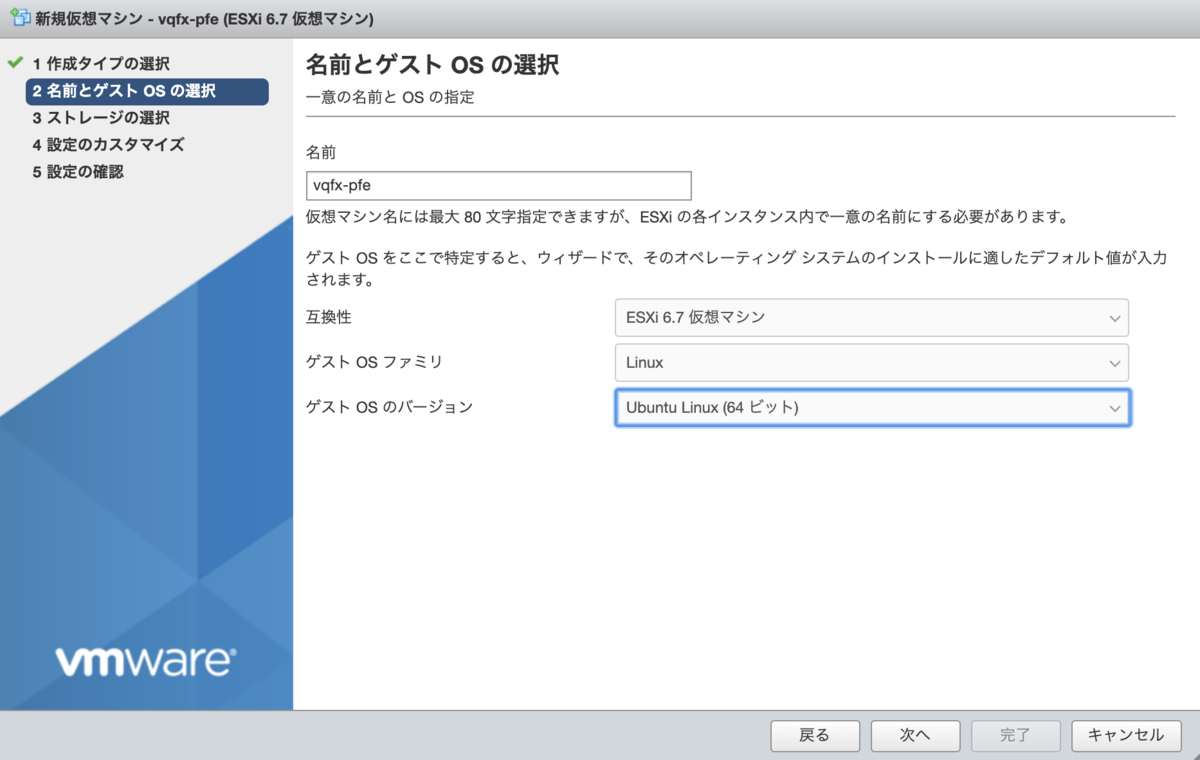
同じくディスクを追加しておいて削除、アップロードした .vmdk を新規追加します。
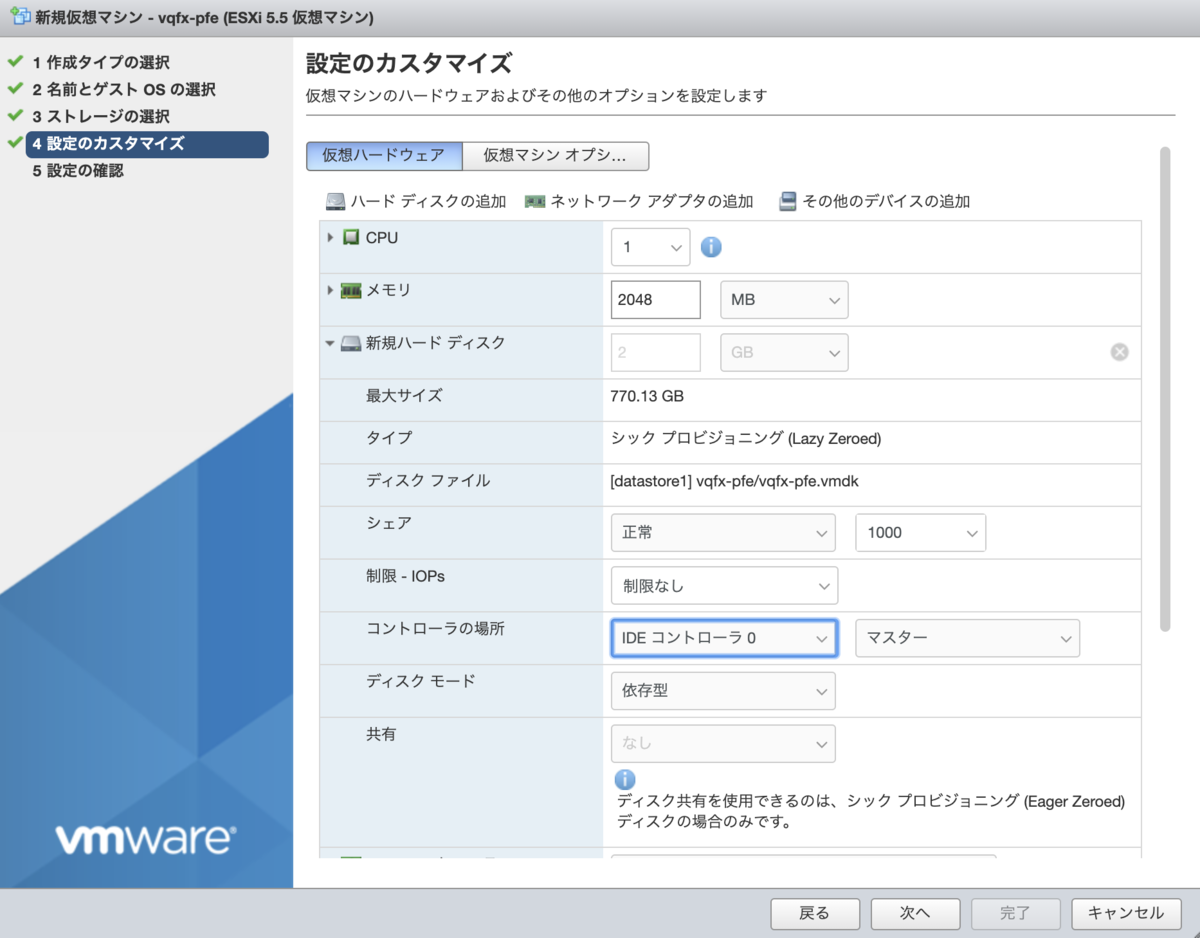
CPU やメモリ設定は .ovf のものを転記。
| 設定 | |
|---|---|
| CPU | 1 |
| メモリ | 2048MB |
| 新規ハードディスク コントローラの場所 | IDE コントローラ 0 マスター |
NIC は👇 のとおり。
| 設定 | |
|---|---|
| アダプタタイプ | E1000 |
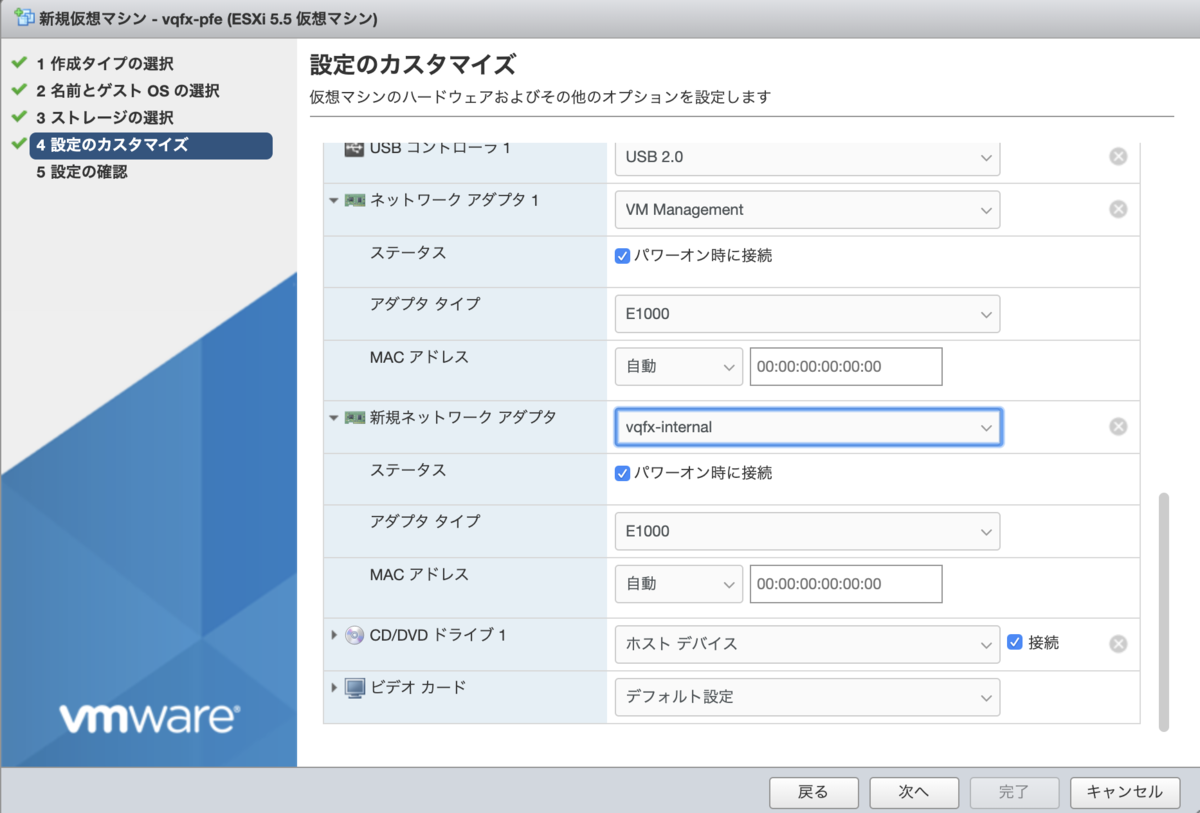
それぞれの NIC は、Junos 上からは上から順に 👇 のような対応になります。
| NIC # | Junos から見たInterface | メモ |
|---|---|---|
| 1 | em0 | マネージメント |
| 2 | em1 | RE--PFE間接続 |
起動
RE へのログイン情報: root / Juniper
ライセンスについて
"community supported project" とは何か調べてませんが、
- vQFX イメージ自体は Juniper がライセンスし、 Vagrant Cloud に公開している
- Vagrantfile は Apache License 2 として github にホストされ、 コミュニティでメンテしている
というふうに見えます。
1 の EULA には
k . Other Use Restrictions and Prohibitions. You > shall not, directly or indirectly: i. Decompile, disassemble or reverse engineer the Software or modify, change, unbundle, or create derivative works based on the Software, except as expressly permitted by applicable law without the possibility of contractual waiver.
