プログラムから高速に経路ルックアップするアプローチ
やりたいこと
開発中のプログラム内で、高速に経路ルックアップしたい場合があります。
私の場合、いま直面しているのは「netflow なり sflow なりを収集するとき、collector 側で経路ルックアップして Origin AS を解決したい」です。
デフォルトルートや MPLS を利用しているなど、そもそも exporter (ルーター / スイッチ) が必要な経路情報を持っていない場合があるためです。
TL; DR
- ホスト内に gobgpd が動いているという前提で gRPC する、簡易実装でベンチマークした
- ruby クライアントでも、 6k ルックアップ/s くらいはいけそう
- たとえば go にしても劇的に速くはならない
- 速いとは言えないが、間に合うケースもある気がする
- gobgpd に gRPC する簡易実装で、これ以上はつらそう
2018-06-08 追記
アプローチ
考えられるアプローチは大きく2つ。
- collector プロセスがフルルートを持つ
- collector プロセスが、bgpd の経路をAPI でルックアップする
それぞれ pros/cons を考えてみます。
- ネットワーク遅延の観点から、フルルートは collector ホスト内に持っておきたい
- フルルートの注入は BGP が楽
というのは共通です。
1. collector プロセスがフルルートを持つ
collector プロセスが外部のルーター(図中の右ルーター)と BGP セッションを張り、自分自身でフルルートの RIB を持つアプローチです。

この場合、問題になりそうなのは collector プロセスのスケールアウトでしょう。collector は fluentd + fluent-plugin-netflow (or fluent-plugin-sflow) あるいは goflow + flow-pipeline を想定しますが、1 ホスト上に複数プロセス待ち受けたいです。
複数 collector プロセスが 各々 TCP ポートを分けつつ同じ外部ルーターとピアできるかというと、疑問があります。 *1 一回ソフトウェアルーターで経路受信するなど 工夫が必要でしょう。
別の問題として、RIB の実装があります。Patricia Trie が一般的ですが、これを自前でやる必要があります。
実装は複雑そうですが collector としては良いパフォーマンスが期待できます。
2. collector プロセスが、API 経由で経路ルックアップする
collector プロセスが、ホスト内で動作する bgpd の API を利用して経路ルックアップするアプローチです。
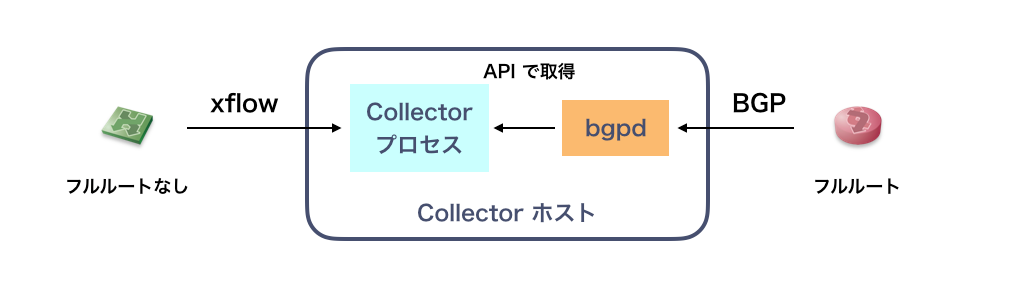
この場合、問題になりそうなのは bgpd の経路ルックアップパフォーマンスです。フルルートの注入に 10~20秒かかりそうなのはどちらのアプローチでも同じですが、bgpd の経路探索スピードは簡単にボトルネックになりえます。
一方で collector プロセスの実装はかなりシンプルになります。
まずトライするべきはこちらでしょうか。すごく高速に動く気はしませんが、十分なスピードで動いてくれる可能性はあります。
API で経路ルックアップできる bgpd (たとえば gobgpd)
まず思いつくのがgobgpd です。
今回は gobgpd に注目して、経路ルックアップのパフォーマンスを調査しますが… 「これもいけるらしいですよ」という実装がありましたら ぜひ教えてください!
ruby + gRPC で gobgpd 経路ルックアップ
collector として たとえば fluentd を利用する場合、ruby で gRPC することになります。
- MacBook Pro (Mid 2015) / Intel(R) Core(TM) i7-4980HQ CPU @ 2.80GHz
- ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-darwin16]
- grpc (1.12.0 universal-darwin)
- go1.10.2 darwin/amd64
- gobgpd v1.32
の環境で
$ gobgpd & $ gobgp global as 65000 router-id 10.0.0.1 listen-port 10179 $ wget http://archive.routeviews.org/route-views.wide/bgpdata/2018.06/RIBS/rib.20180604.0000.bz2 $ bunzip2 rib.20180604.0000.bz2 $ gobgp mrt inject global rib.20180604.0000
して
Table ipv4-unicast Destination: 704550, Path: 1394586
をロードし、以下の ruby クライアントから接続します。
$ gem install grpc-tools grpc
$ GOBGP_API=$GOPATH/src/github.com/osrg/gobgp/api
$ protoc -I $GOBGP_API --ruby_out=. --grpc_out=. --plugin=protoc-gen-grpc=`which grpc_tools_ruby_protoc_plugin` $GOBGP_API/gobgp.proto
$ bgpdump -M rib.20180604.0000 | grep 202.249.2.86 | awk -F \| 'NR%1000==0 { print $6 }' > routes
$ ruby -I. bench.rb
# bench.rb require 'benchmark' require 'ipaddr' require 'gobgp_pb' require 'gobgp_services_pb' def request(prefix) Gobgpapi::GetRibRequest.new( table: Gobgpapi::Table::new( family: Gobgpapi::Family::IPv4, destinations: [ Gobgpapi::Destination.new(prefix: prefix) ] ) ) end stub = Gobgpapi::GobgpApi::Stub.new('localhost:50051', :this_channel_is_insecure) stub.get_rib(request('1.1.1.1')) # The first call is super slow puts File.read('routes').split.map {|prefix| prefix = IPAddr.new(prefix).succ.to_s Benchmark.realtime { 10.times do stub.get_rib(request(prefix)) end } / 10 }.join(', ')
何をしているかというと、
- 1000 経路にひとつの割合で prefix をピックアップ
- prefix の先頭のアドレスについて、10回ルックアップ
- 平均の応答時間を出力
です。

横軸に prefix を並べていますが 値に意味はありません。「prefix が違っても応答時間はほぼ一定」という点がポイントです。gobgpd の RIB は単純な Hash であり、理屈は通っています。
さて、ここで気になるのは「longest match による経路ルックアップを、Hash でどのように実現しているか」ですね。たとえば 1.1.1.1 をルックアップした場合に 1.1.1.0/24 を返してほしい。
gobgpd (v1.32) では、若干力技の実装になっています。IPv4 であれば /32、/31、... のように prefix length を縮めながらマッチするまで探索します。RIB に存在する prefix そのものを探索した場合(赤) とRIB に存在しない longer prefix を探索した場合(緑) で特徴的な差があるのはこれが原因でしょう。
ここまでで、この環境なら ruby クライアントで 3~4k lookup/s くらいのパフォーマンスが期待できることがわかりました。
go + gRPC でgobgpd 経路ルックアップ
比較のために、go クライアントでも試してみます。goflow を利用する場合はおそらく go になるでしょう。
# bench.go package main import ( "github.com/osrg/gobgp/client" "os" "bufio" "github.com/osrg/gobgp/packet/bgp" "github.com/osrg/gobgp/table" ) func main() { client, _ := client.New("localhost:50051") fp, _ := os.Open("routes") scanner := bufio.NewScanner(fp) for scanner.Scan() { for i := 0; i < 10; i++ { client.GetRIB(bgp.RF_IPv4_UC, []*table.LookupPrefix{ &table.LookupPrefix{scanner.Text(), table.LOOKUP_EXACT}, }) } } }
$ go build bench.go $ time ./bench ./bench 0.81s user 0.76s system 112% cpu 1.399 total
