ネットワークは宣言的になりえるか
はじめに
Kubernetes などのコンテナオーケストレーターとの対比によって、ネットワークの世界でも同じように制御できないか注目されています。Cisco、Apstra、VMWare などが言う "Intent Based Networking" や "Closed Loop Automation" も同じものを指していると思われます。宣言的ネットワーキングは「あるべき状態の維持をプロトコルやソフトウェアに任せられるかもしれない」という点で運用上のメリットがあります。
以前所属していた国際Tier1 ISP *1 で、Kubernetes ほど洗練されてはないものの コンセプトとしてはこれを実践していたり、現在もネットワーク自動化の取り組みの中でゴールをここに設定したりしています。
このエントリーでは、
- 宣言的ネットワーキングとは何なのか
- 従来のネットワーク運用を宣言的ネットワーキングに移行できるのか
- 移行できるとしたら、どういうステップを踏めばよいか
について自分の考えをまとめてみたいと思います。
宣言的ネットワーキングとは何なのか
ざっくりコンセプトとしてはKubernetes と同じで、「あるべき状態を宣言的に記述し API に渡すことで、システムが現在の状態を監視、必要に応じてあるべき状態に収束させてくれるネットワーク制御手法」のことです。
"宣言的" なのはあるべき状態の記述方法・APIの呼び出し方であって、内部的に実行される状態遷移プロセス自体は手続き的になりえます。Kubernetes に詳しくありませんが、おそらくそちらも同じであろうと想像しています。「システムに触れるユーザーが手続きを意識しない」であって「手続き的な何かは一切存在しない」ではない点に注意が必要ですが、これまでの議論 *2 を踏襲し、ここでは「宣言的ネットワーキング」と書くことにします。
実現のためのキーポイントはいくつかあって
- あるべき状態の記述方法と、その対象・抽象度の検討
- あるべき状態の抽象的な記述 (1) を、ネットワークデバイスが解釈できる設定・パラメーターに変換する機能
- 現在のネットワーク状態を取得する機能
- ネットワークデバイス上の表現を使って、あるべき状態 (2) と現在 (3) を比較する機能
- 差分 (4) を自動投入する機能
が必要だと考えています。それぞれについては、ネットワーキングならではの事情もふまえて後述します。
従来のネットワーク運用との対比
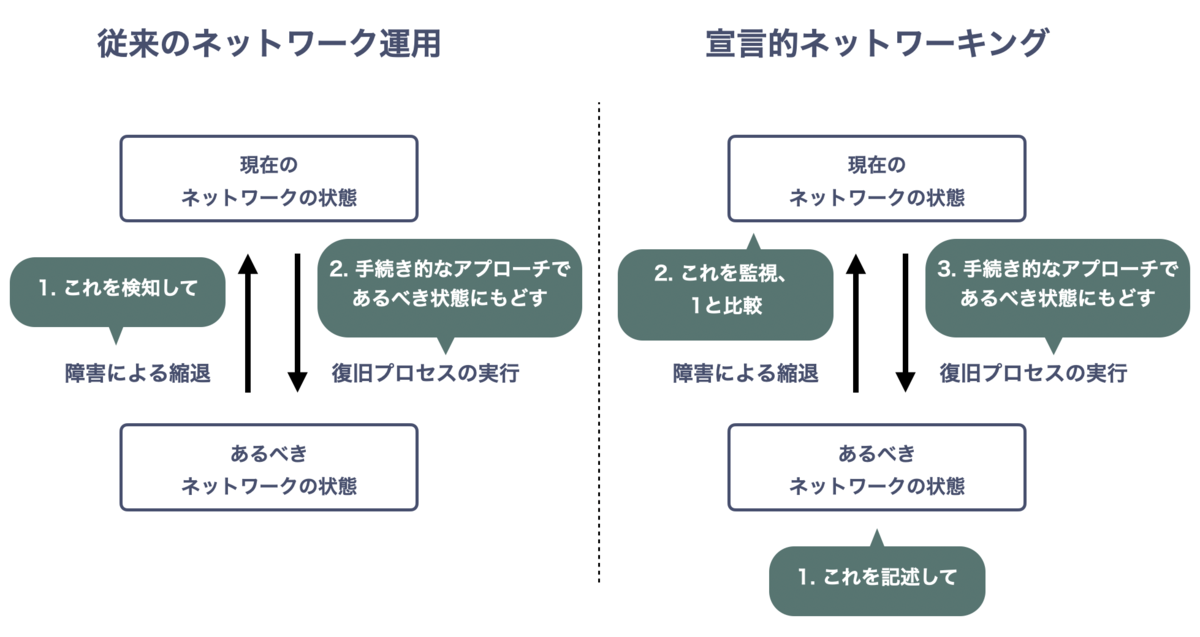
従来のネットワーク運用では、あるべきネットワーク状態を包括的には記述しません。代わりに 障害などのネットワークイベントを検知し、手続き的なアプローチによってあるべき状態に復旧させます。あるいは、あるべき状態が変化した際にその差分だけを反映させます。
従来のネットワーク運用でも 宣言的アプローチを取っている部分はあります。たとえばICMPによる到達性・遅延監視などです。許容できる latency を定義し 現在の状態と比較、超過した場合に通知するような運用はよく行われています。根本原因の自動特定 (Root Cause Analysis)・自動修復(Self Healing / Remediation) まで行えないものの アプローチとしては宣言的であり、部分的にではありますが 宣言的ネットワーキングに必要な要素を実装できていると言えそうです。
一方、宣言的ネットワーキングでは現在のネットワーク状態を取得、あるべき状態との比較を軸にします。比較した結果差分があれば状態に変化を加え、あるべき状態に自動収束させます。これをフィードバックループ的にぐるぐる回すことがポイントです。 (Reconciliation Loop)