のような条項がありますが、 .vmdk をそのまま使うぶんにはおそらく大丈夫だろうと思っています。
EVPN - VLAN Based と VLAN Aware Bundle の相互接続
TL; DR
EVPN は仕様が標準化され、Control / Data Plane が分離されているにも関わらず、Service Interface が異なる場合 ふつうは相互接続できません。 これがマルチベンダー EVPN を困難にする一因になっています。
この記事では Juniper vQFX (VLAN Aware Bundle) と vEOS (VLAN Based) 間で EVPN 接続し、実際に MAC 学習できないことを確認します。
それから、両者を橋渡しできるような Route Reflector を書くことで MAC 学習させ、通信させてみます。
EVPN とは
L2VPN を実現するプロトコルのひとつで、RFC7209 ( *1 ) で要件整理され、RFC7432 ( *2 ) で仕様策定されました。簡単に言うと、
Control Plane
Ethernet のMAC 情報をMP-BGP を使って伝搬させ、MAC 学習する
Data Plane
データであるEthernet フレームは、いろいろなトンネリングプロトコルによってカプセル (encapsulate) し、伝送する
というプロトコルです。 トンネリングプロトコルとセットにして、EVPN / MPLS や EVPN / VXLAN などと記載されることが多いと思います。
RFC7432 策定当時は EVPN / MPLS を前提としていて、VPLS の代替と位置付けられていましたが、オーバーレイの encapsulation は MPLS でなくても構いません。 RFC8365 ( *3 ) には、いくつかの encapsulation に関する記述があります。MPLS 同様よく使われているであろう VXLAN ( *4 ) を使う場合についてもこちらに定義されています。
マルチベンダーで EVPN 使いたい!
そもそも本当にマルチベンダーにしたいのかについては一考の余地があります。
- ベンダーを統一するとできることが増えるのでは?
- 単一API で機能を呼べることで、開発コストが減るのでは?
- スイッチとしてのハードウェアのふるまい、ソフトウェアのデザインが一致していることで運用コストが減るのでは?
- ...
いろんな理屈があって どれもそれはそうなんですが、「マルチベンダー」という選択肢が減るのは悪だと思っています。比較のうえ捨てるのは OK ですが、比較すらできないのはよくない。
さて、「マルチベンダーを考えましょう」という立場にたったとき、EVPN が標準化され Control / Data Plane が綺麗に分離されているにも関わらず、相互接続性に問題があります。
もっとも大きい問題が「Service Interface の相互接続性」です。
 ( 抜粋: マルチベンダ環境におけるEVPN構築のノウハウ~Interop Tokyo 2016 ShowNetでの相互接続検証を元に~ https://www.nic.ad.jp/ja/materials/iw/2016/proceedings/t05/t5-ohkubo.pdf )
( 抜粋: マルチベンダ環境におけるEVPN構築のノウハウ~Interop Tokyo 2016 ShowNetでの相互接続検証を元に~ https://www.nic.ad.jp/ja/materials/iw/2016/proceedings/t05/t5-ohkubo.pdf )
Service Interface については、こちらもInternet Week 2016 スライドがわかりやすいので抜粋しますが、
「ひとつの EVPN Instance (EVI) が何個のBridge Domain / Broadcast Domain (VLAN) をカバーするか」の分類を表します。
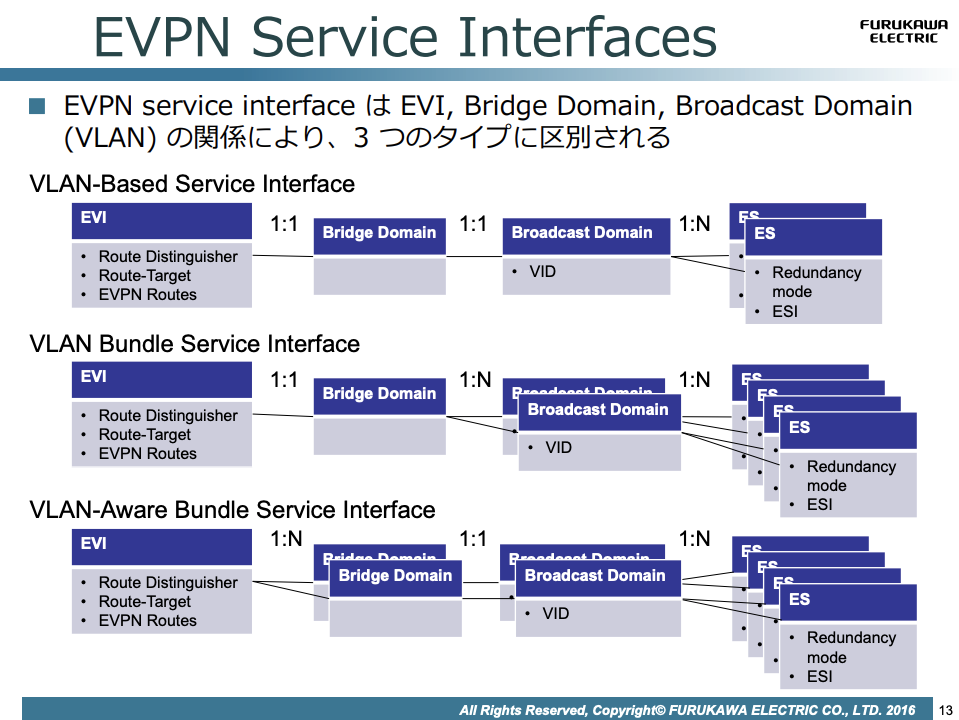 ( 抜粋: EVPN 技術紹介 https://www.nic.ad.jp/ja/materials/iw/2016/proceedings/t05/t5-kamitani-2.pdf )
( 抜粋: EVPN 技術紹介 https://www.nic.ad.jp/ja/materials/iw/2016/proceedings/t05/t5-kamitani-2.pdf )
Arista、Juniper MX など一部プラットフォームを除き、多くの機器でService Interfaceは実質固定です。 これは各NOSのEPVN Instance がどのようなテーブルを持っているか、ASIC / チップがどのような制約を持っているかによりますが、Service Interface が違うと相互接続できない点がマルチベンダーを困難にしています。
わたしが触る範囲では VLAN Based なプラットフォームが多いですが、そんなに多種多様な機器を触っているわけではないので…偏っているかもしれません。Juniper QFX など、よくみるプラットフォームで VLAN Aware Bundle なものはあります。 個人的には、VLAN Bundle に触れたことはありません。
ほんとうに相互接続できないか試す
- EVPN / VXLAN
- Juniper vQFX (VLAN Aware Bundle)
- Arista vEOS (VLAN Based 設定)
- Arista 自体は VLAN Aware Bundle いけますが、ここでは VLAN Based で設定
を 👇 のように接続し、Route Reflector 経由で EVPN BGP を張ります。
( わざわざ Control / Data Place を分けた理由は後述 )
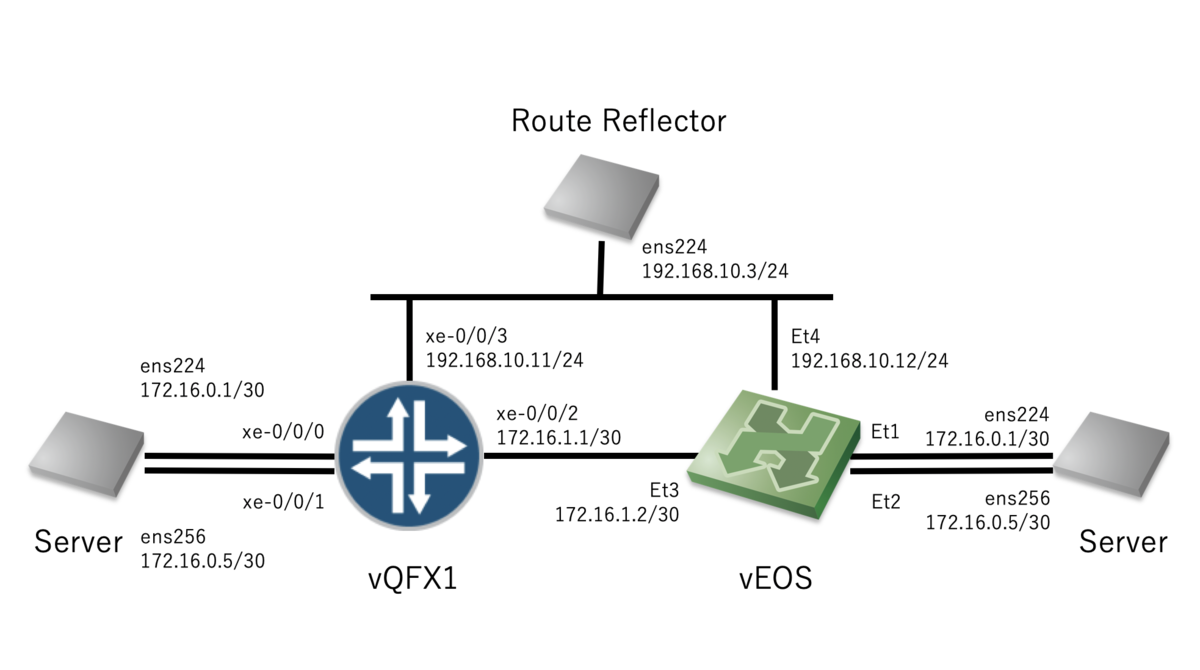
- IP アドレス記載のあるポートはL3、それ以外はL2 ポート
- vQFX xe-0/0/0 と vEOS Et1 は VLAN100 (VNI 1100) に所属
- vQFX xe-0/0/1 と vEOS Et2 は VLAN200 (VNI 1200) に所属
- vQFX config
- vEOS config
やはり通信できない
いくつかのコマンド結果を記載します。
vQFX 側は対向からの EVPN route type 2 ( MAC/IP )、route type 3 ( IMET ) を受信・解釈し、MAC 学習できているのに対し、vEOS 側は受信できているものの解釈・MAC 学習できていません。
vQFX
koji@vqfx1-re> show ethernet-switching table
MAC flags (S - static MAC, D - dynamic MAC, L - locally learned, P - Persistent static
SE - statistics enabled, NM - non configured MAC, R - remote PE MAC, O - ovsdb MAC)
Ethernet switching table : 4 entries, 4 learned
Routing instance : default-switch
Vlan MAC MAC Logical Active
name address flags interface source
vlan100 00:0c:29:88:49:aa D vtep.32769 10.0.0.2 # ← vEOS
vlan100 00:0c:29:fa:ac:f7 D xe-0/0/0.0
vlan200 00:0c:29:88:49:b4 D vtep.32769 10.0.0.2 # ← vEOS
vlan200 00:0c:29:fa:ac:01 D xe-0/0/1.0
koji@vqfx1-re> show route table default-switch.evpn.0 detail
default-switch.evpn.0: 8 destinations, 8 routes (8 active, 0 holddown, 0 hidden)
2:10.0.0.1:1::1100::00:0c:29:fa:ac:f7/304 MAC/IP (1 entry, 1 announced)
*EVPN Preference: 170
Next hop type: Indirect, Next hop index: 0
Address: 0xb4d8570
Next-hop reference count: 6
Protocol next hop: 10.0.0.1
Indirect next hop: 0x0 - INH Session ID: 0x0
State: <Active Int Ext>
Age: 6:36:18
Validation State: unverified
Task: default-switch-evpn
Announcement bits (1): 1-BGP_RT_Background
AS path: I
Communities: encapsulation:vxlan(0x8)
Route Label: 1100
ESI: 00:00:00:00:00:00:00:00:00:00
2:10.0.0.1:1::1200::00:0c:29:fa:ac:01/304 MAC/IP (1 entry, 1 announced)
*EVPN Preference: 170
Next hop type: Indirect, Next hop index: 0
Address: 0xb4d8570
Next-hop reference count: 6
Protocol next hop: 10.0.0.1
Indirect next hop: 0x0 - INH Session ID: 0x0
State: <Active Int Ext>
Age: 6:36:16
Validation State: unverified
Task: default-switch-evpn
Announcement bits (1): 1-BGP_RT_Background
AS path: I
Communities: encapsulation:vxlan(0x8)
Route Label: 1200
ESI: 00:00:00:00:00:00:00:00:00:00
2:10.0.0.2:1100::0::00:0c:29:88:49:aa/304 MAC/IP (1 entry, 1 announced)
*BGP Preference: 170/-101
Route Distinguisher: 10.0.0.2:1100
Next hop type: Indirect, Next hop index: 0
Address: 0xb4d8690
Next-hop reference count: 8
Source: 192.168.10.3
Protocol next hop: 10.0.0.2
Indirect next hop: 0x2 no-forward INH Session ID: 0x0
State: <Secondary Active Int Ext>
Local AS: 65000 Peer AS: 65000
Age: 2:13 Metric2: 11
Validation State: unverified
Task: BGP_65000.192.168.10.3
Announcement bits (1): 0-default-switch-evpn
AS path: I (Originator)
Cluster list: 192.168.10.3
Originator ID: 10.0.0.2
Communities: target:65000:1100 encapsulation:vxlan(0x8)
Import Accepted
Route Label: 1100
ESI: 00:00:00:00:00:00:00:00:00:00
Localpref: 100
Router ID: 192.168.10.3
Primary Routing Table bgp.evpn.0
2:10.0.0.2:1200::0::00:0c:29:88:49:b4/304 MAC/IP (1 entry, 1 announced)
*BGP Preference: 170/-101
Route Distinguisher: 10.0.0.2:1200
Next hop type: Indirect, Next hop index: 0
Address: 0xb4d8690
Next-hop reference count: 8
Source: 192.168.10.3
Protocol next hop: 10.0.0.2
Indirect next hop: 0x2 no-forward INH Session ID: 0x0
State: <Secondary Active Int Ext>
Local AS: 65000 Peer AS: 65000
Age: 2:02 Metric2: 11
Validation State: unverified
Task: BGP_65000.192.168.10.3
Announcement bits (1): 0-default-switch-evpn
AS path: I (Originator)
Cluster list: 192.168.10.3
Originator ID: 10.0.0.2
Communities: target:65000:1200 encapsulation:vxlan(0x8)
Import Accepted
Route Label: 1200
ESI: 00:00:00:00:00:00:00:00:00:00
Localpref: 100
Router ID: 192.168.10.3
Primary Routing Table bgp.evpn.0
