VirtualBox 上の IOS-XRv コンソールに接続する
Cisco IOS-XRv は ハイパーバイザーが開くTTY にコンソールを接続してくれないので,自分で設定する必要がある.
たとえばVMWare Fusion はコンソールをPTY に繋ぐ機能があるので簡単だが,VirtualBox は面倒.
コンソールをドメインソケットとして出す
下のような設定をする.
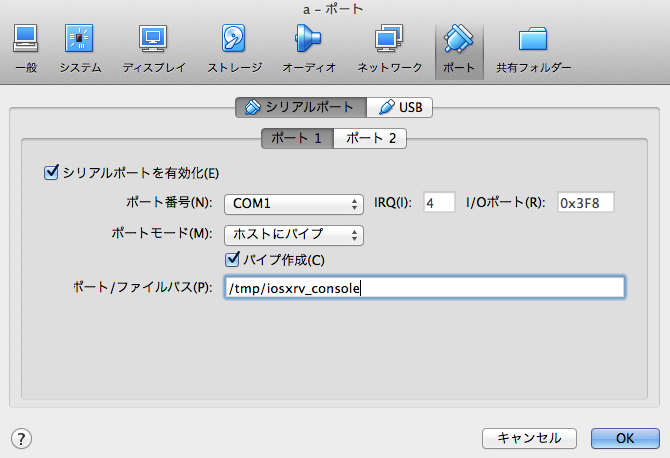
socat で接続する
brew install socat socat UNIX-CONNETCT:/tmp/iosxrv_console stdio,raw,echo=0,escape=0x1a
こんな感じで標準入出力をドメインソケットに接続できる.escape=0x1a は^Z で接続を切るための設定.このへん を参考にしながら好みで変えるといいと思う.
ネットワークエンジニアリングはアジャイルじゃない
リーン・スタートアップと言ってもいい.Web 界隈ではあたりまえの開発手法を ネットワークの開発に使うのはむずかしい.
自分はインターネットが得意で (ネットワークとしてのインターネットね!) たかだかIP と上下レイヤーくらいしか分からないんだけど,なにか新機能を作るときの事情はだいたい共通していると思うし,幅広く「ネットワーク」とくくってしまう.実際は共通どころか,エンタープライズネットワークのほうが制約が多いし,IP よりPHY のほうがつらい.まだ自由度があるインターネットでさえ,Web 界隈やミドルウェア,サーバーインフラ界隈のようなスピードで動けない.
うらやましいことに,それらの開発についてはオンライン/オフラインいろんなところで議論され,本が出版され,ノウハウが溜まっていく.一方でネットワーク開発は 低いギアでアクセル踏みっぱなしのような,なんか「タスクこなしてるんだけど進んでない感じ」がする.なんですかこの違い.アプリレイヤーの仕事をしているときとは違ったストレスを感じる.
ネットワークエンジニアリングの現場
ハードウェア / ソフトウェアを使ってネットワークに新機能を足したり,地理的に / 帯域的に拡張したり,運用を変えたりする場合,
- どういう技術があるか調査する
- テスト環境で粗く試す
- 設計する
- 必要なハードウェア,ソフトウェアを調達する
- 検証環境でちゃんと試す
- 必要な回線を調達する
- ユーザーから借用をとる
- ハードウェア,ソフトウェア,回線をインストールする
- デプロイする
みたいなことが必要だが,あるあるネタとして
- 調達のリードタイムが予測できない / 長い
- やってみないと,実網にどんな影響が出るかわからない
- 借用に要する時間が予測できない / 長い
こういう問題をよく見る.たとえばソフトウェア開発と比較すると「ソフトウェアには起こらない問題」と「起こってるんだけど頑張って回避している問題」が含まれていて,ネットワークエンジニアはソフトウェアエンジニアが頑張っているところを盗まないといけないと思う.
もちろん「コード書いて自動化しましょう」もその1つなんだけど,生産性が低い原因はたぶんそれだけではない.
生産性の低さ
自分は,デプロイまでの待ち時間が大きな原因だと思っている.調達とか 会社をまたいで調整しないといけないタスクが挟まっていたり,借用 (お客さんに「メンテしていいですか」と聞いて回る営み) のようなタスクがあるかもしれない.契約上は1ヶ月前に通知すればメンテできるが,慣例で一部法人ユーザーにお伺いを立てたりすることがある.「これ!と決めたやつをデプロイするまでに1ヶ月待たないといけない」なんて普通にある.