これは 5k lookup/s くらいに相当しますが 劇的に高速になるわけではなさそうです。原因とししてはgRPC のオーバーヘッド、あるいは gobgpd 自身のパフォーマンスが考えられます。
一般に netflow / sflow には複数のフローエントリーが含まれ、さらに src ip address / dst ip address 双方を検索すると… 10 entries/flow としても flow packet あたり20回のルックアップが必要です。この場合 5k lookup/s = 250 pkt/s 程度であり、不安が残ります。
マルチスレッドで若干改善できるはず
ruby でも go でも遅いのですが、gRPC オーバーヘッドを考えるとマルチスレッド化することで改善が期待できるはずです。
たとえば ruby クライアントのスレッド数を 2 にすると
# bench.rb require 'benchmark' require 'ipaddr' require 'gobgp_pb' require 'gobgp_services_pb' require 'thread' def request(prefix) Gobgpapi::GetRibRequest.new( table: Gobgpapi::Table::new( family: Gobgpapi::Family::IPv4, destinations: [ Gobgpapi::Destination.new(prefix: prefix) ] ) ) end stub = Gobgpapi::GobgpApi::Stub.new('localhost:50051', :this_channel_is_insecure) stub.get_rib(request('1.1.1.1')) # The first call is super slow queue = Queue.new File.read('routes').split.each do |prefix| 10.times do queue << prefix end end puts Benchmark::CAPTION puts Benchmark::measure { threads = [] 2.times do threads << Thread.new { while !queue.empty? stub.get_rib(request(queue.pop)) end } end threads.each {|t| t.join} }
こんな感じなります。
1 スレッド
$ gobgp_performance $ ruby -I . bench.rb user system total real 0.877157 0.564896 1.442053 ( 1.707599)
2 スレッド
$ gobgp_performance $ ruby -I . bench.rb user system total real 1.139738 0.852233 1.991971 ( 1.258576)
若干ですが速くなっていますね。グラフにするとこんな感じ 👇 になります。

さらに ごくわずかですが処理をブロックしているスキマがありそうなので、ruby クライアント側で Origin AS をデコードしてみます。
def origin_as(table) path_attrs = table.table.destinations[0].paths.find {|p| p.best}.pattrs.map {|i| i.unpack('C*')} as_path = path_attrs.find {|a| a[1] == 2} case as_path[0] when 64 # 2 byte AS (as_path[-2] << 8) + as_path[-1] when 80 # 4 byte AS (as_path[-4] << 24) + (as_path[-3] << 16) + (as_path[-2] << 8) + as_path[-1] end end
クライアント側でデコードしているのは gRPC を待つ CPU 時間をデコードにあてたいからで、ruby でやっているのは FFI + GC を ruby <-> go 間で面倒みたくないためです。
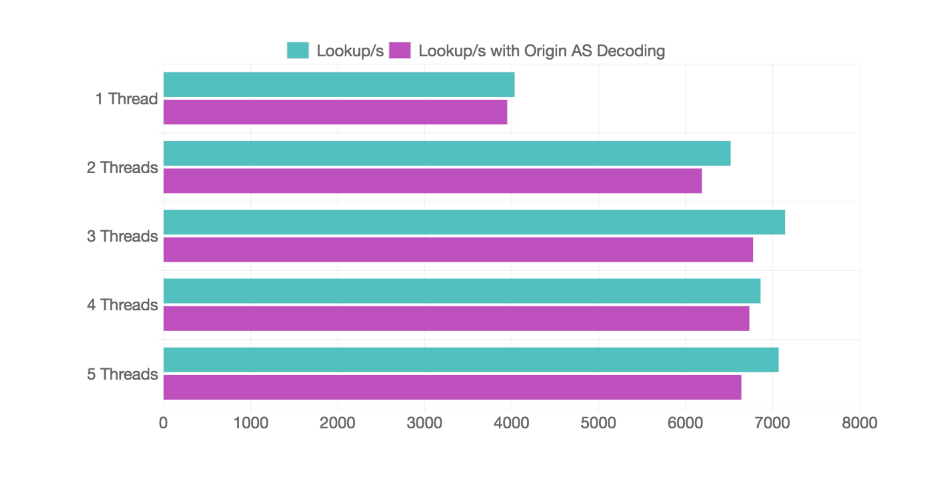
マルチスレッドにすることで、6k lookup/s くらいはいけそうです 🎉
まとめ
プログラムから経路ルックアップする場合のアプローチはいくつか考えられますが、簡易な実装で gobgpd を題材にベンチマークしてみました。
ruby クライアントであっても 6k lookup/s くらいのパフォーマンスは出そうですが、十分とは言えません。flow collector と一緒に使った場合、ここでつまる可能性があります。 しばらく運用してみて問題があったら RIB を内包するパターンの実装をトライする予定です。
また、実際の fluent plugin コード、flow-pipeline 向け kafka consumer は後日公開できるかもしれません。
2018-06-08 追記
tamihiro さんに「gobgpd の GetRib API、複数 prefix 渡せますよ」とご指摘いただき、再計測しました。
完全に見過ごしていた!

パラメーターが多くて見づらいのですが、1~5 スレッドごとに 8 本のバーチャートを引いてあり、上から順に
| gRPC あたりの prefix 数 | Origin AS デコード |
|---|---|
| 1 | ❌ |
| 1 | ⭕️ |
| 5 | ❌ |
| 5 | ⭕️ |
| 10 | ❌ |
| 10 | ⭕️ |
| 20 | ❌ |
| 20 | ⭕️ |
です。
- worker スレッドを増やしても さほど効果はないのは同じ
- gRPC あたりの prefix 数を増やす = gRPC 数を減らす と劇的にパフォーマンス改善する
- gobgpd の経路ルックアップというよりは、gRPC オーバーヘッドが効いていたと予想できる
- クライアントでOrigin AS デコードした場合、ある程度のところまではいくが頭打ちになる
という結果です。私には reasonable に見えます。
いずれにせよ、カンタンに 4~5倍 のスピードが手に入りました。🎉 ご指摘ありがとうございました!
inet-henge で、好みのネットワーク図を描くヒント
2020-02-25追記: SVG DOM が変更になったため、この記事のCSS ではスタイルが壊れるかもしれません。こちら も参考にしてください。
「構成管理DB から自動でネットワーク図を描く」というコンセプトで、inet-henge というライブラリを開発しています。
ネットワークは日々変化しますが、ネットワーク図の更新が面倒です。「このデバイスはあのデバイスとつながっている」くらいの接続情報の集まりから、オートレイアウトでネットワーク図を描きたい。これがモチベーションです。
ここでは、最近入った機能を使って 好みのネットワーク図を描くためのヒントを紹介します。
計算結果のキャッシュ
描画のたびに計算結果である位置情報をキャッシュし、それをヒントにすることで2回目以降の表示が高速になりました。
- キャッシュはブラウザに保存される
- 入力データが変わった場合はキャッシュを使わない
キャッシュを参照せず常に計算を行うには、次のように positionCache オプションを false にします。
<script> var diagram = new Diagram('#diagram', 'bar.json', {positionCache: false}); diagram.init('bandwidth', 'interface'); </script>
計算ステップ数を調整する
2回目以降はキャッシュを使えるという前提のもと、計算ステップを増やすことで よりよい配置を得つつ (2回目以降の) 表示速度を落とさない、ということが可能になりました。
このオプションを理解するために、内部で利用している D3.js のforce layout について説明します。
force layout はノード間に引力や斥力が働く場を想定し、初期配置から小刻みに時間ステップを進めながらノード配置を計算して収束させるD3.js モジュールです。ノード数やリンク数が増えるにつれ、一般的には収束までに必要な時間ステップ数が増加します。よりよいネットワーク図を得る代わりに表示時間が長くなるトレードオフがあったわけです。
これについて、過去のinet-henge では 最大時間ステップ数 = 1000 を決め打っていました 💦
表示のたびに再計算する仕様 & スピード優先 でした。
ここが可変になり、ネットワーク規模に合わせたステップ数を設定できます。デフォルトは今まで通りの 1000 です。
<script> var diagram = new Diagram('#diagram', 'bar.json', { ticks: 2000 // 2000 ステップまで計算する }); diagram.init('bandwidth', 'interface'); </script>