3:10.0.0.1:1::1100::10.0.0.1/248 IM (1 entry, 1 announced)
*EVPN Preference: 170
Next hop type: Indirect, Next hop index: 0
Address: 0xb4d8570
Next-hop reference count: 6
Protocol next hop: 10.0.0.1
Indirect next hop: 0x0 - INH Session ID: 0x0
State: <Active Int Ext>
Age: 6:40:17
Validation State: unverified
Task: default-switch-evpn
Announcement bits (1): 1-BGP_RT_Background
AS path: I
Communities: encapsulation:vxlan(0x8)
Route Label: 1100
PMSI: Flags 0x0: Label 1100: Type INGRESS-REPLICATION 10.0.0.1
3:10.0.0.1:1::1200::10.0.0.1/248 IM (1 entry, 1 announced)
*EVPN Preference: 170
Next hop type: Indirect, Next hop index: 0
Address: 0xb4d8570
Next-hop reference count: 6
Protocol next hop: 10.0.0.1
Indirect next hop: 0x0 - INH Session ID: 0x0
State: <Active Int Ext>
Age: 6:40:17
Validation State: unverified
Task: default-switch-evpn
Announcement bits (1): 1-BGP_RT_Background
AS path: I
Communities: encapsulation:vxlan(0x8)
Route Label: 1200
PMSI: Flags 0x0: Label 1200: Type INGRESS-REPLICATION 10.0.0.1
3:10.0.0.2:1100::0::10.0.0.2/248 IM (1 entry, 1 announced)
*BGP Preference: 170/-101
Route Distinguisher: 10.0.0.2:1100
PMSI: Flags 0x0: Label 68: Type INGRESS-REPLICATION 10.0.0.2
Next hop type: Indirect, Next hop index: 0
Address: 0xb4d8690
Next-hop reference count: 8
Source: 192.168.10.3
Protocol next hop: 10.0.0.2
Indirect next hop: 0x2 no-forward INH Session ID: 0x0
State: <Secondary Active Int Ext>
Local AS: 65000 Peer AS: 65000
Age: 3:53 Metric2: 11
Validation State: unverified
Task: BGP_65000.192.168.10.3
Announcement bits (1): 0-default-switch-evpn
AS path: I (Originator)
Cluster list: 192.168.10.3
Originator ID: 10.0.0.2
Communities: target:65000:1100 encapsulation:vxlan(0x8)
Import Accepted
Localpref: 100
Router ID: 192.168.10.3
Primary Routing Table bgp.evpn.0
3:10.0.0.2:1200::0::10.0.0.2/248 IM (1 entry, 1 announced)
*BGP Preference: 170/-101
Route Distinguisher: 10.0.0.2:1200
PMSI: Flags 0x0: Label 75: Type INGRESS-REPLICATION 10.0.0.2
Next hop type: Indirect, Next hop index: 0
Address: 0xb4d8690
Next-hop reference count: 8
Source: 192.168.10.3
Protocol next hop: 10.0.0.2
Indirect next hop: 0x2 no-forward INH Session ID: 0x0
State: <Secondary Active Int Ext>
Local AS: 65000 Peer AS: 65000
Age: 3:53 Metric2: 11
Validation State: unverified
Task: BGP_65000.192.168.10.3
Announcement bits (1): 0-default-switch-evpn
AS path: I (Originator)
Cluster list: 192.168.10.3
Originator ID: 10.0.0.2
Communities: target:65000:1200 encapsulation:vxlan(0x8)
Import Accepted
Localpref: 100
Router ID: 192.168.10.3
Primary Routing Table bgp.evpn.0
vEOS
veos2#sh mac address-table
Mac Address Table
------------------------------------------------------------------
Vlan Mac Address Type Ports Moves Last Move
---- ----------- ---- ----- ----- ---------
100 000c.2988.49aa DYNAMIC Et1 1 0:00:44 ago
200 000c.2988.49b4 DYNAMIC Et2 1 0:00:33 ago
Total Mac Addresses for this criterion: 2
Multicast Mac Address Table
------------------------------------------------------------------
Vlan Mac Address Type Ports
---- ----------- ---- -----
Total Mac Addresses for this criterion: 0
veos2#sh bgp evpn detail
BGP routing table information for VRF default
Router identifier 10.0.0.2, local AS number 65000
BGP routing table entry for mac-ip 000c.2988.49aa, Route Distinguisher: 10.0.0.2:1100
Paths: 1 available
Local
- from - (0.0.0.0)
Origin IGP, metric -, localpref -, weight 0, valid, local, best
Extended Community: Route-Target-AS:65000:1100 TunnelEncap:tunnelTypeVxlan
VNI: 1100 ESI: 0000:0000:0000:0000:0000
BGP routing table entry for mac-ip 000c.2988.49b4, Route Distinguisher: 10.0.0.2:1200
Paths: 1 available
Local
- from - (0.0.0.0)
Origin IGP, metric -, localpref -, weight 0, valid, local, best
Extended Community: Route-Target-AS:65000:1200 TunnelEncap:tunnelTypeVxlan
VNI: 1200 ESI: 0000:0000:0000:0000:0000
BGP routing table entry for mac-ip 1100 000c.29fa.acf7, Route Distinguisher: 10.0.0.1:1
Paths: 1 available
Local
10.0.0.1 from 192.168.10.3 (192.168.10.3)
Origin IGP, metric -, localpref 100, weight 0, valid, internal, best
Originator: 10.0.0.1, Cluster list: 192.168.10.3
Extended Community: Route-Target-AS:65000:1100 TunnelEncap:tunnelTypeVxlan
VNI: 1100 ESI: 0000:0000:0000:0000:0000
BGP routing table entry for mac-ip 1200 000c.29fa.ac01, Route Distinguisher: 10.0.0.1:1
Paths: 1 available
Local
10.0.0.1 from 192.168.10.3 (192.168.10.3)
Origin IGP, metric -, localpref 100, weight 0, valid, internal, best
Originator: 10.0.0.1, Cluster list: 192.168.10.3
Extended Community: Route-Target-AS:65000:1200 TunnelEncap:tunnelTypeVxlan
VNI: 1200 ESI: 0000:0000:0000:0000:0000
BGP routing table entry for imet 10.0.0.2, Route Distinguisher: 10.0.0.2:1100
Paths: 1 available
Local
- from - (0.0.0.0)
Origin IGP, metric -, localpref -, weight 0, valid, local, best
Extended Community: Route-Target-AS:65000:1100 TunnelEncap:tunnelTypeVxlan
VNI: 1100
BGP routing table entry for imet 10.0.0.2, Route Distinguisher: 10.0.0.2:1200
Paths: 1 available
Local
- from - (0.0.0.0)
Origin IGP, metric -, localpref -, weight 0, valid, local, best
Extended Community: Route-Target-AS:65000:1200 TunnelEncap:tunnelTypeVxlan
VNI: 1200
BGP routing table entry for imet 1100 10.0.0.1, Route Distinguisher: 10.0.0.1:1
Paths: 1 available
Local
10.0.0.1 from 192.168.10.3 (192.168.10.3)
Origin IGP, metric -, localpref 100, weight 0, valid, internal, best
Originator: 10.0.0.1, Cluster list: 192.168.10.3
Extended Community: Route-Target-AS:65000:1100 TunnelEncap:tunnelTypeVxlan
VNI: 1100
BGP routing table entry for imet 1200 10.0.0.1, Route Distinguisher: 10.0.0.1:1
Paths: 1 available
Local
10.0.0.1 from 192.168.10.3 (192.168.10.3)
Origin IGP, metric -, localpref 100, weight 0, valid, internal, best
Originator: 10.0.0.1, Cluster list: 192.168.10.3
Extended Community: Route-Target-AS:65000:1200 TunnelEncap:tunnelTypeVxlan
VNI: 1200
BGP Update Message を覗く
それぞれの type 2 route のサンプルです。
EVPN route はすべて MP_REACH_NLRI にエンコードされます。
- Route Distinguisher
- Ethernet Tag ID
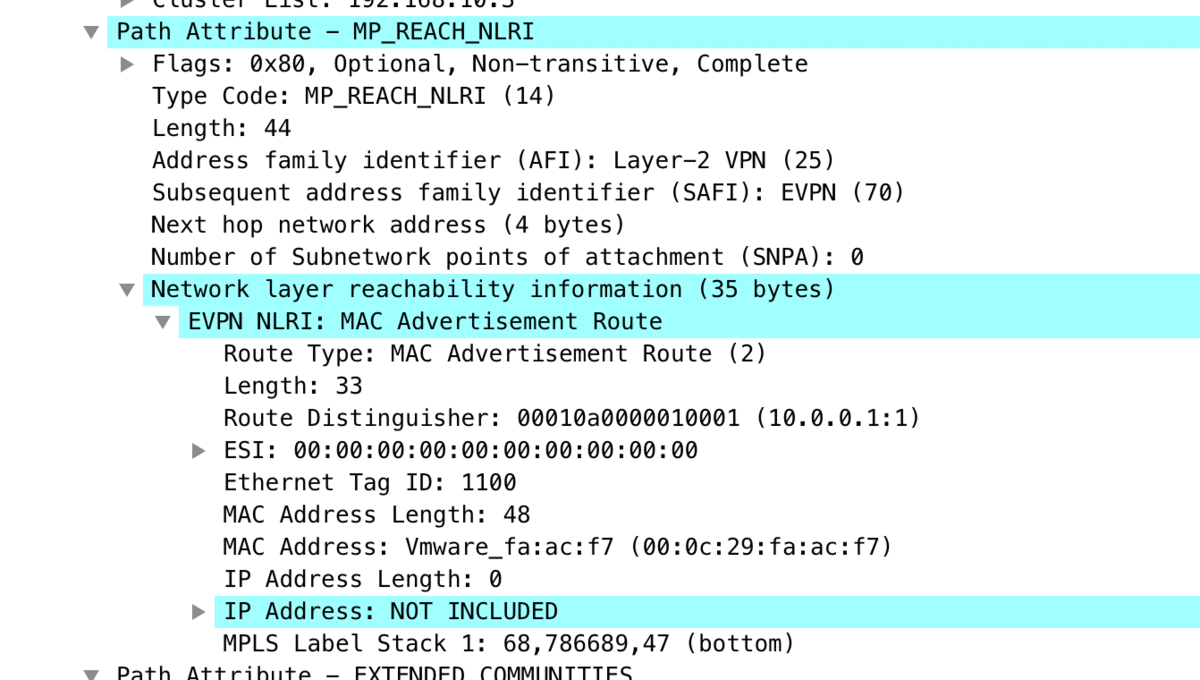
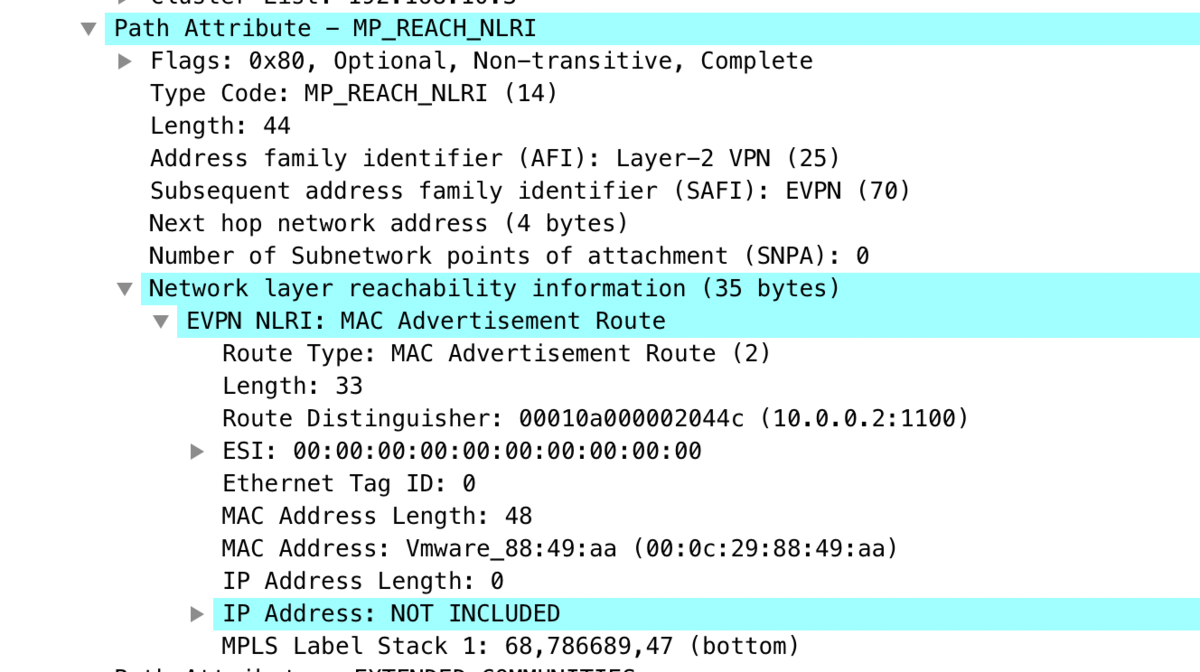
の値が微妙に違うのがわかるでしょうか。 両方 VNI 1100 の経路です。
vQFX (VLAN Aware Bundle) → vEOS (VLAN Based)