もちろん、影響時間の短縮や Root Cause Analysis のために、障害などネットワークイベントを追加のトリガーとしたり、解析のヒントにすることはあると思います。
脱線しますが、ループを回す際、フィードバックが強すぎるなどシステムが発振して収束しないことも考えられますので、安定化のための何かしらの仕組みは別途必要になります。
コンテナオーケストレーションとの対比
Kubernetes をはじめとする宣言的コンテナオーケストレーションと宣言的ネットワーキングについて、若干乱暴ですが次のような違いがあると考えています。
| コンテナオーケストレーション | ネットワーキング | |
|---|---|---|
| 制御対象 | コンテナ群 | ネットワーク |
| あるべき状態は物理を含むか | ❌ | ⭕️ |
| 制御対象自体がロバストか | ❌ | ⭕️ |
両者を比較するために
1. あるべき状態の記述方法と、その対象・抽象度の検討
について触れておく必要があり すこし脱線しますが、「あるべき状態をどのレベルまで抽象化して記述できるか」はとても重要です。 あるべき状態を宣言的に書くと その状態を維持してくれるシステム があるとして、何を記述するでしょう? 究極的には
- サービスを安価に安定的に提供できること
のように書きたいんじゃないでしょうか? これは残念ながら抽象的すぎて、今のところ現実的ではないため どんどん具体化します。
- 秒間 1万 HTTPSリクエストを返す。10 ms 以内に。月額コストは1000万円以内
- 国内ユーザー間のIPトラフィックをトランジットする。自社の網内で latency 20 ms 以内、jitter 0.1 ms 以内、loss rate 0.01% 以内。月額コストは1億円以内
のような、サービス品質を記述するレベルでも厳しいかもしれません。結局のところ、あるべき状態の抽象度として
- 東京リージョンに、このスペックで動くapp AのPod が5コある
- データセンターA にいるISP X からトランジット10G x 2 を買い、データセンターB に収容する
くらいまで具体化する必要があるんじゃないでしょうか。もともと宣言的に記述したい対象はビジネス・サービスレベルのものであるはずが 抽象度が高すぎて実現できず、具体化して「ビジネス・サービスを実現するために設計したコンテナ配置、ある相互接続」レベルまでブレイクダウンする必要があります。
さて 話を戻しますが、この抽象度まで下げる場合 ネットワークには物理的な制約が強く現れます。たとえばISP X からトランジットを買い 専用線を借りて相互接続する場合、その接続に替えはありません。「ISP X に繋がるこの専用線にトラフィックを乗せる」があるべき状態になります。コンテナのように「すぐ廃棄してどこかに新規作成し、数があってればOK」とすることができません。残念なことに障害時には物理交換が発生するため、復旧プロセスも完全に自動化することは困難です。
このデメリットを補うため、ネットワークプロトコル自体にロバスト性が備わっています。 物理は替えがきかないものの、あらかじめ冗長性を持ちさえすれば、それらをうまく切り替えて自律分散的に動く仕組みがもともとあるわけです。 *3
この性質のため、ネットワーク制御システムはコンテナと比べておそらく薄くできます。コンテナ自体のロバスト性が低いため オーケストレーターが監視・操作する必要があるのに対し、「ネットワークをうまく設計して設定しておけば、あとは自律的に動いてくれる」というのは、おもしろい違いです。