CSS スタイリング
次のようなJSONデータを
{ "nodes": [ { "name": "POP1-A" }, { "name": "POP1-B" }, { "name": "POP2-A", "icon": "https://inet-henge.herokuapp.com/images/router.png" }, { "name": "POP2-B", "icon": "https://inet-henge.herokuapp.com/images/router.png" }, { "name": "POP3-A", "icon": "https://inet-henge.herokuapp.com/images/router.png" } ], "links": [ { "source": "POP1-A", "target": "POP1-B", "meta": { "interface": { "source": "ge-0/{0,1}/0", "target": "Te0/{0,1}/0/0" }, "bandwidth": "20G" } }, { "source": "POP2-A", "target": "POP2-B", "meta": { "interface": { "source": "ge-0/{0,1}/0", "target": "Te0/0/{0,1}/0" }, "bandwidth": "20G" } }, { "source": "POP1-A", "target": "POP2-A", "meta": { "interface": { "source": "ge-0/0/1", "target": "Te0/0/0/1" }, "bandwidth": "10G" } }, { "source": "POP1-B", "target": "POP2-B", "meta": { "interface": { "source": "ge-0/0/1", "target": "Te0/0/0/1" }, "bandwidth": "10G" } }, { "source": "POP3-A", "target": "POP2-B"} ] }
次のHTMLのように描画するとします。
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <script src="https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.17/d3.js"></script> <script src="https://inet-henge.herokuapp.com/js/cola.min.js"></script> <script src="https://inet-henge.herokuapp.com/js/inet-henge.js"></script> </head> <body> <div id="diagram"></div> </body> <script> var diagram = new Diagram('#diagram', 'bar.json', { pop: /^([^\s-]+)-/ }); diagram.init('bandwidth', 'interface'); </script> </html>
デフォルトで左のような図になりますが、右のようにCSS で要素ごとにスタイルを変えることが可能です。
- グループ、ノード、リンク全体にスタイルを当てる
- 特定グループにスタイルを当てる (
POP1) - 特定ノードにスタイルを当てる (
POP1-A) - 特定リンクにスタイルを当てる (
POP1-A-POP1-B間)
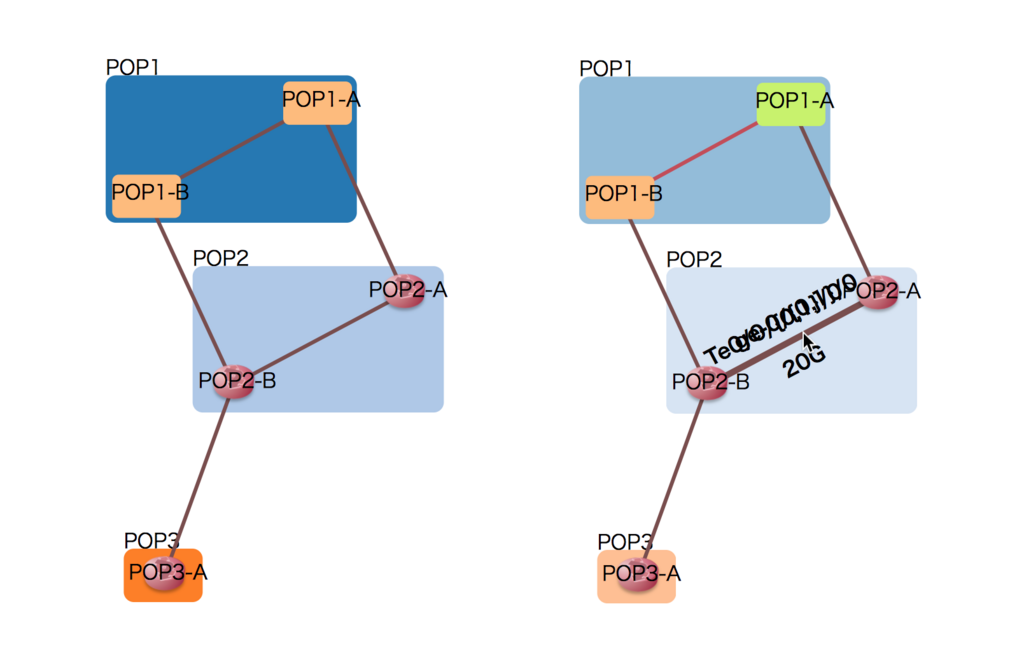
下のCSSは、右の図を出力するサンプルです。
配色を変えているのに加え、リンクにマウスオーバーすると強調表示するようになっています。
(リンクラベルが重なって読めませんが、後ほど調節します)
.group rect { opacity: 0.5; } .node, .group rect { cursor: move; } /* 特定 node, link のみスタイルを当てる */ .group.pop1 rect { fill: #4ecdc4 !important; } .node.pop1-a rect { fill: #c7f464 !important; } .link.pop1-a-pop1-b { stroke: #c44d58; } /* リンクにマウスオーバーすると、リンクを太く & ラベル表示 */ .link:hover { stroke-width: 5px; } .link:hover ~ .path-label { font-weight: bold; visibility: visible !important; }
リンク長さの調節
先ほどの例で、マウスオーバーしたときのリンクラベルが重なっていました。
これは、次のようにリンク長さを調節することで解決できます。
<script> var diagram = new Diagram('#diagram', 'bar.json', { pop: /^([^\s-]+)-/, distance: function(force) { force.jaccardLinkLengths(100, 2); } }); diagram.init('bandwidth', 'interface'); </script>
- ジャッカード距離を計算に使う
- 共通ノードを持たないノード間の、ベースとなる長さを
100 - ジャッカード距離に対する係数を
2
としています。
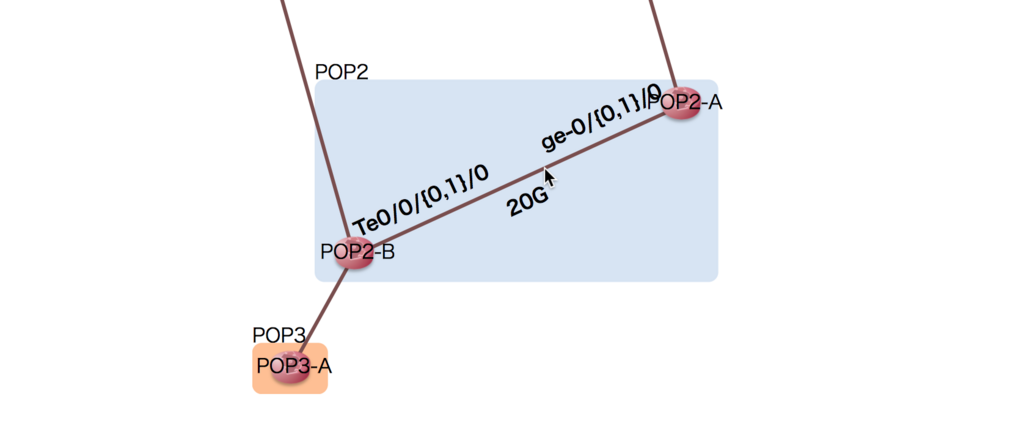
描画したい ノード数、リンク数 によっていい感じのパラメーターが変わってきますので、「見づらいな」と感じたら時々調節してみることをオススメします。
(調節はコンセプトに反するので、ラベルの重なり検知は課題のひとつ💪)
ネットワークステータスの反映
下のように、障害のあるルーターやリンクを強調表示できます。
データ:
{ "nodes": [ { "name": "POP1-A" }, { "name": "POP1-B" }, { "name": "POP2-A", "icon": "https://inet-henge.herokuapp.com/images/router.png" }, { "name": "POP2-B", "icon": "https://inet-henge.herokuapp.com/images/faulty_router.png" }, // アイコン差し替え { "name": "POP3-A", "icon": "https://inet-henge.herokuapp.com/images/router.png" } ], "links": [ { "source": "POP1-A", "target": "POP1-B", "meta": { "interface": { "source": "ge-0/{0,1}/0", "target": "Te0/{0,1}/0/0" }, "bandwidth": "20G" } }, { "source": "POP2-A", "target": "POP2-B", "meta": { "interface": { "source": "ge-0/{0,1}/0", "target": "Te0/0/{0,1}/0" }, "bandwidth": "20G" } }, { "source": "POP1-A", "target": "POP2-A", "meta": { "interface": { "source": "ge-0/0/1", "target": "Te0/0/0/1" }, "bandwidth": "10G" } }, { "source": "POP1-B", "target": "POP2-B", "meta": { "interface": { "source": "ge-0/0/1", "target": "Te0/0/0/1" }, "bandwidth": "10G" } }, { "source": "POP3-A", "target": "POP2-B", "class": "fault" } // クラス指定 ] }
CSS:
.link.fault { stroke: #c44d58; stroke-dasharray: 5, 5; }
出力:
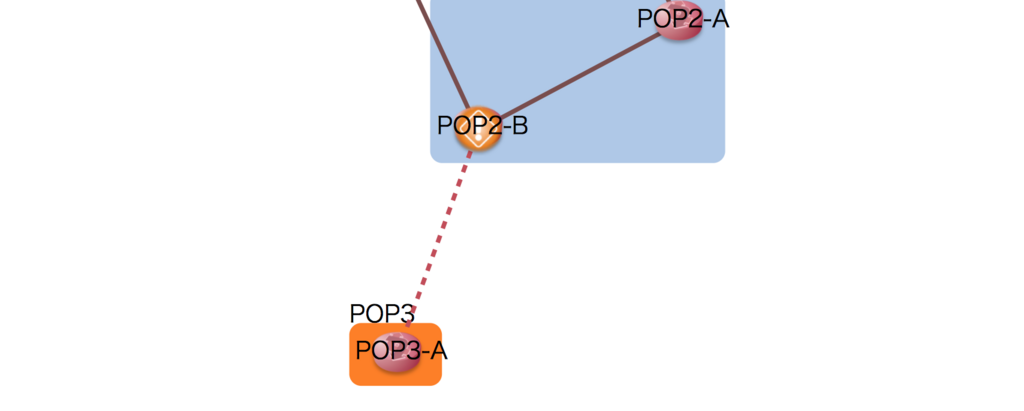
ノードはアイコンの差し替えを、リンクは class 属性の追加によりスタイルを操作します。
補足: ほかのCSS ヒント
CSS スタイリングについて、別の記事も書きました。こちらも参考にしてみてください。
補足: JANOG41 で登壇しました
ずいぶん経ってしまいましたが、JANOG41 でinet-henge について話してきました。
LT で、事前投票 上位のトークが採択されるシステムでしたが…なんと一位 🎉🎉🎉
会期中やその後に「使ってみました」「ここ、こうなりませんか?」などなど多数のフィードバックを頂きまして、めちゃくちゃ有意義なミーティングでした。ありがとうございました!