設定:
- VLAN Aware Bundle なので、 RD は VLAN (VNI) によらず
10.0.0.1:1(固定値)
vQFX (VLAN Aware Bundle) ← vEOS (VLAN Based)
設定:
MAC 学習させるには
今回の RD / VNI 番号設計に限った話ではありますが、
| Service Interface | RD | E-Tag ID |
|---|---|---|
| VLAN Aware Bundle | <VTEP endpoint address>:1 |
<VNI> |
| VLAN Based | <VTEP endpoint address>:<VNI> |
0 |
を相互に変換すればよさそうです。
RFC7432 によれば、
6.1. VLAN-Based Service Interface
... The Ethernet Tag ID in all EVPN routes MUST be set to 0.
6.3. VLAN-Aware Bundle Service Interface
... The Ethernet Tag ID in all EVPN routes MUST be set to the normalized Ethernet Tag ID assigned by the EVPN provider.
あるいは RFC8365 には、
For the VLAN-Aware Bundle Service (multiple VNIs per MAC-VRF with each VNI associated with its own bridge table), the Ethernet Tag field in the MAC Advertisement, Ethernet A-D per EVI, and IMET route MUST identify a bridge table within a MAC-VRF; the set of Ethernet Tags for that EVI needs to be configured consistently on all PEs within that EVI. For locally assigned VNIs, the value advertised in the Ethernet Tag field MUST be set to a VID just as in the VLAN-aware bundle service in [RFC7432]. Such setting must be done consistently on all PE devices participating in that EVI within a given domain. For global VNIs, the value advertised in the Ethernet Tag field SHOULD be set to a VNI as long as it matches the existing semantics of the Ethernet Tag, i.e., it identifies a bridge table within a MAC-VRF and the set of VNIs are configured consistently on each PE in that EVI.
という記述があり、確かにそれでよさそう。
経路変換するにあたり、RD、E-Tag ID は MP_REACH_NLRI なため、一般的な経路フィルターでは操作できません。 Route Reflector を書く必要がありそうです。
例として gobgpd ( *5 ) をカスタマイズし、
- BGP Neighbor ごとに VLAN Aware Bundle / VLAN Based の別を設定できる
- RIB には VLAN Aware Bundle の形で保持し、VLAN Based ピアには変換して広告する
ようにしてみます。
VXLAN Header 自体は 変数としてVNI しか持たないため、Control Plane だけの変換ですむはず。
通信できた 🎉
パッチを一部 掲載しますが、
# pkg/server/server.go 1022 func (s *BgpServer) processOutgoingPaths(peer *peer, paths, olds []*table.Path) []*table.Path { ... 1029 for idx, path := range paths { 1030 var old *table.Path 1031 if olds != nil { 1032 old = olds[idx] 1033 } 1034 if p := s.filterpath(peer, path, old); p != nil { 1035 // Hack 1036 if !peer.fsm.pConf.Config.VlanAwareBundle { 1037 if p != nil && p.GetRouteFamily() == bgp.RF_EVPN { 1038 nlri := p.GetNlri().(*bgp.EVPNNLRI) 1039 1040 switch nlri.RouteType { ... 1057 case bgp.EVPN_ROUTE_TYPE_MAC_IP_ADVERTISEMENT: 1058 route := nlri.RouteTypeData.(*bgp.EVPNMacIPAdvertisementRoute) 1059 1060 // For VLAN based router, RD needs to vary, otherwise only one route will be active per RD 1061 rd := route.RD.(*bgp.RouteDistinguisherIPAddressAS) 1062 rd.Assigned = uint16(route.ETag) // E-Tag ID をRD 下位16bit にコピー 1063 1064 new := &bgp.EVPNMacIPAdvertisementRoute{ 1065 RD: rd, 1066 ESI: route.ESI, 1067 ETag: 0, // 0 で上書き 1068 MacAddressLength: route.MacAddressLength, 1069 MacAddress: route.MacAddress, 1070 IPAddressLength: route.IPAddressLength, 1071 IPAddress: route.IPAddress, 1072 Labels: route.Labels, 1073 } 1074 1075 p = table.NewPath(p.GetSource(), bgp.NewEVPNNLRI(nlri.RouteType, new), ... 1154 func (s *BgpServer) propagateUpdate(peer *peer, pathList []*table.Path) { ... 1263 if path.GetRouteFamily() == bgp.RF_EVPN { 1264 nlri := path.GetNlri().(*bgp.EVPNNLRI) 1265 switch nlri.RouteType { ... 1269 case bgp.EVPN_ROUTE_TYPE_MAC_IP_ADVERTISEMENT: 1270 evpnRoute := nlri.RouteTypeData.(*bgp.EVPNMacIPAdvertisementRoute) 1271 if len(evpnRoute.Labels) > 0 { 1272 evpnRoute.ETag = evpnRoute.Labels[0] # MPLS Labels1 から転記 1273 }
さほど複雑ではありません。 これを使うと…さきほど MAC学習できていなかった vEOS 側で無事 MAC 学習できました!!
veos2#sh mac address-table
Mac Address Table
------------------------------------------------------------------
Vlan Mac Address Type Ports Moves Last Move
---- ----------- ---- ----- ----- ---------
100 000c.2988.49aa DYNAMIC Et1 1 0:05:17 ago
100 000c.29fa.acf7 DYNAMIC Vx1 1 0:00:21 ago
200 000c.2988.49b4 DYNAMIC Et2 1 0:05:06 ago
200 000c.29fa.ac01 DYNAMIC Vx1 1 0:00:21 ago
Total Mac Addresses for this criterion: 4
Multicast Mac Address Table
------------------------------------------------------------------
Vlan Mac Address Type Ports
---- ----------- ---- -----
Total Mac Addresses for this criterion: 0
EVPN Table のほうは、vEOS から見た diff です。
@@ -15,7 +15,7 @@ Origin IGP, metric -, localpref -, weight 0, valid, local, best Extended Community: Route-Target-AS:65000:1200 TunnelEncap:tunnelTypeVxlan VNI: 1200 ESI: 0000:0000:0000:0000:0000 -BGP routing table entry for mac-ip 1100 000c.29fa.acf7, Route Distinguisher: 10.0.0.1:1 +BGP routing table entry for mac-ip 000c.29fa.acf7, Route Distinguisher: 10.0.0.1:1100 Paths: 1 available Local 10.0.0.1 from 192.168.10.3 (192.168.10.3) @@ -23,7 +23,7 @@ Originator: 10.0.0.1, Cluster list: 192.168.10.3 Extended Community: Route-Target-AS:65000:1100 TunnelEncap:tunnelTypeVxlan VNI: 1100 ESI: 0000:0000:0000:0000:0000 -BGP routing table entry for mac-ip 1200 000c.29fa.ac01, Route Distinguisher: 10.0.0.1:1 +BGP routing table entry for mac-ip 000c.29fa.ac01, Route Distinguisher: 10.0.0.1:1200 Paths: 1 available Local 10.0.0.1 from 192.168.10.3 (192.168.10.3) @@ -45,7 +45,7 @@ Origin IGP, metric -, localpref -, weight 0, valid, local, best Extended Community: Route-Target-AS:65000:1200 TunnelEncap:tunnelTypeVxlan VNI: 1200 -BGP routing table entry for imet 1100 10.0.0.1, Route Distinguisher: 10.0.0.1:1 +BGP routing table entry for imet 10.0.0.1, Route Distinguisher: 10.0.0.1:1100 Paths: 1 available Local 10.0.0.1 from 192.168.10.3 (192.168.10.3) @@ -53,7 +53,7 @@ Originator: 10.0.0.1, Cluster list: 192.168.10.3 Extended Community: Route-Target-AS:65000:1100 TunnelEncap:tunnelTypeVxlan VNI: 1100 -BGP routing table entry for imet 1200 10.0.0.1, Route Distinguisher: 10.0.0.1:1 +BGP routing table entry for imet 10.0.0.1, Route Distinguisher: 10.0.0.1:1200 Paths: 1 available Local 10.0.0.1 from 192.168.10.3 (192.168.10.3)
まとめ & 考察
- EVPN Service Interface 間の相互接続は、Control Plane に手を加えるだけで達成できそうです。ただし、
- SDN コントローラーのような、Route Reflector としてふるまうコンポーネントでは、経路変換は実装・運用可能に見えます
- 一方、Spine-Leaf BGP EVPN な設計のところで Spine に手を入れられるかというと…難しい場合が多そう
- 単純なしくみで Control Plane を作れます。「相互接続は難しい」とされる理由について、他に何かありそうと感じます。
- なんだろう? Multihoming?