そのせいで 年間のデプロイ回数が限られ,フィードバックがないから試行錯誤できず,一発で大成功させようとして準備の時間が増え,待っている間にネットワークが変わって手戻りが発生する. 他者との調整が主なボトルネックだから,ミーティングが増え,資料を作りまくり,調整能力だけがグングン伸びる.
ソフトウェア開発はどうやっているか
アジャイル「イテレーションを小さく回せ」リーン・スタートアップ「MVP から始めよ」両方とも,デプロイに時間をかけず フィードバックを短期間で得るための努力があってのことだと思う.大規模にやれば「マージに時間がかかる」「QA チームが求める品質にならない」いろんな問題が出るところを,「CI を回す」「毎週火曜日にリリースすることにする」「組織を変えて,QA 機能をプロジェクト内に持つ」「ベータ提供するしくみ」「一部ユーザーにのみデプロイし,小さく失敗して早く直す」など,技術で解決するのはもちろんのこと 組織 / ワークフロー / ポリシーを見直して頑張ってる.
ネットワーク開発は何ができるか
「調達のリードタイムが予測できない / 長い」というのはしょうがない.でも「在庫を持つコスト」と「持たないことによる生産性の低下」は天秤にかけられるかもしれない.
「やってみないと,実網にどんな影響が出るかわからない」とくにインターネットルーティングは生き物だからしょうがないけど「自分たちのネットワークは複雑だから,やってみないとわかりません」は避けないといけない.シンプルに保つ努力は必要だし,インターネットの端っこにテストベッドを持つ選択肢もあるし,堅く作る前のベータサービスに付き合ってくれるユーザーがいるかもしれない.
「借用に要する時間が予測できない / 長い」レイヤーが低いほど上に乗っているものが多い = 影響範囲が大きいので,メンテナンスには慎重になるべき.でもメンテナンスポリシーが曖昧だと「うーん,分からんけど安全側に倒して…」ってなるし「契約ではできることになってるけど,いままでそうしてなかったから…」みたいなのも癌だと思う.
ちなみに
いま,週のうち数日はフリーのネットワークエンジニアとして働いており,タスクをガッとこなす日と何もしない日が極端に分かれている.それでも自分がボトルネックになるケースは少ない (はず!) ので,待ちが多いと時間を区切って生産性を上げるという手が効く.そういう意味では,トヨタのリーン生産方式の方は勉強しないとなあ,と思ってる.
Time Attack: bgpsimple vs exabgp 2nd Heat
After @exabgp thankfully gave me an advice on my previous post, I carried out performance tests of bgpsimple and exabgp again.
@codeout Great blog entry: http://t.co/FHKPp9DXN6 . It would be great if you could check how much faster our API is to send the routes out.
— ExaBGP (@exabgp) May 15, 2015Right, API might be faster than massive config loading.
Full Route Advertisement
Service providers are struggling with the growing IPv4 full route and recently some people abandon default-free zone due to TCAM space problem. But they still sometimes need full route for analysis and forensic purpose. So, I'm curious, in such a case, is there good toolbox to inject full route into their network?
I think that simple BGP daemons are good options,
- bgpsimple
- exabgp with mrtparse
can read a full-table bgpdump archive and advertise to neighbor routers. Then, how fast are they?
Test Equipments
- MacBook Pro (Retina, Mid 2012) + VMWare
- Guest
Firefly was configured as a dumb BGP neighbor rejecting any route so that it couldn't affect route injector's performance.
Benchmark
| bgpsimple | exabgp with config file | exabgp with API | |
|---|---|---|---|
| Until BGP turnup | 0'00" | 2'58" | 0'02" |
| To complete advertising since BGP turnup | 2'38" | 1'13" | 4'13" |
| To complete advertising since "clear bgp neighbor" | 2'43" | 2'09" | 2'31" |
Version tested: *1
It took bgpsimple 2'38" to advertise full route, while exabgp required 4'11" ~ 4'15" in total.
exabgp shows different behavior depending on its configuration. exabgp with config file in the table above means "a bunch of static routes configured in .conf converted by mrtparse", exabgp with API means "configured to run an external script for route injection". The script looks like:
import sys import time messages = [ 'announce route 1.0.0.0/24 origin IGP as-path [2497 15169 ] next-hop 192.168.0.78', ... ] while messages: message = messages.pop(0) sys.stdout.write( message + '\n') sys.stdout.flush() while True: time.sleep(1)
See exabgp's wiki for more details.