個人的には、宣言的ネットワーキングにおける制御システムの主な役割は QoS と最適化だと考えています。乱暴に言えば、ネットワークは
- 何かが壊れたら、自律的にそこを使わないようにして予備を使い始める
- 壊れたものが直ったら、自律的に元に戻る
ので、残る問題としてまず思いつくのが
- 壊れた判定が難しいもの
- 計測しづらいもの
- 自律的な調整が難しいもの
だからです。たとえば
などです。
従来のネットワーク運用を宣言的ネットワーキングに移行できるのか
さきに
宣言的ネットワーキングにおける制御システムの主な役割は QoS と最適化だと考えています
と書きましたが、ここでは簡単のために「あるべき状態を宣言的に記述でき、何かコマンドを叩くとネットワークがその状態に収束する (ただし物理を除く)」を一歩目のゴールとしましょう。これはKubernetes チュートリアルに出てくるレベルと同じもので、簡単ですが宣言的ネットワーキングだと言っていいと思います。
図示してみると 👇 のような感じです。
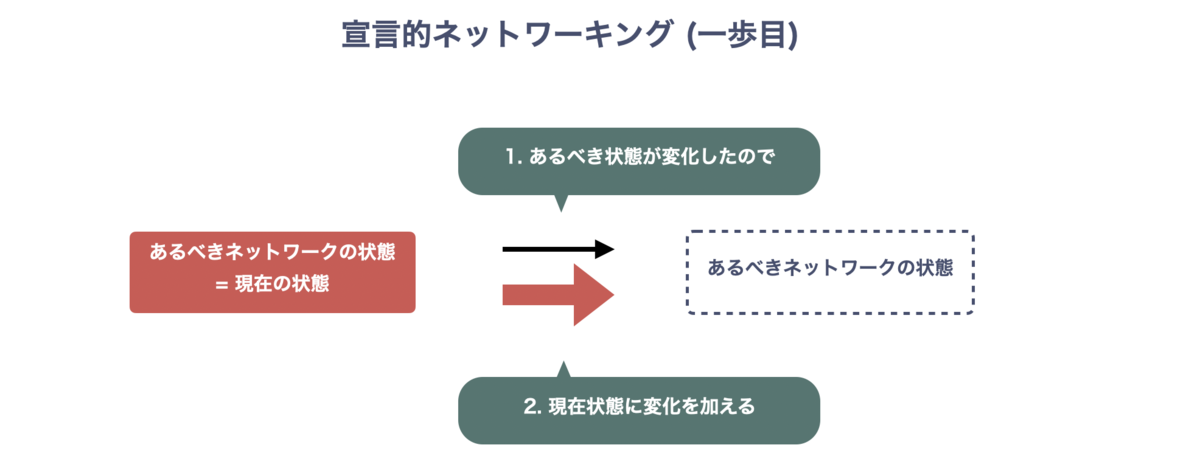

一歩目のゴールまでのポイントは3点で、
- あるべきネットワークの状態を抽象的に・宣言的に記述する
- あるべき状態が変わったら、変化に追随する
- 故障したら、あるべき状態の一歩手前 = 冗長度は低いが品質低下のない状態 まで遷移する
しかも 3 はネットワークプロトコルに任せることができるため、宣言的ネットワーキングの一歩目を踏み出すために複雑な制御システムは不要だと考えています。ここでのフォーカスは、
1. あるべき状態の記述方法と、その対象・抽象度の検討 2. 抽象的なあるべき状態の記述 (1) を、ネットワークデバイスが解釈できる設定・パラメーターに変換する機能 5. 差分を自動投入する機能
です。
なお、図中では
- 故障 (Outage) = ネットワーク自身が、自分で「壊れている」と判定できる状態
- 品質低下 (Service Degradation) = ネットワーク自身は「壊れている」判定できないが、制御システムから見れば品質を満たせていない状態
を明示的に区別しています。
ネットワーク設定は冪等で宣言的だが、問題は抽象度
さきほど抽象度を下げた宣言的記述「データセンターA にいるISP X からトランジット10G x 2 を買い、データセンターB に収容する」を例にしてみましょう。
ネットワークデバイスへの入力を便宜的に config で書けば
protocols {
bgp {
group x-transit {
type external;
metric-out igp;
export [ transit-out ];
remove-private;
neighbor 192.0.2.1 {
description "Transit X AS65000";
out-delay 1;
import [ transit-in AS65000-in ];
peer-as 65000;
}
}
}
}
policy-options {
policy-statement transit-in {
term default {
then {
community add transit;
local-preference 80;
next policy;
}
}
}
policy-statement transit-out {
term peer-routes {
from community [ customer ours ];
then accept;