- そもそもマルチベンダーしたいかという点について、もちろん各社の方針はあるでしょう
EVPN、さほど詳しくありません。間違いがありましたら、バンバンご指摘いただけると嬉しいです!
*1:RFC7209: Requirements for Ethernet VPN (EVPN)
*2:RFC7432: BGP MPLS-Based Ethernet VPN
*3:RFC8365: A Network Virtualization Overlay Solution Using Ethernet VPN (EVPN)
*4:RFC7348: Virtual eXtensible Local Area Network (VXLAN): A Framework for Overlaying Virtualized Layer 2 Networks over Layer 3 Networks
設定ファイルエディターをつくる方へ
JANOG43 でライトニングトークしてきました
- NETCONF向けのコマンド(xml) とCLI向けのコマンド(text) が似ているため、XMLスキーマから抽象構文木が作れる
- 抽象構文木からエディターを作れる
- ためしにJunos向けの実装をしてみたが、他ベンダー向けもできるはず
簡単にいうと このような内容の発表をしてきました。
時間の関係で話せなかったことなどを、こちらにまとめておきます。
頂いた質問に答えます
いくつか質問を頂きました。ありがとうございます!
Q: オフラインでも使えますか?
A: 使えます。
発表ではこのような説明をしましたが、実際にはXMLスキーマを扱いやすい形 *1 に変換し、vscode拡張の中に同梱しています。ネットワーク機器との通信は不要で、オフラインでもOKです。
Q: XSDとYANG、どちらを使いました?
A: XSDを使いました。
詳しくは後述しますが、結果的にJunosではXSDを使ったものの、他でやるならまずYANGを試してみると思います。
設定ファイルエディターをつくる方へ
さて 本題ですが、あまりに誰得すぎて発表前に消したスライドがあります。実際にエディターを書く人向け。
せっかくなので、このスライドについて 補足します。

XSDとYANG、どちらを取るか
とりあえずはYANGがオススメです。
- 標準化されたフォーマットだから
- 抽象構文木を作成するにあたり、単一手法で複数プラットフォーム対応できる可能性がある
- パーサー実装があるから
- サイズが小さいから
- たとえばJUNOS 17.4 の場合、XSD 102MB に対して YANG は18MB しかありません。だいぶ楽
しかしながらJunosの場合、XSDのほうが便利そうだった
一番のポイントは、大量のメタデータが使えることでした。下は一例ですが、エディター実装時にはとても役立つ情報です。
<xsd:annotation> <xsd:documentation>Policy Name</xsd:documentation> <xsd:appinfo> <flag>mustquote</flag> <flag>identifier</flag> <flag>nokeyword</flag> <flag>current-product-support</flag> <regex-match deprecate="deprecate">^.{1,64}$</regex-match> <regex-match-error deprecate="deprecate">Must be string of 64 characters or less</regex-match-error> <match> <pattern>^.{1,64}$</pattern> <message>Must be string of 64 characters or less</message> </match> <identifier/> </xsd:appinfo> </xsd:annotation>
- それが識別子であるか、クォートが必要かどうか、など
- バリデーション失敗時のメッセージ
<xsd:annotation> <xsd:documentation>Source address filters</xsd:documentation> <xsd:appinfo> <flag>oneliner</flag> <flag>homogeneous</flag> <flag>autosort</flag>
<xsd:annotation> <xsd:documentation>List of captive portal content delivery rules</xsd:documentation> <xsd:appinfo> <flag>current-product-support</flag> <products> <product>mx960</product> <product>mx480</product> <product>mx240</product> <product>mx80</product> <product>mx80-48t</product> <product>mx5-t</product> <product>mx10-t</product> <product>mx40-t</product> <product>mx80-t</product> <product>mx80-p</product> <product>mx2020</product> <product>mx2010</product> <product>ex9204</product> <product>ex9208</product> <product>ex9214</product> <product>mx104</product> <product>vmx</product> <product>vrr</product> <product>mx2008</product> <product>mxtsr80</product> <product>mx10001</product> <product>mx10002</product> <product>ex9251</product> </products> </xsd:appinfo> </xsd:annotation>
- サポートするプラットフォーム一覧
一方、IOS-XR はYANGがよさそう
- メタ情報が少ない
- ファイル構造がほとんどYANGと同じ
このような理由で、もしIOS-XRでやるなら YANGを試すと思います。
NETCONFコマンドとCLIコマンドに差分がある場合の対応
Junosの場合 感覚的には「95% くらい同じ」と言えますが、やはり若干の差があります。
代表的なものは隠しコマンドの扱いです。XSD や YANG に隠しコマンドは記述されていません。
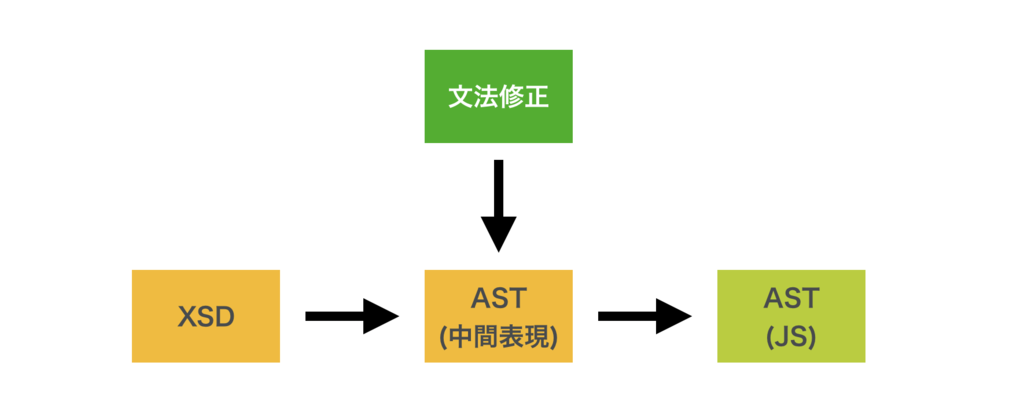
抽象構文木(AST) 生成元であるXSD / YANG は、ベンダーの都合で更新されます。それに引きずられることなく文法修正するために、一旦オレオレ記法で中間ファイルを作っておき、そこにパッチしていくと便利です。
XSDの場合には、大幅にサイズ削減できるという効果も狙っています。エディターに同梱するのは最終形態なので結果同じにはなりますが、開発中に何度もXSD本体をパースする必要はありません。
ライセンス
今回発表したやり方でいくと XSD / YANG をエディター処理系のデータ構造に変換し、エディターに同梱し、二次利用することになります。
問題ないことが多いとは思いますが、これがベンダーのライセンスに抵触するかどうかについて 確認しておくと安心です。
*1:JavaScriptで、巨大なObject
libwireshark のdissector を借りて、バイト列をパケットとしてデコードする
Wireshark という強力なプロトコルアナライザーがあります。多くのプロトコルをサポートし、「どんなパケットが流れているか分からないが、プロトコルスタックの深いところまで解析したい」場合には 非常に頼りになります。
この記事では、いくつかのプログラミング言語上のバイト列を libwireshark を使ってパケット解析してみます。
直面している問題
ネットワーク運用のために、sflow をきちんと解析したいと思っています。netflow では、ネットワークの制約により 欲しい統計が取れないことがあるためです。
- トラフィック制御のために、Q-in-Q、IPIP、GRE などのトンネルプロトコルの出番が増えた
- バックボーンを流れるときには、さらにMPLS ラベルやSegment Routing Header がつく
このようにプロトコルスタックが深い場合、高価なASICであったとしても ネットワークデバイスでデコードする前提のnetflow には限界があります。それより、単純に「先頭のNバイトをまるっとコピーしてexport し、コレクター側でなんとかする」というsflow アプローチのほうが、目的に合うこともあるでしょう。N は100~200B 程度なので、そこそこ上位レイヤーまで解析可能です。
sflow をきちんと解析したい別な理由として、マーチャントシリコンを搭載したスイッチ製品が普及し 単純にsflow を扱うケースが増えた、というのもあります。
具体的な問題の例
👇のデータを見てください。fluent-plugin-sflow を使って収集しているレコードのひとつです。
{ "datagram_source_ip": "192.168.0.2", "datagram_size": 220, "unix_seconds_utc": 1537117560, "datagram_version": 5, "agent_sub_id": 0, "agent": "169.254.0.2", "packet_sequence_no": 766, "sys_up_time": 4513318, "samples_in_packet": 1, "sample_type_tag": "0:1", "sample_type": "flow_sample", "sample_sequence_no": 1227, "source_id": "0:512", "mean_skip_count": 1, "sample_pool": 1228, "drop_events": 0, "input_port": 512, "output_port": 0, "flow_block_tag": "0:1001", "header_protocol": 1, "sampled_packet_size": 106, "stripped_bytes": 4, "header_len": 102, "header_bytes": "02-05-86-71-74-03-02-05-86-71-64-03-88-47-00-01-01-40-45-00-00-54-4A-95-00-00-40-01-AE-C0-C0-A8-00-02-C0-A8-00-01-08-00-B3-1D-40-0E-00-4D-5B-1D-85-C7-00-08-38-97-08-09-0A-0B-0C-0D-0E-0F-10-11-12-13-14-15-16-17-18-19-1A-1B-1C-1D-1E-1F-20-21-22-23-24-25-26-27-28-29-2A-2B-2C-2D-2E-2F-30-31-32-33-34-35-36-37", "dst_mac": "020586717403", "src_mac": "020586716403", "in_vlan": 0, "in_priority": 0, "out_vlan": 0, "out_priority": 0 }
Ethernet であることはわかりますが、それより上のレイヤーはデコードできていません。これでは何のことかぜんぜんわからない。
Wireshark 👇で見るとわかるように、実際はMPLS ラベルがついたICMP パケットです。

fluent-plugin-sflow は、sflow を策定しているInMon 公式のsFlow Tools を内包し、なるべく普及している方法でデコードを試みていますが、そのプログラムがMPLS に対応していません。
現実問題として あらゆるプロトコルスタックに対応するのは無理なのですが、Wireshark を使えばかなりイイ線いけそうではあります。
やってみる
現在のところ、残念ながらlibwireshark に「バイト列を受け取ってデコード結果を返す」というAPI がありません。Wireshark ファミリーのプログラム向けに、libpcap を用いて
- ファイル
- ネットワークインターフェイス
- パイプ
からバイト列を読むAPI があるだけです。