Conclusion
bgpsimple is handier and faster way to inject full route from bgpdump archive. It simply assumes that the route information is given as a file in bgpdump -m format, read it with no signal handling and process routes in a simple loop with generating a minimal set of objects.
*1:Different version of exabgp from the previous post
ruby で pcap を読む
tcpdump やtshark などでキャプチャーしたパケットを,ruby で読むためのライブラリがあります.
The Ruby Toolbox などで検索すると山のように出てきますが,いくつか良さそうなのを紹介します.
PacketFu
例: IP パケットのsource address だけを抽出したい場合:
require 'packetfu' packets = PacketFu::PcapPackets.new.read(File.read('sample.pcap')) packets.each do |p| packet = PacketFu::Packet.parse(p.data) puts packet.respond_to?(:ip_saddr) && packet.ip_saddr end
PacketFu::Packet#inspectがちゃんとあってprint デバッグしやすい
[1] pry(main)> p packet --EthHeader------------------------------------------------- eth_dst fe:ff:20:00:01:00 PacketFu::EthMac eth_src 00:00:01:00:00:00 PacketFu::EthMac eth_proto 0x0800 StructFu::Int16 --IPHeader-------------------------------------------------- ip_v 4 Fixnum ip_hl 5 Fixnum ip_tos 0 StructFu::Int8 ip_len 48 StructFu::Int16 ip_id 0x0f41 StructFu::Int16 ip_frag 16384 StructFu::Int16 ip_ttl 128 StructFu::Int8 ip_proto 6 StructFu::Int8 ip_sum 0x91eb StructFu::Int16 ip_src 145.254.160.237 PacketFu::Octets ip_dst 65.208.228.223 PacketFu::Octets --TCPHeader------------------------------------------------- tcp_src 3372 StructFu::Int16 tcp_dst 80 StructFu::Int16 tcp_seq 0x38affe13 StructFu::Int32 tcp_ack 0x00000000 StructFu::Int32 tcp_hlen 7 PacketFu::TcpHlen tcp_reserved 0 PacketFu::TcpReserved tcp_ecn 0 PacketFu::TcpEcn tcp_flags ....S. PacketFu::TcpFlags tcp_win 8760 StructFu::Int16 tcp_sum 0xc30c StructFu::Int16 tcp_urg 0 StructFu::Int16 tcp_opts MSS:1460,NOP,NOP,SACKOK PacketFu::TcpOptions
- C拡張ではないため 遅い
pcap / ruby-pcap
例: IP パケットのsource address だけを抽出したい場合:
require 'pcap' packets = Pcap::Capture.open_offline('sample.pcap') packets.each do |packet| puts packet.ip? && packet.ip_src end
このgem はruby 2.2 に対応してません.(2015-07-27 追記: 対応されました)
本体に取り込まれるまでは
gem install specific_install gem specific_install https://github.com/codeout/ruby-pcap
or
git clone https://github.com/codeout/ruby-pcap cd ruby-pcap gem build pcap.gemspec gem install --local pcap-0.7.7.gem
でインストールできます.
ほか
いろいろありますが,各種プロトコルヘッダーにアクセスするAPI が少なくて使いやすいとは言えません.
ベンチマーク: PacketFu vs. pcap
10,000 パケットの処理時間:
user system total real PacketFu 3.760000 0.040000 3.800000 ( 3.857046) pcap 0.010000 0.000000 0.010000 ( 0.012067)
やはり差が出ます.パフォーマンスが要求される場合は pcap オススメ.
ベンチマーク用コード:
require 'packetfu' require 'pcap' require 'benchmark' Benchmark.bm do |x| packets = PacketFu::PcapPackets.new.read(File.read('sample.pcap')) x.report('PacketFu') do packets.each do |p| packet = PacketFu::Packet.parse(p.data) packet.respond_to?(:ip_saddr) && packet.ip_saddr end end packets = Pcap::Capture.open_offline('sample.pcap') x.report('pcap') do packets.each do |packet| packet.ip? && packet.ip_src end end end
別途PacketFu をプロファイリングしてみても,パケットのparse が遅そうです.