今回紹介したヒントのほとんどが、そのときの話を参考に実装したものです。
まだまだフィードバックお待ちしてます!
JUNOS 17.2 の PEGパーサーで文法チェックする
ネットワーク運用のために、生成した / 手書きしたコンフィグを CIでテストしています。
おおよそ次のような単純なワークフローです。
乱暴に「コンフィグをテスト」と言いましたが、ここでは文法チェックを指しています。わざわざパーサー書くほど? 意味あんの? と思ってしまいますが、その理由は後ほど。
junoser
PEG パーサー + CI による文法チェックを実現するため、junoser というライブラリーをメンテしています。内部にコンフィグ構文木を持ち、JUNOS を使わず文法チェックしてくれるものです。
NETCONF(XML RPC) のスキーマからCLI 構文が連想できるという特徴を利用し、NETCONF XSD から構文木を生成しているのですが、この文法のもとになる XSD が JUNOS 17.2 になりましたよ、という話です。
JUNOS 17.2 になって変わった点
変更前は 12.1 でした。古い…
サポートされる文法が大幅に増えた
どれだけ増えたかは表現しづらいのですが、例えばサイズでいうと
| Version | Lines of XSD | MB |
|---|---|---|
| 12.1 | 616,701 | 27 |
| 17.2 | 1,674,019 | 76 |
行数、ファイルサイズとも x2.7 くらいの分量です。
より厳密な構文木を作れるようになった
interfaces xe-0/0/0 description foo
たとえばこの文法の例でいえば JUNOS 12.1 では次のような XSD でした。
<xsd:complexType name="interfaces-type"> <xsd:sequence> <xsd:element name="name"> <xsd:complexType> <xsd:simpleContent> <xsd:restriction base="key-attribute-string-type"> <xsd:enumeration value="interface-name"> <xsd:annotation> <xsd:documentation>Interface name</xsd:documentation> <xsd:appinfo> <flag>mustquote</flag> <flag>text-choice</flag> <flag>current-product-support</flag> </xsd:appinfo> </xsd:annotation> </xsd:enumeration> </xsd:restriction> </xsd:simpleContent> </xsd:complexType> </xsd:element> <!-- </name> --> <xsd:choice minOccurs="0" maxOccurs="unbounded"> <xsd:element ref="undocumented" minOccurs="0"/> <xsd:element ref="junos:comment" minOccurs="0"/> ... <xsd:element name="description" minOccurs="0" type="xsd:string"> </xsd:element> <!-- </description> --> </xsd:choice> </xsd:sequence> </xsd:complexType>
<xsd:element name="name"> の部分に注目してください。この要素、CLI 上 name というキーワードが必要なのか、不要なのか XSD からは判別不能でした。そのためライブラリ内部で文脈ごとに独自判断し、構文木を生成していました。
「ベタな文法はサポートされているが、マニアックな文法はサポートされない」「パッチがモグラ叩きのよう」だったのはこのためです。
いっぽう、 17.2 では次のような XSD になっています。
<xsd:complexType name="interfaces-type"> <xsd:sequence> <xsd:element name="name"> <xsd:annotation> <xsd:appinfo> <flag>identifier</flag> <flag>nokeyword</flag> <!-- !!! --> <flag>current-product-support</flag> <identifier/> </xsd:appinfo> </xsd:annotation> <xsd:complexType> <xsd:simpleContent> <xsd:restriction base="key-attribute-string-type"> <xsd:enumeration value="$junos-interface-ifd-name"> </xsd:enumeration> <xsd:enumeration value="interface-name"> <xsd:annotation> <xsd:documentation>Interface name</xsd:documentation> <xsd:appinfo> <flag>mustquote</flag> <flag>nokeyword</flag> <!-- !!! --> <flag>text-choice</flag> <flag>current-product-support</flag> </xsd:appinfo> </xsd:annotation> </xsd:enumeration> </xsd:restriction> </xsd:simpleContent> </xsd:complexType> </xsd:element> <!-- </name> --> <xsd:choice minOccurs="0" maxOccurs="unbounded"> <xsd:element ref="undocumented" minOccurs="0"/> <xsd:element ref="junos:comment" minOccurs="0"/> <xsd:element name="description" minOccurs="0" type="xsd:string"> ... </xsd:element> <!-- </description> --> </xsd:choice> </xsd:sequence> </xsd:complexType>
nokeyword フラグにより「name はCLI キーワードではなく XSD 的なプレースホルダーですよ」ということが判別可能になっています。
なお、16.X の XSD を確認していないため もう少し早い段階で nokeyword フラグが導入されていたかもしれません。
ほんの一例ですが、このようなスキーマ定義の改善によって より厳密な構文木が生成できるようになりました。その結果、モグラ叩き的パッチがマシになると期待できます。
しかしながら、おそらくパッチはゼロにはなりません。 XSD にバグがあるためです。
- CLI には存在するが、XSD に存在しない文法がある
- 必要なフラグが記述されていない
など、JUNOS 17.2 ベースのjunoser でもいくつか独自対応しています。サポートされない文法がありましたら、お気軽にコンタクトください。おそらくさくっとパッチできると思います。
遅くなった 😫
JUNOS 12.1 と17.2 で、
- XSD の行数