とはいうものの、libpcap の部分をすっ飛ばして「外から受け取ったバイト列をもつフレームをでっち上げる」ことは難しくなさそうです。
void rawshark_process_packet(uint8_t *data, int len, FILE *file) { guint32 cum_bytes = 0; gint64 data_offset = 0; frame_data fdata; epan_dissect_t *edt; // パケット解析器を初期化する cfile.epan = epan_new(); cfile.epan->get_frame_ts = raw_get_frame_ts; cfile.epan->get_interface_name = NULL; cfile.epan->get_interface_description = NULL; edt = epan_dissect_new(cfile.epan, TRUE, TRUE); // NIC やpcap ファイルからフレームを読み出す代わり、 // 外から受け取ったバイト列を持つフレームをでっち上げる struct wtap_pkthdr *whdr = g_malloc(sizeof(struct wtap_pkthdr)); whdr->rec_type = REC_TYPE_PACKET; whdr->pkt_encap = wtap_pcap_encap_to_wtap_encap(1); /* ETHERNET */ whdr->caplen = len; whdr->len = whdr->caplen; whdr->opt_comment = NULL; cfile.count++; frame_data_init(&fdata, cfile.count, whdr, data_offset, cum_bytes); frame_data_set_before_dissect(&fdata, &cfile.elapsed_time, &ref, prev_dis); if (ref == &fdata) { ref_frame = fdata; ref = &ref_frame; } // 解析する epan_dissect_run(edt, cfile.cd_t, whdr, frame_tvbuff_new(&fdata, data), &fdata, &cfile.cinfo); // フレームと解析器を解放し、結果を JSON で返す frame_data_destroy(&fdata); g_free(whdr); frame_data_set_after_dissect(&fdata, &cum_bytes); prev_dis_frame = fdata; prev_dis = &prev_dis_frame; prev_cap_frame = fdata; prev_cap = &prev_cap_frame; write_json_proto_tree(NULL, print_dissections_expanded, TRUE, NULL, PF_NONE, edt, file); epan_dissect_free(edt); edt = NULL; epan_free(cfile.epan); }
これを native extension 化すれば、たとえばfluentd 向けに「Ruby の世界のバイト列を C の世界にもっていってlibwireshark で解析し、Ruby の世界に戻す」ことが可能です。
Ruby + libwireshark
Ruby と C の橋渡し部分。
VALUE rb_rawshark_process_packet(VALUE self, VALUE data) {
uint8_t *raw = (uint8_t *) StringValuePtr(data);
int rawlen = (int) RSTRING_LEN(data);
VALUE json;
char *buf = NULL;
size_t buflen = 0;
FILE *out = open_memstream(&buf, &buflen);
rawshark_process_packet(raw, rawlen, out);
fclose(out);
if (buflen > 4) {
// NOTE: Truncate leading " ,\n"
json = rb_str_new2(buf + 4 * sizeof(char));
}
free(buf);
return json;
}
完全なサンプルは 👇にあります。
Ruby での利用例。
require 'wireshark' Wireshark.load raw = File.read(File.expand_path('../raw_frame', __FILE__)) puts Wireshark.dissect(raw) Wireshark.unload
Python + libwireshark
C の (uint8_t *) に持って来られればもとの言語はなんでもよく、たとえば Python であればCython をつかって
def dissect(data): cdef char *buf = NULL; cdef size_t buflen = 0; cdef FILE *out = open_memstream(&buf, &buflen) rawshark_process_packet(data, len(data), out) fclose(out) if buflen > 4: json = buf[4:buflen] free(buf) return json.decode()
のようにできます。
こちらも完全なサンプルは 👇。
Python での利用例
import os import wireshark base_dir = os.path.dirname(os.path.abspath(__file__)) with open(os.path.join(base_dir, 'raw_frame'), 'rb') as raw: wireshark.load() print(wireshark.dissect(raw.read())) wireshark.unload()
デコード結果
長くなるので掲載しませんが、なんとWireshark で見る相当のデータがJSON で手に入ります 🎉🎉🎉
もし興味があれば👇のgist をご覧ください。Ethernet Frame の奥のMPLS ラベルの奥のIP パケットの奥のICMP ヘッダが取れています。
Decoded sFlow data with libwireshark · GitHub
最後に、注意点をいくつか
libwireshark は遅い
libwireshark は非常に多くのプロトコルをサポートします。subdissector によって可能な限り再帰的に、上位レイヤーに向かってプロトコル解析するという動作のため、パフォーマンスは望めません。
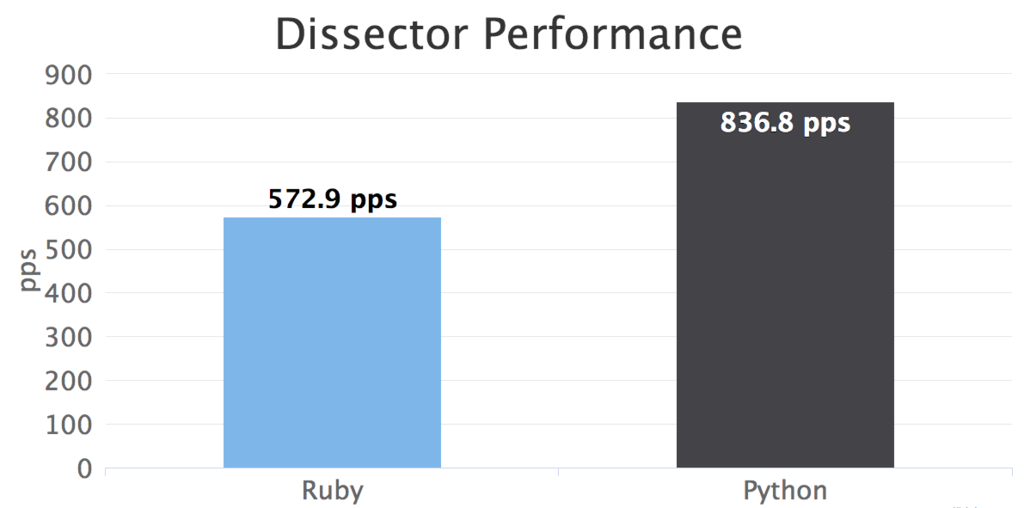
( 図: 先のMPLS ラベルつきICMP パケットの解析パフォーマンス )
ruby version: 2.5.1 python version: 3.6.5 compiler: GCC 7.3.0 platform: Linux-4.15.0-34-generic-x86_64-with-Ubuntu-18.04-bionic cpu model: Intel(R) Core(TM) i7-4980HQ CPU @ 2.80GHz # 2793.532 MHz
gprof 結果。libwireshark に実装されている、フレーム初期化部分が重そうなことがわかります。
% cumulative self self total time seconds seconds calls Ts/call Ts/call name 0.00 0.00 0.00 10000 0.00 0.00 frame_tvbuff_new 0.00 0.00 0.00 10000 0.00 0.00 rawshark_process_packet 0.00 0.00 0.00 1 0.00 0.00 cap_file_init 0.00 0.00 0.00 1 0.00 0.00 rawshark_clean 0.00 0.00 0.00 1 0.00 0.00 rawshark_init
もし「プロトコルスタックが固定で、高速にデコードしたい」「固定ではないが、最大でも3レイヤーデコードすればOK」のような場合は適さないかもしれません。
( libwireshark でも「3レイヤーまで」などの指定は可能かもしれませんが、未調査です )
libwireshark のライセンス
Wireshark は、GPL v2 です。これを動的リンクするプログラムもGPL v2 にする必要があります。
まとめ
Ruby や Python 向けに (もちろんその2つに限らずですが)、libwireshark をリンクした native extension を作っておくと便利です。
プログラムから高速に経路ルックアップするアプローチ
やりたいこと
開発中のプログラム内で、高速に経路ルックアップしたい場合があります。
私の場合、いま直面しているのは「netflow なり sflow なりを収集するとき、collector 側で経路ルックアップして Origin AS を解決したい」です。
デフォルトルートや MPLS を利用しているなど、そもそも exporter (ルーター / スイッチ) が必要な経路情報を持っていない場合があるためです。
TL; DR
- ホスト内に gobgpd が動いているという前提で gRPC する、簡易実装でベンチマークした
- ruby クライアントでも、 6k ルックアップ/s くらいはいけそう
- たとえば go にしても劇的に速くはならない
- 速いとは言えないが、間に合うケースもある気がする
- gobgpd に gRPC する簡易実装で、これ以上はつらそう
2018-06-08 追記
アプローチ
考えられるアプローチは大きく2つ。
- collector プロセスがフルルートを持つ
- collector プロセスが、bgpd の経路をAPI でルックアップする
それぞれ pros/cons を考えてみます。
- ネットワーク遅延の観点から、フルルートは collector ホスト内に持っておきたい
- フルルートの注入は BGP が楽
というのは共通です。
1. collector プロセスがフルルートを持つ
collector プロセスが外部のルーター(図中の右ルーター)と BGP セッションを張り、自分自身でフルルートの RIB を持つアプローチです。

この場合、問題になりそうなのは collector プロセスのスケールアウトでしょう。collector は fluentd + fluent-plugin-netflow (or fluent-plugin-sflow) あるいは goflow + flow-pipeline を想定しますが、1 ホスト上に複数プロセス待ち受けたいです。
複数 collector プロセスが 各々 TCP ポートを分けつつ同じ外部ルーターとピアできるかというと、疑問があります。 *1 一回ソフトウェアルーターで経路受信するなど 工夫が必要でしょう。
別の問題として、RIB の実装があります。Patricia Trie が一般的ですが、これを自前でやる必要があります。
実装は複雑そうですが collector としては良いパフォーマンスが期待できます。
2. collector プロセスが、API 経由で経路ルックアップする
collector プロセスが、ホスト内で動作する bgpd の API を利用して経路ルックアップするアプローチです。
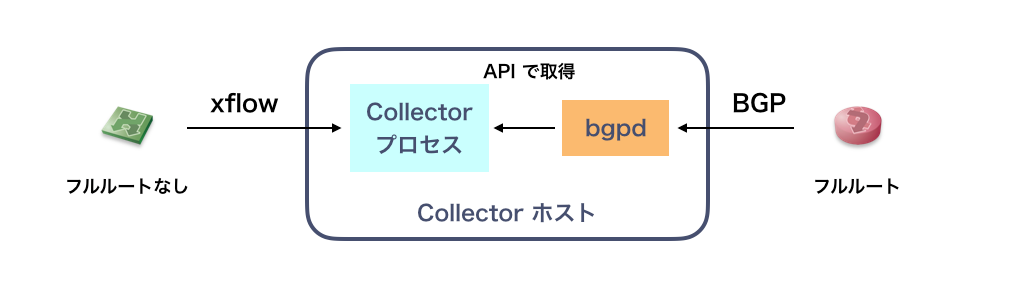
この場合、問題になりそうなのは bgpd の経路ルックアップパフォーマンスです。フルルートの注入に 10~20秒かかりそうなのはどちらのアプローチでも同じですが、bgpd の経路探索スピードは簡単にボトルネックになりえます。
一方で collector プロセスの実装はかなりシンプルになります。
まずトライするべきはこちらでしょうか。すごく高速に動く気はしませんが、十分なスピードで動いてくれる可能性はあります。
API で経路ルックアップできる bgpd (たとえば gobgpd)
まず思いつくのがgobgpd です。
今回は gobgpd に注目して、経路ルックアップのパフォーマンスを調査しますが… 「これもいけるらしいですよ」という実装がありましたら ぜひ教えてください!