% cumulative self self total time seconds seconds calls ms/call ms/call name 6.44 10.16 10.16 297491 0.03 0.05 StructFu::Int#read 4.46 17.20 7.04 171613 0.04 0.06 PacketFu::EthPacket.can_parse? 3.33 22.45 5.25 70757 0.07 0.15 PacketFu::IPPacket.can_parse? 3.02 27.22 4.77 296710 0.02 0.02 PacketFu.force_binary 3.00 31.96 4.74 44296 0.11 0.18 PacketFu::EthOui#read 2.45 35.83 3.87 12958 0.30 4.20 PacketFu::IPHeader#read 2.30 39.46 3.63 8866 0.41 2.22 PacketFu::TCPPacket#tcp_calc_sum 2.17 42.89 3.43 1149060 0.00 0.00 String#[] 2.09 46.19 3.30 17732 0.19 1.64 PacketFu::TcpOptions#read 2.09 49.49 3.30 27390 0.12 0.30 PacketFu::TcpOption#read 2.08 52.77 3.28 79465 0.04 0.06 PacketFu::Packet.layer 1.93 55.81 3.04 155600 0.02 0.03 StructFu::Int#to_i 1.84 58.72 2.91 966615 0.00 0.00 Struct#[] 1.83 61.61 2.89 159701 0.02 1.18 PacketFu::Packet.parse 1.80 64.45 2.84 8866 0.32 4.71 PacketFu::TCPHeader#read 1.79 67.28 2.83 278978 0.01 0.03 Struct#force_binary
Time Attack: bgpsimple vs exabgp
お手軽フルルート環境に興味が出て,どの程度お手軽にできるのか試しました.
(参考: Other OSS BGP implementations · Exa-Networks/exabgp Wiki · GitHub)
をざっと見て
ので選ぶと,bgpsimple / exabgp が候補になります.
bgpsimple,Google Code にしかないっぽいんだけど 大丈夫か...
フルルート広告の所要時間が気になる
bgpsimple はbgpdump でMRT table dump をテキスト化すれば入力できるし,exabgp はmrtparser で設定ファイルを出力できます.両方お手軽なんですが,経路広告の所要時間が気になるので計測してみました.
環境
- MacBook Pro (Retina, Mid 2012) + VMWare
- Guest
- 4x Intel(R) Core(TM) i7-3820QM CPU @ 2.70GH
- 2GB RAM
経路受信側は別Hypervisor のfirefly.ボトルネックにならないよう,経路はすべてreject する設定.
結果
| bgpsimple | exabgp | |
|---|---|---|
| ピアが上がるまで | 数秒 | 3'59" |
| フルルート広告し終わるまで | 2'39" | 1'15" |
| clear bgp 後,フルルート広告し終わるまで | 2'34" | 2'57" |
bgpsimple のほうがトータル速そう.exabgp は設定ファイルをload → parse するのに4分もかかるため,全体として2倍遅いです.
注意
bgpsimple を使うときはholdtimer を長く
bgpsimple は経路を広告し終わるまでKEEPALIVE メッセージを送らないため,経路広告が終わるまえにHold Timer Expire する可能性が高い.
exabgp は適宜KEEPALIVE してくれます.
bgpsimple は,経路リストの全エントリーについて広告
bgpdump -m によってMRTをテキスト変換してbgpsimple に入力しますが,もとのMRT には複数neighbor 分の経路が保存されています.そのため,テキスト変換された経路リストには同じprefix の経路が複数含まれている場合があります.これを順次UPDATE メッセージとして送信すると,対向のfirefly では後に受け取ったpath だけがAdj-RIBs-In に残ります.
ムダですね.
exabgp はMRT ファイル上で先に現れた経路のみ広告
mrtparser の仕様により,prefix が同じであれば先に読まれたpath のみUPDATE メッセージとして送信します.ムダはありませんが,bgpsimple で経路広告した場合と比べて 対向のAdj-RIBs-In の中身が変わってくることに注意です.
HipChat ゲストアクセス時も履歴を保存したい
HipChat は無料プランでもゲストを招待できて便利だけど,招待された側は履歴をたどれなくて不便.