}
}
policy-statement AS65000-in {
term match-exact {
from {
route-filter 198.51.100.0/24 exact;
}
then {
next policy;
}
}
then reject;
}
community ours members XXX:100;
community customer members XXX:110;
community transit members XXX:120
}
たとえばこのようになります。中身は適当で特に意味はありませんが、この例のようなネットワークの設定自体、ある条件を満たす限り 宣言的だと考えています。ある条件とは
- NETCONF や RESTCONF でいう candidate config を、atomic にcommit できること
- 存在しない設定は消えること
で、これを満たす限り ほとんどのネットワークベンダーの設定はあるべき状態の宣言であって、変化を与えるための命令ではないように見えます。 多くのネットワークデバイスは、設定されている状態に収束するよう ネットワークプロトコルを使って自律分散的に動作するからです。 同じ設定を投入しても変化はなく、冪等でもあります。
一方、ネットワーク設定の問題点は抽象度が低いことです。無数にあるパラメーターごとに個別に宣言する必要がありますが、あるべき状態は可能な限り抽象的に記述するのが望ましく、たとえば
peers: - type: transit neighbor_as: 65000 neighbor_address: 192.0.2.1 # これが物理と紐づいている priority: low
くらいまでは抽象化したいところです。 ここでは便宜的に yaml にしていますがたとえば RDBMS でもよく、データストアは本質ではありません。 「何を」「どのレベルの抽象度で記述するか」が本質です。これは各社のビジネスに深く依存するため、データ構造を共通化するのは困難であり、ビジネスの柔軟性のために自社で定義するのが望ましいと思っています。
さて、ここでは中間表現としてネットワークデバイス設定を例にしましたが、最終的に デバイスに設定を入れる = あるべき状態をAPIに入力する機能 とセットであり、必ずしも あるべき状態記述を設定に変換する必要はありません。 Ansible を使っている場合は あるべき状態を包括的に記述した playbook が中間表現になり、3rd party オーケストレーターを使っている場合は その API が期待する形式に変換する感じになります。
これらの中間表現は、特定業務を自動化するためだけの記述ではなく、ネットワークのあるべき状態を包括的に宣言したものである必要があります。 また、中間表現に冪等性があれば 投入時に差分計算する必要がなくなり、制御システムをより薄く保てます。
ここまでをまとめると、宣言的ネットワーキング (一歩目) に必要な
1. あるべき状態の記述方法と、その対象・抽象度の検討 2. 抽象的なあるべき状態の記述 (1) を、ネットワークデバイスが解釈できる設定・パラメーターに変換する機能 5. 差分を自動投入する機能
は、ざっくり言えば「なにかしらのテンプレートシステムを作りましょう」にすぎません。Reconciliation Loop を回す部分は、ネットワークプロトコルがやってくれます。
移行できるとしたら、どういうステップを踏めばよいか
まずは、抽象的な宣言からネットワークデバイスやミドルウェアが解釈できる中間表現を生成するための、テンプレートシステムを作りましょう、ということを書きました。