ruby + gRPC で gobgpd 経路ルックアップ
collector として たとえば fluentd を利用する場合、ruby で gRPC することになります。
- MacBook Pro (Mid 2015) / Intel(R) Core(TM) i7-4980HQ CPU @ 2.80GHz
- ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-darwin16]
- grpc (1.12.0 universal-darwin)
- go1.10.2 darwin/amd64
- gobgpd v1.32
の環境で
$ gobgpd & $ gobgp global as 65000 router-id 10.0.0.1 listen-port 10179 $ wget http://archive.routeviews.org/route-views.wide/bgpdata/2018.06/RIBS/rib.20180604.0000.bz2 $ bunzip2 rib.20180604.0000.bz2 $ gobgp mrt inject global rib.20180604.0000
して
Table ipv4-unicast Destination: 704550, Path: 1394586
をロードし、以下の ruby クライアントから接続します。
$ gem install grpc-tools grpc
$ GOBGP_API=$GOPATH/src/github.com/osrg/gobgp/api
$ protoc -I $GOBGP_API --ruby_out=. --grpc_out=. --plugin=protoc-gen-grpc=`which grpc_tools_ruby_protoc_plugin` $GOBGP_API/gobgp.proto
$ bgpdump -M rib.20180604.0000 | grep 202.249.2.86 | awk -F \| 'NR%1000==0 { print $6 }' > routes
$ ruby -I. bench.rb
# bench.rb require 'benchmark' require 'ipaddr' require 'gobgp_pb' require 'gobgp_services_pb' def request(prefix) Gobgpapi::GetRibRequest.new( table: Gobgpapi::Table::new( family: Gobgpapi::Family::IPv4, destinations: [ Gobgpapi::Destination.new(prefix: prefix) ] ) ) end stub = Gobgpapi::GobgpApi::Stub.new('localhost:50051', :this_channel_is_insecure) stub.get_rib(request('1.1.1.1')) # The first call is super slow puts File.read('routes').split.map {|prefix| prefix = IPAddr.new(prefix).succ.to_s Benchmark.realtime { 10.times do stub.get_rib(request(prefix)) end } / 10 }.join(', ')
何をしているかというと、
- 1000 経路にひとつの割合で prefix をピックアップ
- prefix の先頭のアドレスについて、10回ルックアップ
- 平均の応答時間を出力
です。

横軸に prefix を並べていますが 値に意味はありません。「prefix が違っても応答時間はほぼ一定」という点がポイントです。gobgpd の RIB は単純な Hash であり、理屈は通っています。
さて、ここで気になるのは「longest match による経路ルックアップを、Hash でどのように実現しているか」ですね。たとえば 1.1.1.1 をルックアップした場合に 1.1.1.0/24 を返してほしい。
gobgpd (v1.32) では、若干力技の実装になっています。IPv4 であれば /32、/31、... のように prefix length を縮めながらマッチするまで探索します。RIB に存在する prefix そのものを探索した場合(赤) とRIB に存在しない longer prefix を探索した場合(緑) で特徴的な差があるのはこれが原因でしょう。
ここまでで、この環境なら ruby クライアントで 3~4k lookup/s くらいのパフォーマンスが期待できることがわかりました。
go + gRPC でgobgpd 経路ルックアップ
比較のために、go クライアントでも試してみます。goflow を利用する場合はおそらく go になるでしょう。
# bench.go package main import ( "github.com/osrg/gobgp/client" "os" "bufio" "github.com/osrg/gobgp/packet/bgp" "github.com/osrg/gobgp/table" ) func main() { client, _ := client.New("localhost:50051") fp, _ := os.Open("routes") scanner := bufio.NewScanner(fp) for scanner.Scan() { for i := 0; i < 10; i++ { client.GetRIB(bgp.RF_IPv4_UC, []*table.LookupPrefix{ &table.LookupPrefix{scanner.Text(), table.LOOKUP_EXACT}, }) } } }
$ go build bench.go $ time ./bench ./bench 0.81s user 0.76s system 112% cpu 1.399 total
これは 5k lookup/s くらいに相当しますが 劇的に高速になるわけではなさそうです。原因とししてはgRPC のオーバーヘッド、あるいは gobgpd 自身のパフォーマンスが考えられます。
一般に netflow / sflow には複数のフローエントリーが含まれ、さらに src ip address / dst ip address 双方を検索すると… 10 entries/flow としても flow packet あたり20回のルックアップが必要です。この場合 5k lookup/s = 250 pkt/s 程度であり、不安が残ります。
マルチスレッドで若干改善できるはず
ruby でも go でも遅いのですが、gRPC オーバーヘッドを考えるとマルチスレッド化することで改善が期待できるはずです。
たとえば ruby クライアントのスレッド数を 2 にすると
# bench.rb require 'benchmark' require 'ipaddr' require 'gobgp_pb' require 'gobgp_services_pb' require 'thread' def request(prefix) Gobgpapi::GetRibRequest.new( table: Gobgpapi::Table::new( family: Gobgpapi::Family::IPv4, destinations: [ Gobgpapi::Destination.new(prefix: prefix) ] ) ) end stub = Gobgpapi::GobgpApi::Stub.new('localhost:50051', :this_channel_is_insecure) stub.get_rib(request('1.1.1.1')) # The first call is super slow queue = Queue.new File.read('routes').split.each do |prefix| 10.times do queue << prefix end end puts Benchmark::CAPTION puts Benchmark::measure { threads = [] 2.times do threads << Thread.new { while !queue.empty? stub.get_rib(request(queue.pop)) end } end threads.each {|t| t.join} }
こんな感じなります。
1 スレッド
$ gobgp_performance $ ruby -I . bench.rb user system total real 0.877157 0.564896 1.442053 ( 1.707599)
2 スレッド
$ gobgp_performance $ ruby -I . bench.rb user system total real 1.139738 0.852233 1.991971 ( 1.258576)
若干ですが速くなっていますね。グラフにするとこんな感じ 👇 になります。

さらに ごくわずかですが処理をブロックしているスキマがありそうなので、ruby クライアント側で Origin AS をデコードしてみます。
def origin_as(table) path_attrs = table.table.destinations[0].paths.find {|p| p.best}.pattrs.map {|i| i.unpack('C*')} as_path = path_attrs.find {|a| a[1] == 2} case as_path[0] when 64 # 2 byte AS (as_path[-2] << 8) + as_path[-1] when 80 # 4 byte AS (as_path[-4] << 24) + (as_path[-3] << 16) + (as_path[-2] << 8) + as_path[-1] end end
クライアント側でデコードしているのは gRPC を待つ CPU 時間をデコードにあてたいからで、ruby でやっているのは FFI + GC を ruby <-> go 間で面倒みたくないためです。
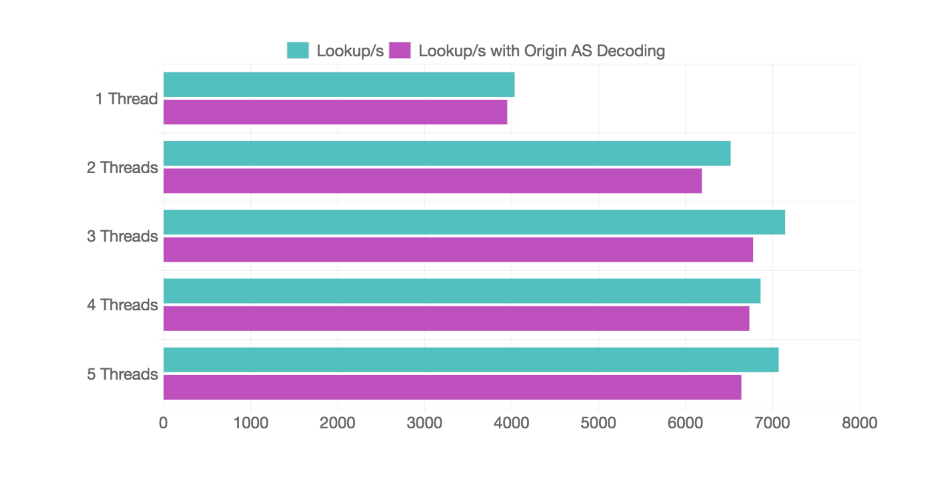
マルチスレッドにすることで、6k lookup/s くらいはいけそうです 🎉
まとめ
プログラムから経路ルックアップする場合のアプローチはいくつか考えられますが、簡易な実装で gobgpd を題材にベンチマークしてみました。
ruby クライアントであっても 6k lookup/s くらいのパフォーマンスは出そうですが、十分とは言えません。flow collector と一緒に使った場合、ここでつまる可能性があります。 しばらく運用してみて問題があったら RIB を内包するパターンの実装をトライする予定です。
また、実際の fluent plugin コード、flow-pipeline 向け kafka consumer は後日公開できるかもしれません。
2018-06-08 追記
tamihiro さんに「gobgpd の GetRib API、複数 prefix 渡せますよ」とご指摘いただき、再計測しました。
完全に見過ごしていた!

パラメーターが多くて見づらいのですが、1~5 スレッドごとに 8 本のバーチャートを引いてあり、上から順に
| gRPC あたりの prefix 数 | Origin AS デコード |
|---|---|
| 1 | ❌ |
| 1 | ⭕️ |
| 5 | ❌ |
| 5 | ⭕️ |
| 10 | ❌ |
| 10 | ⭕️ |
| 20 | ❌ |
| 20 | ⭕️ |
です。
- worker スレッドを増やしても さほど効果はないのは同じ
- gRPC あたりの prefix 数を増やす = gRPC 数を減らす と劇的にパフォーマンス改善する
- gobgpd の経路ルックアップというよりは、gRPC オーバーヘッドが効いていたと予想できる
- クライアントでOrigin AS デコードした場合、ある程度のところまではいくが頭打ちになる
という結果です。私には reasonable に見えます。
いずれにせよ、カンタンに 4~5倍 のスピードが手に入りました。🎉 ご指摘ありがとうございました!