- XSD から生成したjunoser のパフォーマンス (秒間の処理コンフィグ行数)
を比較します。
今回 17.2 に上げると同時に、取得元プラットフォームを vSRX → vMX に変更しました。いくつかの組み合わせでプロットしたものが下のチャートです。
なお、JUNOS 15.1 の XSD は理解できなかったため、そのバージョンのjunoser を生成できていません。

XSD が x2.7 倍になったことにより、残念ながらパフォーマンスは 1/2.7 になっていることが分かります 😢
TODO
さきほど少し触れたように、おそらくXSD のバグによってサポートできていない文法が存在します。モグラ叩きはしばらく続きそうです。Juniper 社にフィードバックできるチャンスがあれば、XSD について報告したいと思っています。
最適化も必要です。たかだか2,000行くらいの設定ファイルに10秒オーダーかかってしまいます。
現在のところruby による実装ですが、go への移植も含めて検討する予定です。
また XSD 行数から想像すると、恐ろしいことに…プラットフォームによって XSD が全く異なるようです。 ユニバーサルなパーサーを生成するためには XSD をマージしないといけない可能性があります。
なぜPEG パーサーで文法チェックをするのか
最後に、後回しにしていた PEG パーサーの必要性について。
junoser の話をすると、割と「それは検証機でやればいいのにw」という反応をされます。
検証機を使った場合、junoser では不可能な文脈のチェック、たとえば「定義されていないポリシーを呼びだしている」ようなことも確認できます。それは素晴らしいことなのですが 残念ながらコストに合わないんですよ、という話をします。
ネットワークエンジニアリングの場合、たとえば実機で単体テストを行い 接続したシミュレーターとルーティングプロトコルを走らせて通信まで確認できたとしても、十分な安心感がありません。標準どおり / 期待通りに動作することはテストできても、通信相手 (場合によっては会社が違う) である特定のハードウェアと思ったように通信できるとは限らないためです。残念なことに それほどデバイスごとの癖に悩まされます。
仮にハードウェアがすべて標準どおりに動き、ベンダー間の相性問題が皆無だとしても AS(自社ネットワーク)全体として想定通りに動作するとは限りません。ネットワークデバイスはルーティングプロトコルによって互いに影響を及ぼし合います。その連鎖のぐあいは、なかなかに想像を超えてきます。
ネットワークの端っこのデバイスをちょこっといじると、通信もしてないし全く関係ないと思われた反対のほうでトラブルが! みたいな予想外の事故にビビりながら運用しています。ネットワークが変にコケると 上に乗っているシステムやサービスを巻き込む可能性が高いため、とても神経質になります。
反対のほうでトラブルが! の「反対のほう」は、場合によっては USの西海岸とかだったり いくつか通信事業者をまたいだ向こうだったりするため、正直「やってみないと分からん」といったことも山ほどあります。
ネットワークエンジニアリングでは、肌感覚として気軽にテストすることが困難です。正確には、気軽にできるテストで得られる安心感は限定的。「ある変更を加えた結果 全体としてどうか」を確かめないと安心を得られない、さらにはあまり事故れないことから、テストセットアップが大規模になり投資コストや人的リソースがかかりがち。テスト自動化はやるべきですが、それによって削減できるのは人的リソースのみです。いずれにせよ投資が必要。
ようやく本題ですが、直接収益を産まないわりに Lab環境は高価です。それを文法チェックごときに使いたくない。しかしながらそれをサボると、限られたメンテナンスウィンドウ中に Typo と戦うハメになります。なので、なるべく凡ミスは安い・カンタン・速い方法で対処するべきだ という思いがあります。
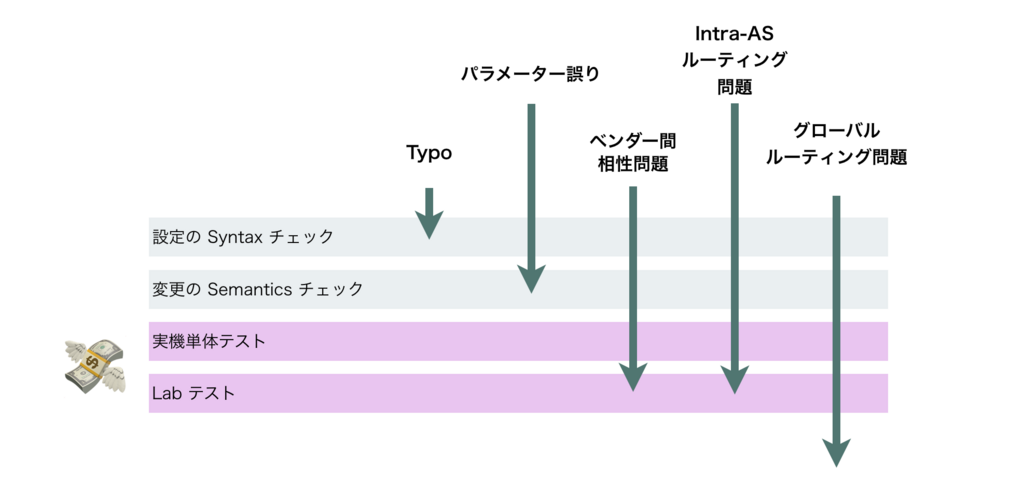
重い問題、たとえばベンダー間の相性やIntra-ASのルーティングは高価な Labテストで拾うしかありませんが、軽い Typo は安く速く潰したい。
こういうモチベーションで junoser をメンテしています。IOS-XR でも同じことをやりたいのですが、それはまた別の話。
お願い
さまざまなJuniper プラットフォーム、バージョンごとのxsd を求めています。相談に乗ってもいいよという方、是非ともご連絡ください!
パブリックデータから経路リークを探る
2017/08/25 12:30 (JST) ごろ、日本国内で大規模な通信障害が観測されました。
通信障害の内容について、とても詳細にまとめられている記事があります。
障害の内容はさておき、このエントリでは障害のしくみについて探ってみようと思います。
MRT Dump から見るBGP Update 数の急増
MRT Dump をもとに、該当時刻のBGP Update 数(毎分) をバーチャートにしました。

- 横軸: 時刻(UTC)
- 縦軸: BGP Update されたのべPrefix 数
- 正: NLRI
- 負: Withdraw
単純にBGP Update の回数をカウントしているため、Path Attribute だけの変更だったり、NLRI → Withdraw → 同じNLRI の場合でも すべて1回と数えています。
普段と比べるとUpdate 数が激増している期間があります。03:23 ~ 03:35 (UTC) の間です。
報道によれば「8分以内に正しい情報に修正した」とのことですが、実際にはすぐにBGP Update が収束しているわけではなさそうで、AS2497 からの経路変化でみると 発生(03:23) ~ 収束(03:34) とすこし時間幅が大きくなっています。これはおそらく経路を仲介しているAS の設計に依存し、MRAI などで伝搬を遅延させる影響を受けていると考えられます。
意図せずトランジットされた経路数はおよそ10万経路。直接の影響を受けたASは3000程度。また、通信先がこの吸い込みに影響されていた場合には直接影響のあったASではなくても多くの利用者がおかしいなあと思ったはず
— Yoshinobu Matsuzaki (@maz_zzz) 2017年8月25日
トータルでおおよそ10万経路が影響を受けていることは、MRT Dump からも観測できます。
route_leak=# SELECT count(DISTINCT prefix) FROM updates WHERE ix='wide' AND neighbor_as=2497 AND time > '2017-08-25 03:23'::TIMESTAMP AND time < '2017-08-25 03:35'::TIMESTAMP; count -------- 114965 (1 row)
経路の急増が引き起こす問題
現在 IPv4 経路数はおおよそ70万弱とされているため、フルルートが一時的に 70万→80万 に増加したことになります。運悪くちょうどRIB / FIB キャパシティが限界を迎えることは十分ありえます。
この影響により、バックボーンルーター(ISP間など上位ネットワークで通信を行う装置)が、全体的に高負荷な状況に陥り、結果として16:16頃、弊社サーバー群と繋がるバックボーンルーターの一部が停止いたしました
http://hiroba.dqx.jp/sc/news/detail/a495eebbfa243b79c5b9b224c482d0c2/
限界値はさまざまですが、
どちらの場合もルーターが不安定になったり、あるネットワークに通信できなくなったりします。
これは問題の原因のひとつと思われますが、これにあたった事業者はおそらく少数なのでは?と想像しています。
経路の中身は?