- 自分がオフラインだった期間の履歴は読めない
- 前回ゲストとして発言した自分の履歴も読めない
- タブを閉じたり,リロードしても消える
毎回まっさらな状態から始まって「前回ログインしたA さん」と「今回ログインしたA さん」を別人として扱うのは,サービスとしてまっとうな実装に見える.
Chrome Extension でなんとかした
でも不便なので,Chrome Extension 作った.
自分がオンラインだった期間の履歴を,Chrome が自動保存して 次回ログイン時に復元する.
私の環境だとうまく動いているけど,beforeunload をフックしていて,場合によっては自動保存の前にログアウトが走ってしまって動かないかもしれない.その場合はご連絡ください.
Guest access to HipChat
HipChat is a cool chat service which enables "guest mode" even in a free plan, but its security policy is sometimes annoying.
- Chat history never show up, if it was done while a guest was offline.
- History is always gone after logging in again, even the guest's words.
- Closing or reloading HipChat tab mistakenly causes a history blackout.
This behavior looks secure enough as it's complicated for the service to identify a guest every time and display only visible chat history with no security risk.
Auto-save and restore in browser side
HipChat Pin is a Chrome extension which automatically saves chat history in guest mode and restores when logging in next time.
Note that it has a potential timing issue of beforeunload callback. Please contact me if it doesn't work in your Chrome. I have some ideas to fix it.
古いメールを全文検索できるよう保存する
昔からのメールが溜まってて,検索できる状態で置いときたい.
どんな検索エンジンを使うのがいいかを検討した.
ざっくり言うと
Xapian をバックエンドとするmu でインデックスして,サーバーサイドでmu4e をつかって検索するのがよさそう.
やりたいこと
- 古いメールは,普段目に触れないようにしたい
- 検索したい
- 検索するのはまれなので,常駐プロセスを増やしたくない
候補
- クライアント側で検索
- Mail.app
- Thunderbird
- サーバー側で検索
- Lucene バックエンドなもの (Solr,Elasticsearch など)
- Xapian バックエンドなもの (mu など)
比較
古いメールの一部を使って試す.
- 930MB
- 2.5万通
クライアント側で検索
(MacBook Pro - Retina, Mid 2012)
慣れたメールアプリで検索できるが,インデックスするのにダウンロードが発生する.筋が悪い方法だけど いちおう試してみる.古いメールはIMAP で取ってくる.
| インデックス時間 | ダウンロード後のフォーマット | ダウンロード後のサイズ | インデックスサイズ | |
|---|---|---|---|---|
| Mail.app | 1時間 | .emlx | 1.3GB | 22MB |
| Thunderbird | 10分 | mbox | 890MB | 55MB |
Mail.app
-
- インデックス時間も保存メールサイズも現実的
サーバー側で検索
(4 core 3.3GHz + 4GB RAM)
- Lucene ベースのSolr,Elasticsearch はdaemon を常駐させないといけないので,今回の用途には合わない
- Java 書いて直接Lucene 叩けばいけそう (やってない)
- dovecot-lucene はアリかも (libc6 ごとアップグレードする必要があって試してない)
- IMAP SEARCH にも対応できる
- メモリを浪費する可能性ある
- いっぽうXapian は常駐しないタイプのフロントエンドが充実
- 今回はmu を試した
| インデックス時間 | ダウンロード後のフォーマット | ダウンロード後のサイズ | インデックスサイズ | |
|---|---|---|---|---|
| mu | 1分 | - | - | 110MB |
インデックスするには
$ mu index -m ~/Maildir
検索するには,CLI から
$ mu find ipv6
$ mu find from:\*gmail subject:ipv6
のようにするか,mu4e をつかう.
$ emacs -f mu4e

気軽でいい感じ.
インデックス時のスワップに注意
メモリをじゃぶじゃぶ使うタイプのソフトウェアっぽくて,
$ mu index --xbatchsize 1000 -m ~/Maildir
のようにしてメモリ使用量を抑える必要があった.
インデックスの最適化
mv .mu/xapian .mu/xapian.old xapian-compact .mu/xapian.old .mu/xapian rm -rf .mu/xapian.old
インデックスサイズが3.4G → 2.2G まで小さくなった.
まとめ
下のどちらかがいいと思う.
- Thunderbird に食わせて,サーバーからメールを消す
- サーバー側に置いといて,mu か mu4e で検索する