inet-henge で、好みのネットワーク図を描くヒント
2020-02-25追記: SVG DOM が変更になったため、この記事のCSS ではスタイルが壊れるかもしれません。こちら も参考にしてください。
「構成管理DB から自動でネットワーク図を描く」というコンセプトで、inet-henge というライブラリを開発しています。
ネットワークは日々変化しますが、ネットワーク図の更新が面倒です。「このデバイスはあのデバイスとつながっている」くらいの接続情報の集まりから、オートレイアウトでネットワーク図を描きたい。これがモチベーションです。
ここでは、最近入った機能を使って 好みのネットワーク図を描くためのヒントを紹介します。
計算結果のキャッシュ
描画のたびに計算結果である位置情報をキャッシュし、それをヒントにすることで2回目以降の表示が高速になりました。
- キャッシュはブラウザに保存される
- 入力データが変わった場合はキャッシュを使わない
キャッシュを参照せず常に計算を行うには、次のように positionCache オプションを false にします。
<script> var diagram = new Diagram('#diagram', 'bar.json', {positionCache: false}); diagram.init('bandwidth', 'interface'); </script>
計算ステップ数を調整する
2回目以降はキャッシュを使えるという前提のもと、計算ステップを増やすことで よりよい配置を得つつ (2回目以降の) 表示速度を落とさない、ということが可能になりました。
このオプションを理解するために、内部で利用している D3.js のforce layout について説明します。
force layout はノード間に引力や斥力が働く場を想定し、初期配置から小刻みに時間ステップを進めながらノード配置を計算して収束させるD3.js モジュールです。ノード数やリンク数が増えるにつれ、一般的には収束までに必要な時間ステップ数が増加します。よりよいネットワーク図を得る代わりに表示時間が長くなるトレードオフがあったわけです。
これについて、過去のinet-henge では 最大時間ステップ数 = 1000 を決め打っていました 💦
表示のたびに再計算する仕様 & スピード優先 でした。
ここが可変になり、ネットワーク規模に合わせたステップ数を設定できます。デフォルトは今まで通りの 1000 です。
<script> var diagram = new Diagram('#diagram', 'bar.json', { ticks: 2000 // 2000 ステップまで計算する }); diagram.init('bandwidth', 'interface'); </script>
CSS スタイリング
次のようなJSONデータを
{ "nodes": [ { "name": "POP1-A" }, { "name": "POP1-B" }, { "name": "POP2-A", "icon": "https://inet-henge.herokuapp.com/images/router.png" }, { "name": "POP2-B", "icon": "https://inet-henge.herokuapp.com/images/router.png" }, { "name": "POP3-A", "icon": "https://inet-henge.herokuapp.com/images/router.png" } ], "links": [ { "source": "POP1-A", "target": "POP1-B", "meta": { "interface": { "source": "ge-0/{0,1}/0", "target": "Te0/{0,1}/0/0" }, "bandwidth": "20G" } }, { "source": "POP2-A", "target": "POP2-B", "meta": { "interface": { "source": "ge-0/{0,1}/0", "target": "Te0/0/{0,1}/0" }, "bandwidth": "20G" } }, { "source": "POP1-A", "target": "POP2-A", "meta": { "interface": { "source": "ge-0/0/1", "target": "Te0/0/0/1" }, "bandwidth": "10G" } }, { "source": "POP1-B", "target": "POP2-B", "meta": { "interface": { "source": "ge-0/0/1", "target": "Te0/0/0/1" }, "bandwidth": "10G" } }, { "source": "POP3-A", "target": "POP2-B"} ] }
次のHTMLのように描画するとします。
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <script src="https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.17/d3.js"></script> <script src="https://inet-henge.herokuapp.com/js/cola.min.js"></script> <script src="https://inet-henge.herokuapp.com/js/inet-henge.js"></script> </head> <body> <div id="diagram"></div> </body> <script> var diagram = new Diagram('#diagram', 'bar.json', { pop: /^([^\s-]+)-/ }); diagram.init('bandwidth', 'interface'); </script> </html>
デフォルトで左のような図になりますが、右のようにCSS で要素ごとにスタイルを変えることが可能です。
- グループ、ノード、リンク全体にスタイルを当てる
- 特定グループにスタイルを当てる (
POP1) - 特定ノードにスタイルを当てる (
POP1-A) - 特定リンクにスタイルを当てる (
POP1-A-POP1-B間)
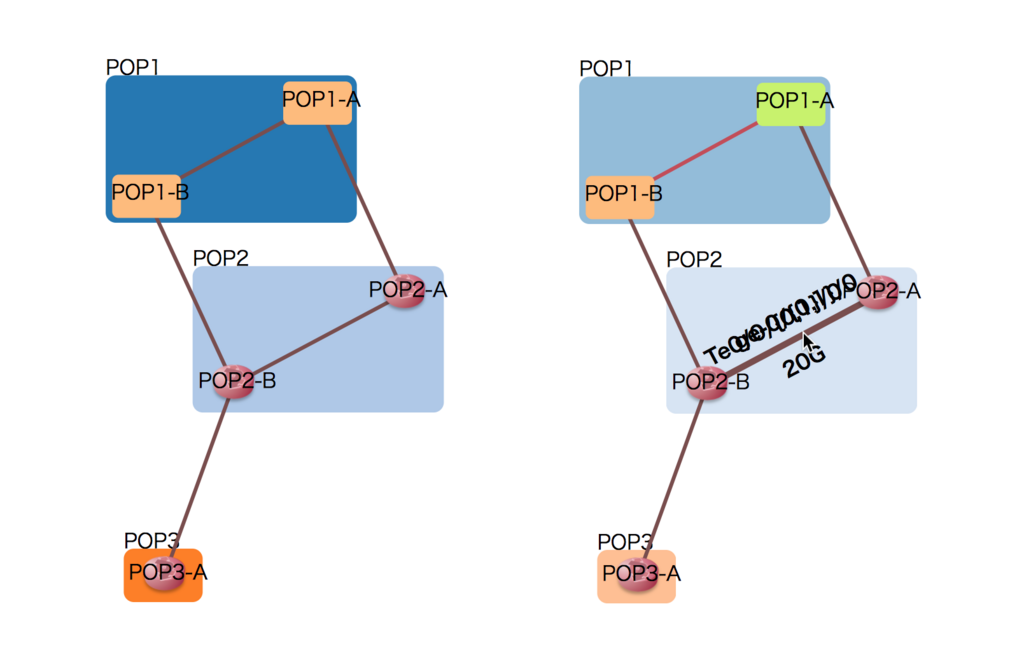
下のCSSは、右の図を出力するサンプルです。
配色を変えているのに加え、リンクにマウスオーバーすると強調表示するようになっています。
(リンクラベルが重なって読めませんが、後ほど調節します)
.group rect { opacity: 0.5; } .node, .group rect { cursor: move; } /* 特定 node, link のみスタイルを当てる */ .group.pop1 rect { fill: #4ecdc4 !important; } .node.pop1-a rect { fill: #c7f464 !important; } .link.pop1-a-pop1-b { stroke: #c44d58; } /* リンクにマウスオーバーすると、リンクを太く & ラベル表示 */ .link:hover { stroke-width: 5px; } .link:hover ~ .path-label { font-weight: bold; visibility: visible !important; }
リンク長さの調節
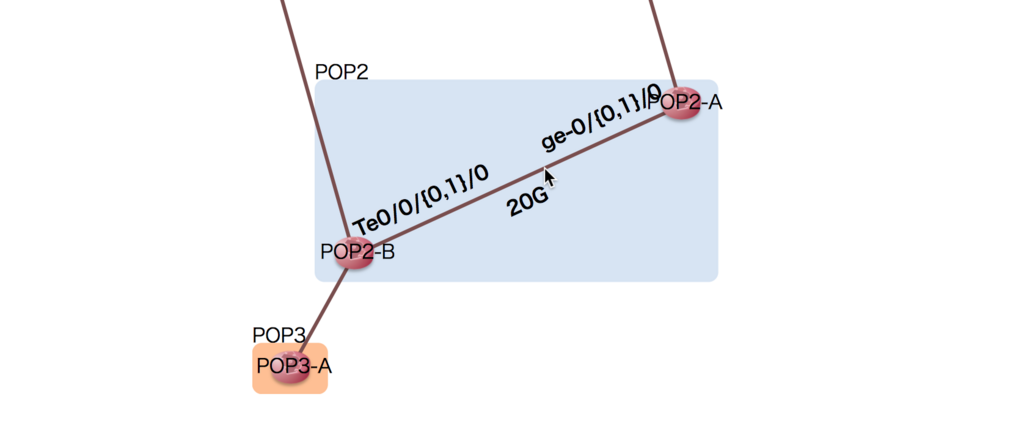
先ほどの例で、マウスオーバーしたときのリンクラベルが重なっていました。
これは、次のようにリンク長さを調節することで解決できます。
<script> var diagram = new Diagram('#diagram', 'bar.json', { pop: /^([^\s-]+)-/, distance: function(force) { force.jaccardLinkLengths(100, 2); } }); diagram.init('bandwidth', 'interface'); </script>
- ジャッカード距離を計算に使う
- 共通ノードを持たないノード間の、ベースとなる長さを
100 - ジャッカード距離に対する係数を
2
としています。
描画したい ノード数、リンク数 によっていい感じのパラメーターが変わってきますので、「見づらいな」と感じたら時々調節してみることをオススメします。
(調節はコンセプトに反するので、ラベルの重なり検知は課題のひとつ💪)
ネットワークステータスの反映
下のように、障害のあるルーターやリンクを強調表示できます。
データ:
{ "nodes": [ { "name": "POP1-A" }, { "name": "POP1-B" }, { "name": "POP2-A", "icon": "https://inet-henge.herokuapp.com/images/router.png" }, { "name": "POP2-B", "icon": "https://inet-henge.herokuapp.com/images/faulty_router.png" }, // アイコン差し替え { "name": "POP3-A", "icon": "https://inet-henge.herokuapp.com/images/router.png" } ], "links": [ { "source": "POP1-A", "target": "POP1-B", "meta": { "interface": { "source": "ge-0/{0,1}/0", "target": "Te0/{0,1}/0/0" }, "bandwidth": "20G" } }, { "source": "POP2-A", "target": "POP2-B", "meta": { "interface": { "source": "ge-0/{0,1}/0", "target": "Te0/0/{0,1}/0" }, "bandwidth": "20G" } }, { "source": "POP1-A", "target": "POP2-A", "meta": { "interface": { "source": "ge-0/0/1", "target": "Te0/0/0/1" }, "bandwidth": "10G" } }, { "source": "POP1-B", "target": "POP2-B", "meta": { "interface": { "source": "ge-0/0/1", "target": "Te0/0/0/1" }, "bandwidth": "10G" } }, { "source": "POP3-A", "target": "POP2-B", "class": "fault" } // クラス指定 ] }
CSS:
.link.fault { stroke: #c44d58; stroke-dasharray: 5, 5; }
出力:
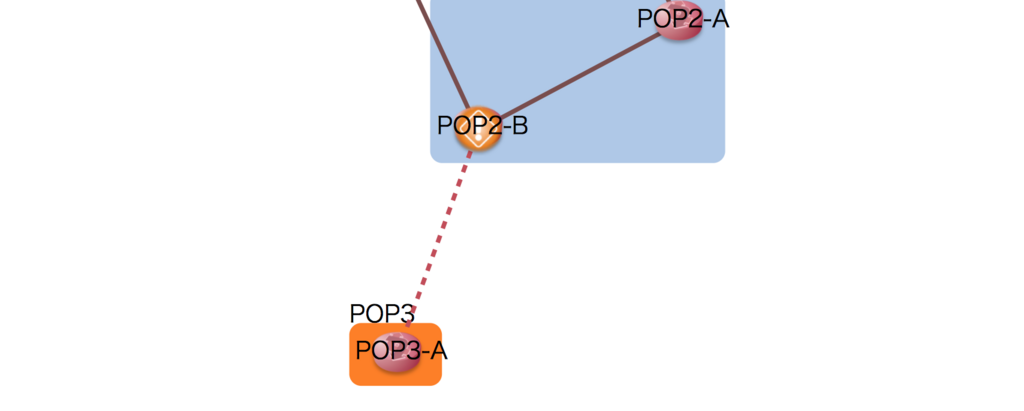
ノードはアイコンの差し替えを、リンクは class 属性の追加によりスタイルを操作します。
補足: ほかのCSS ヒント
CSS スタイリングについて、別の記事も書きました。こちらも参考にしてみてください。
補足: JANOG41 で登壇しました
ずいぶん経ってしまいましたが、JANOG41 でinet-henge について話してきました。
LT で、事前投票 上位のトークが採択されるシステムでしたが…なんと一位 🎉🎉🎉
会期中やその後に「使ってみました」「ここ、こうなりませんか?」などなど多数のフィードバックを頂きまして、めちゃくちゃ有意義なミーティングでした。ありがとうございました!
今回紹介したヒントのほとんどが、そのときの話を参考に実装したものです。
まだまだフィードバックお待ちしてます!