次のテーブルは観測されたAS_PATH の一例です。一部報道のとおり、AS15169 (Google) が経路をトランジットしているのがわかります。
route_leak=# SELECT aspath, count(distinct prefix) FROM updates WHERE ix='wide' AND neighbor_as=2497 GROUP BY aspath ORDER BY count DESC LIMIT 10; aspath | count ---------------------------+------- 2497 701 15169 4713 | 24831 2497 701 15169 7029 | 7308 2497 701 15169 8151 | 4639 2497 701 15169 9121 | 4606 2497 701 15169 9264 1659 | 3014 2497 701 15169 9394 | 2129 2497 701 15169 3209 | 1757 2497 701 15169 7303 | 1580 2497 701 15169 4230 28573 | 1475 2497 701 15169 7545 | 1420 (10 rows)
少しおかしいですね。AS4713 (OCN) がAS15169 (Google) を介してインターネット接続しているかのようなAS_PATH です。
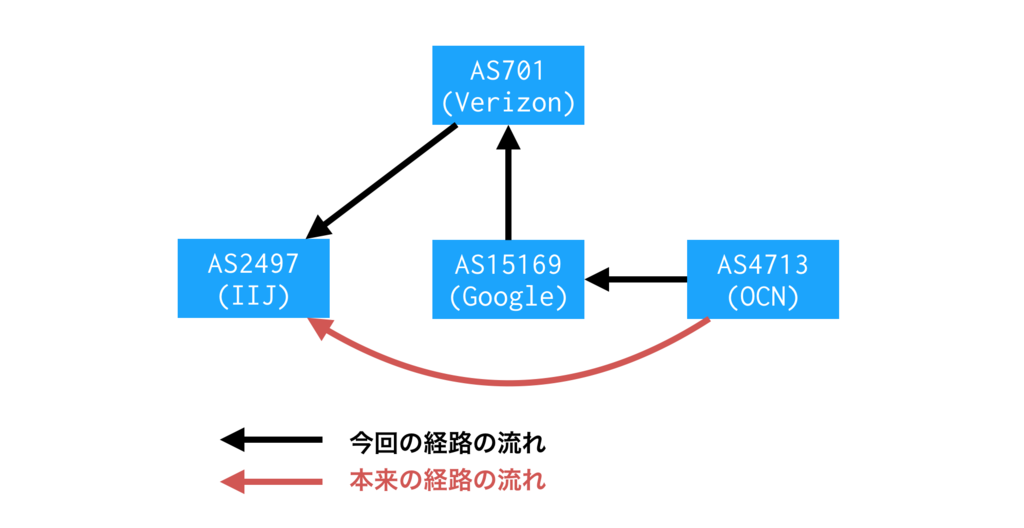
AS15169 (Google) から見るとAS4713 (OCN) はピアであり、本来であればトランジットであるAS701 (Verizon) に経路広告するべきではありません。このような経路が10万あったということですね。
注: 正確に言えば広告しても構わないのですが、流れてくるトラフィックをさばける回線キャパシティを担保するべきです。
AS701 に流れた経路は、そのままAS2497 (IIJ) に流れます。では、AS2497 はその経路をベストパスとして選択し、パケット転送するでしょうか?
通常ならAS_PATH 勝負で負けるため この経路がベストになることはありませんが、実はこの経路 Prefix Length が違っていました。
route_leak=# SELECT masklen(prefix) AS len, count(distinct prefix) FROM updates WHERE ix='wide' AND neighbor_as=2497 AND aspath ='2497 701 15169 4713' GROUP BY len ORDER BY count DESC LIMIT 10; len | count -----+------- 24 | 16594 22 | 3035 23 | 2432 21 | 1764 20 | 868 19 | 79 16 | 29 18 | 15 17 | 10 15 | 3 (10 rows)
OCN クラスのISP であれば/12 ~ /20 くらいの大きなPrefix でルーティングすることが多いですが、障害中に観測された経路は/24 が大半です。Longest Match ルールにのっとってこの経路がベストになった、ということは容易に想像できます。
経路の中身について、ここまでまとめ
8/25 の障害時には、一例として AS2497 (IIJ) は「AS4713 (OCN) へのベストパスはAS15169 (Google) 経由」としていたことがMRT Dump から読み取れました。
ここからは想像ですが、10万経路ぶんのトラフィックがAS701、AS15169 に向かったため、
- 通信路のどこかで輻輳する
- 事業者の通信ポリシーによって通信が遮断される
- 遅延が増える (AS701、AS15169 は日本とは限らない)
ことが考えられます。
OCN と IIJ は一例であることに注意
ここまでIIJ → OCN 向きのトラフィックで説明しましたが、これは一例です。始点はIIJ に限らず、終点はOCN に限りません。アイボール側、コンテンツ側、どちらが影響を受けても通信が成り立たないことに注意です。
また、このエントリはMRT Dump を出発点にしています。限られた情報であり、障害時に起こっていた経路変化がすべてDump されているとは思えない = 見えていない影響も当然あると思われます。
大量の/24 はどこから来たか?
MRT Dump 上でみると、これら/24 のOrigin AS は4713 です。「4713 がOriginate した」と考えるのが自然です。
BGPMON の記事 でもそう考察されています。
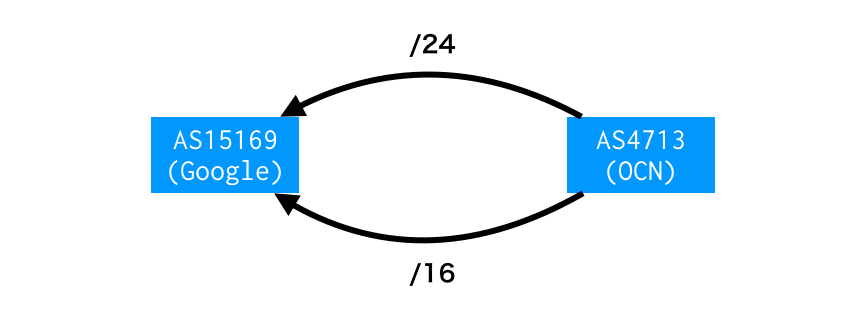
ピアリング回線が複数あり、特定のトラフィックを特定の回線に乗せるためのトラフィックエンジニアリングですね。「経路はふつうAS15169 で止まるが、誤ってリークした」というのはありそうです。
いっぽう、AS4713 以外の事業者が生成している可能性ありそう、とも考えています。
「途中の事業者がPrefix を分割する」ようなケースです。ふつうはあまりやらないTE ですが、可能性を考えるためにAS15169 の右隣 != Origin AS なAS_PATH に注目してみましょう。観測されたAS_PATH のうち15169 より右を抜き出します。
route_leak=# SELECT substring(aspath from '15169.*') AS path, count(distinct prefix) FROM updates WHERE ix='wide' AND neighbor_as=2497 GROUP BY substring(aspath from '15169.*') ORDER BY count DESC LIMIT 10; path | count ------------------+------- 15169 4713 | 24831 15169 7029 | 7308 15169 8151 | 4639 15169 9121 | 4606 15169 9264 1659 | 3014 15169 9394 | 2129 15169 3209 | 1757 15169 7303 | 1580 15169 4230 28573 | 1475 15169 7545 | 1420 (10 rows)
たとえば 15169 9264 1659。 Prefix でいうと61.60.96.0/24 など。
RIPEstat によれば、この経路は障害発生中にのみ存在しています。
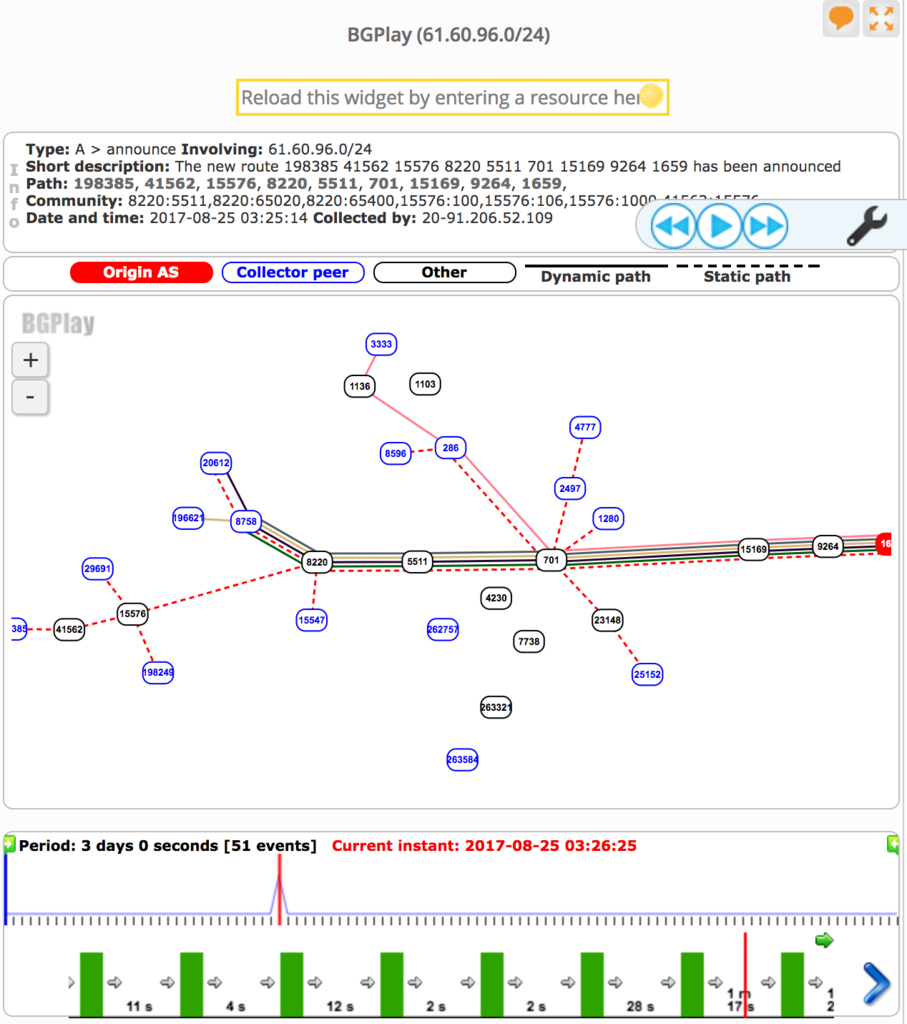
あくまで想像の域を出ませんが、次のような可能性も考えられます。