障害時には物理交換が発生するため、復旧プロセスも完全に自動化することは困難です。
宣言的ネットワーキングにおける制御システムの主な役割は QoS と最適化だと考えています
ということも書きました。最後の2点はこれまで棚上げしていた項目です。両方それなりに複雑になりそうなのですが、前者は実現可能だと思われます。

ひとつの案としては、回線やモジュールごとにビジネスに応じたメトリックを計測します。許容できるサービスレベルを宣言的に記述しておいて、
- サービスレベルを下回った場合、制御システムは回線やモジュールをサービスから切り離す
- 物理的に復旧した場合、制御システムはメトリックとサービスレベルを比較する
- OK であればサービスに組み込む
というアプローチは実装できそうです。
メトリック収集が複雑になりそうですが、これは従来のネットワーク運用でよく見るプロセスで、「人が手順にのっとって実施できることは、システム化できるのでは?」という話です。状態が自動遷移するようなシステムが理想ですが、ネットワークポリシーにそぐわないかもしれません。間にオペレーターの確認アクションを挟んでもよいと思います。
QoS や最適化はより複雑で、具体的なアイデアを持っていません。たとえば、あるIPアドレス間の latency をメトリックとして計測しているとして、原因区間の特定 (Root Cause Analysis) をシステム化するのがまず複雑です。仮に特定でき 原因が回線の輻輳であったして、「解消のためにTEしたところ 移した先で輻輳した」というケースもかなり見ます。ネットワーク全体の評価をスコアリングして、より高いスコアに収束させるような制御システムになるだろうと個人的には想像しています。システムが発散しないような仕組みも必要になります。
まとめ
従来のネットワーク運用を宣言的ネットワーキングに移行するのは、比較的カンタンだと考えています。ネットワークプロトコル自身が持つロバスト性と物理への強い依存を考慮すれば、テンプレートシステムの実装が一歩目で、経験的には、この簡易実装でさえコスト削減効果を上げられます。
一歩目の問題は、宣言の抽象度が低いことです。本来 宣言的に記述したい対象はサービス品質やコスト、さらに高レベルなビジネスの文脈なのですが、従来のネットワーク運用から移行可能なレベルまで宣言の抽象度を下げたにすぎません。しかしながら、こうすることで宣言的ネットワーキング(簡易版) にいったん移行し、徐々に宣言の抽象度を上げるというアプローチを取れます。
抽象度の高いところからスタートしようとすれば、まったく新しい制御システムの導入はもちろん、運用の見直しや 最悪の場合 ネットワークデバイスのリプレースが必要になるかもしれません。費用対効果しだいで こちらのアプローチのほうが有利なケースはもちろんあると思いますが、ネットワークを止めずにマイグレーションを繰り返していくような運用の観点からすれば、変化の歩幅が大きすぎるのでないかと感じています。
@motonori_shindo さんからフィードバックをいただきました。JANOG45 での議論 に登壇されていた方で、
QoS や最適化はより複雑で、
のところを掘り下げたブログエントリーを書かれています。
なるほど、ドメインをある程度限定すれば、ネットワーキングにも宣言性を持たせられるのかもしれませんね。ちょっと前に書いたブログで@codeoutさんの記事へのリンクを加えてアップデートさせていただきました。https://t.co/5ocYex7H4D
— Motonori Shindo (@motonori_shindo) 2020年7月7日