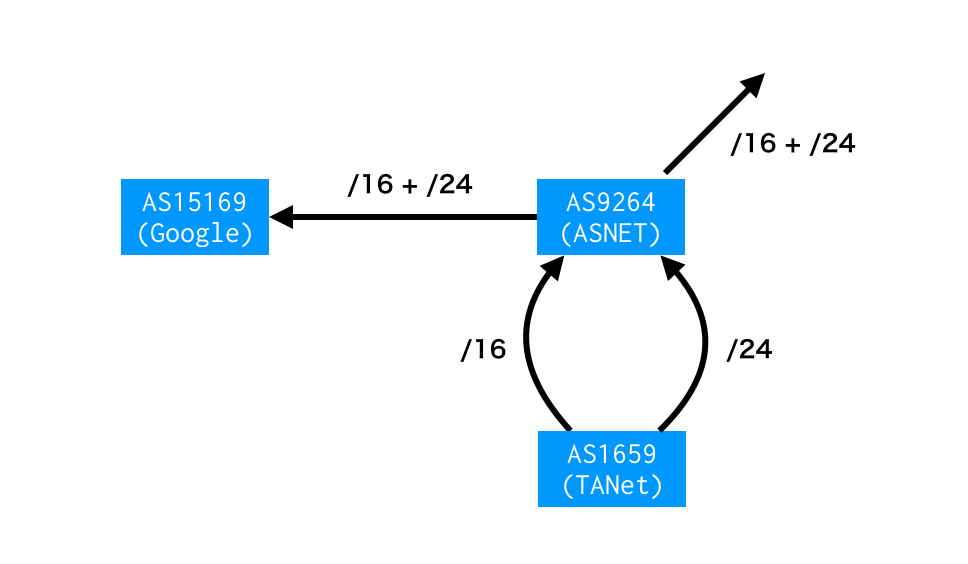
経路だけをみれば、AS1659 (TANet) はAS9264 (ASNET) との間に複数回線もち、BGP によるTE を行なっているようです。この影響がAS15169 (Google) に漏れ聞こえ、インターネットに広告されているわけですが、この経路は障害のあった時間帯しか存在しません。
通常のルーティングとしては何か不自然です。AS9264 が他にも広告するためインターネットで常に観測されそうなのに、それがない。どちらかといえば、想像ですが「間の事業者が内部利用のために経路を生成した。それが漏れてしまった」と考えるほうがしっくりきます。
このように障害中のみ観測された経路、かなりの数あるようです。
海外に目を向ける
では、日本以外ではどうでしょう?
Route Views Project はグローバルにコレクターを配置しており、一部海外IX での経路変化を記録しています。
障害のあった期間中のBGP Update 総数を数えてみれば影響のあった事業者、なかった事業者のあたりをつけることができます。次のテーブル中で、count が小さいAS (neighbor_as) ほど影響が軽微だったと考えられます。
(count は観測されたBGP Update のユニークprefix 数、neighbor_as はRouteViews コレクターとピアしているneighbor AS )
route_leak=# SELECT ix, neighbor_as, count(distinct prefix) FROM updates GROUP BY ix, neighbor_addr, neighbor_as ORDER BY ix, count DESC; ix | neighbor_as | count ----------+-------------+-------- 3 | 286 | 101331 3 | 45352 | 5 3 | 134708 | 3 3 | 5645 | 3 3 | 6939 | 3 3 | 40387 | 3 4 | 45177 | 97396 4 | 48526 | 85617 4 | 38726 | 75787 4 | 34288 | 74560 4 | 36236 | 74365 4 | 24482 | 8 4 | 24516 | 7 4 | 24516 | 7 4 | 63956 | 5 4 | 38883 | 3 4 | 58682 | 3 4 | 58511 | 3 4 | 58511 | 3 4 | 58511 | 3 4 | 38726 | 3 4 | 1351 | 3 6 | 31019 | 100 6 | 53364 | 10 eqix | 3257 | 10 eqix | 41095 | 4 eqix | 11039 | 3 eqix | 6939 | 3 isc | 2497 | 114601 isc | 6939 | 3 linx | 41695 | 91612 linx | 34288 | 74560 linx | 37271 | 98 linx | 37271 | 98 linx | 58511 | 28 linx | 58511 | 28 linx | 3257 | 10 linx | 13030 | 5 linx | 13030 | 5 linx | 14537 | 4 linx | 6667 | 3 linx | 6939 | 3 linx | 37271 | 3 linx | 58511 | 3 linx | 37271 | 3 linx | 58511 | 3 nwax | 1798 | 98 nwax | 15301 | 3 nwax | 54073 | 3 oregon | 2497 | 114973 oregon | 286 | 101781 oregon | 701 | 98183 oregon | 7660 | 94091 oregon | 23673 | 8 oregon | 393406 | 7 oregon | 62567 | 7 oregon | 31019 | 5 oregon | 1221 | 5 oregon | 13030 | 5 oregon | 37100 | 4 oregon | 40191 | 4 oregon | 3303 | 4 oregon | 11686 | 4 oregon | 20912 | 3 oregon | 6762 | 3 oregon | 6939 | 3 oregon | 8492 | 3 oregon | 57463 | 3 oregon | 58511 | 3 oregon | 18106 | 3 oregon | 54728 | 3 oregon | 293 | 3 oregon | 47872 | 1 perth | 24516 | 5 saopaulo | 262757 | 93512 saopaulo | 53013 | 19034 saopaulo | 53013 | 18707 saopaulo | 262612 | 18692 saopaulo | 52863 | 16650 saopaulo | 28138 | 11 saopaulo | 52940 | 7 saopaulo | 28571 | 7 saopaulo | 262354 | 7 saopaulo | 262750 | 7 saopaulo | 52888 | 7 saopaulo | 264268 | 7 saopaulo | 263047 | 4 saopaulo | 52720 | 4 saopaulo | 1916 | 4 saopaulo | 262317 | 4 saopaulo | 26162 | 4 saopaulo | 263945 | 4 saopaulo | 26162 | 4 saopaulo | 26162 | 4 saopaulo | 28329 | 3 sfmix | 32212 | 73638 sg | 59318 | 69 sg | 24482 | 7 sg | 133165 | 5 sg | 24115 | 3 sg | 24115 | 3 sg | 38880 | 3 sg | 9902 | 3 sg | 18106 | 3 sydney | 58511 | 3 sydney | 4739 | 3 sydney | 38809 | 3 sydney | 4826 | 3 sydney | 38880 | 2 telxatl | 6082 | 3 telxatl | 53828 | 3 telxatl | 6939 | 3 wide | 2497 | 114965 wide | 7500 | 100240 (114 rows)
日本ほどの影響度は少数派ですね? それはなぜか?
よくわかりませんw
わかりませんが、障害トリガーとなった経路は「AS701 (Verizon) 経由でインターネットに流れた」と考えて差し支えなさそうです。観測されたAS_PATH のうち、15169 とすぐ左隣だけ抜き出します。
route_leak=# SELECT substring(aspath from '\d+ 15169') AS transit, count(distinct prefix) FROM updates GROUP BY transit ORDER BY count transit | count --------------+-------- 701 15169 | 162205 1798 15169 | 98 37271 15169 | 98 43531 15169 | 72 59318 15169 | 69 58511 15169 | 28 31019 15169 | 28 394625 15169 | 10 3257 15169 | 10 62567 15169 | 3 393406 15169 | 3 11492 15169 | 1 (12 rows)
では、AS15169 (Google) はAS701 にのみリークしたのか? もちろんその可能性は十分ありますが、もしそうではなく「他のトランジットにもリークしたが、そっちは問題にならなかった」のであれば学ぶべきポイントがありそうですよね。
普通、Tier1 プロバイダーは顧客向けBGP セッションに経路フィルターを設定します。多くの場合Peering DB やIRR から自動生成され、顧客が100% 制御できる かつオペミスを防げるようになっています。
- AS701 にはそれがなく、他のトランジット事業者にはあった
- AS701 にもあったが、特殊なアレンジをしていた。もしくは顧客がバイパスしていた
- 経路がピアを経由する際、うまくmax-prefix filter が効いた
いろいろ想像できますが、根拠がないため想像しても意味はなさそう。。。もし可能であればこのあたりのカラクリを知りたいもんです。
なぜこのエントリーを書いたか
できれば障害から学びたいと思ったからです。次に同じことが起こったとき、防げる気がしない。
BGP におけるネットワークが Autonomous System (自律システム) と呼ばれる通り、これまでのインターネットは各AS が自律的にルーティングすることでうまく動いてきました。隣のAS がミスをしたとき、できれば自分のところで影響を小さくして インターネット全体をなんとなく維持させたいと考えています。
そのために、ご近所さんのルーティングポリシーは可能な範囲で知っておきたい。最悪を想定するためでもあります。各事業者がビジネスでやっている以上「やめてほしい」は通らないかもですが、たぶん備えることはできます。
「BGP 脆弱やん」というご指摘はごもっともで、今後も同じシステムでインターネットを運用できるのかは怪しいです。しかしながら まだ打てる手はありそうで、「なぜ海外で問題なかったか」はヒントになりそうな…という感じがしています。*1
意外と「日本人マイクロマネージメントしすぎ」みたいな話題に流れていくかもしれません。
以上、「Postmortem 見たいです」のラブレターでした。
*1:Path Validation のようなハードル高い必殺技もあります
sFlow は面倒くさいが、fluent-plugin-sflow を再実装する話
背景
ネットワークデバイスからの xFlow を Fluentd で集めて分析、あるいは可視化するということをよくやります。
ルーター製品であれば fluent-plugin-netflow が使えますが、スイッチ製品はそもそも NetFlow がサポートされていません。代わりに sFlow に対応のデバイスが多いものの、現実的に動く fluent-plugin がありません。
NetFlow に比べて sFlow 実装が面倒なためですが、取り組んでみると まあまあ収まりのいい形で実装できた気がする、という記事です。
sFlow の面倒くさい点
パケットデコーダーを内包しないといけない
sFlow は L2 情報が中心で、 L3 + ルーティングの情報は普通ありません。 Ethernet ペイロードの先頭 N バイトをコレクター側でデコードしないといけません。さらに、場合によっては下のような情報を付加してやる必要があります。
- Prefix Length
- SRC / DST AS 番号
- Protocol Nexthop
- 論理 ifIndex
パフォーマンス
sFlow は IP フローを意識していません。 NetFlow ではうまく Aggregate して Export パケットを減らしたりできますが、 sFlow では Export パケットが増えがちです。
デコードしないといけないわ pps 多いわで、 NetFlow よりパフォーマンスが問題になりやすいです。
sFlow と NetFlow の名寄せ
これは sFlow の問題ではありませんが、 sFlow と NetFlow を同じ基盤で扱うときに面倒な点です。
同じ情報でも、 sFlow の流儀と NetFlow の流儀はちがいます。たとえば、パケットが入ってくるインターフェイスの ifIndex は、 sFlow v5 では input、 NetFlow v9 では input_snmp になっています。
コレクター実装を考えるとき、単純に名寄せすればいいかもしれません。が、「どっちに寄せれば…?」で悩みます。
DNS クエリーはもっと悩ましいです。
NetFlow では
{ "protocol": 17, # or 6 "l4_dst_port": 53 }
で Export されますが、 sFlow では
{ "protocol": 17, "udp_dst_port": 53 }
もしくは
{ "protocol": 6, "tcp_dst_port": 53 }
で出たりします。UDP とTCP で別キー。*1 面倒くさい!!
コレクターで UDP / TCP Port を結合して Port にするかどうかは…悩ましい。ネットワークオペレーターの事情に応じて record_transformer プラグインなどで名寄せすればよかろうと思い、今回の実装では sFlow の流儀のまま Export することにしました。
もうひとつ悩ましい例は Export パケットの SRC IP アドレス。sFlow にも Netflow にも該当するフィールドはありません。*2
fluent-plugin-netflow ではそれをhost として格納していますが、 sFlow ではhost は使えません。 HTTP HOST ヘッダーを格納するフィールドとして規定されているためです。。。面倒くさい!
このような流儀の違いが山のようにあります。 filter プラグインで名寄せしつつ、、、でパフォーマンスが出せるか十分に検討していませんが、とりえあず sFlow 流儀に従いました。
既存 fluent-plugin-sflow の BinData 問題
これも sFlow 自体の問題ではありませんが、実は fluent-plugin-sflow という gem は既に存在します。今回はそれを再実装した という形なのですが、既存のものにはいくつか問題があります。
1 . は最新の BinData では動かないのが根本原因で、仕様上むずかしそう。 2. も BinData が原因です。 ちなみに、fluent-plugin-netflow も当初は BinData ベースでしたが、パフォーマンスのために 低レベルなビット演算に変わったという経緯があります。*3
実装について
InMon 謹製の sflowtool に手を加え、 C 拡張として内包することにしました。
- 公式のパケットデコーダーを使える
- 頻度高くないが、まだメンテされているように見える
- パフォーマンス改善が見込める
- BinData とさよならできる
のがポイント。実装は こちら 。
ベンチマーク
手元の Macbook Pro Mid 2015 に 外から sFlow v5 を Export しました。
| records / sec | |
|---|---|
| 再実装版 | 14202 |
| オリジナル版 | 220 |
まあまあ実用には耐えそう。
TODO
- テストを足す
- sflowtool にパッチしたとはいえ、バグを埋めているかもしれない
- 「動かないよ」という方がいらっしゃれば、ぜひ .pcap ください 🙇
- fluent-plugin-sflow メンテナー様にコンタクトしてみる
- 別実装なので…別 gem にするべきか、プルリクしてもいいものか思案中 💦
- 出力フォーマットが変わる → プルリクするならば互換性を壊す
- BGP の情報をインポートする
フリーランスの税金対策
ネットワークエンジニアのまま脱サラし、個人事業をはじめて3年がたった。
おかげさまで ある程度の収益が出るようになったが、 節税のためにやってることのうち「これは」というやつについて書いておこうと思う。
みんな大好きお金の話です。
小規模企業共済
毎月7万円まで積み立てることができて、全額所得控除になるというもの。 わりと有名なやつなので加入者も多いと思う。
共済金の請求方法 (多くの場合は事業をたたむ理由) によって金額がかわるタイプのもので、条件を満たさなければ当然元本割れする。最低で元本の 80% だが、それほどのリスクはないと思う。
理由はいくつかあるが、
- もっとも条件の悪い請求方法である解約手当金は「事業は廃業しないが解約する」とか「金銭以外の出資によって法人成りする」などおそらくレアケース
- 「事業は廃業しないし、積み立てる余裕はない」というケースもありえそうだが、積立金は月1,000円まで落とせる。それくらいは出せる…はず…
- この場合、頑張って 20年 加入し続ければ、元本割れを防げる
- 「廃業する」「死ぬ」「譲渡する」ような、一番ありそうなケースでは (調べた限り) 元本割れしない
- 「法人成り」のケースでも条件を満たせば継続可能
- めちゃくちゃ最悪のケース、元本割れして 80% になったとしても それまでの節税額を加味すると さほど条件悪くない
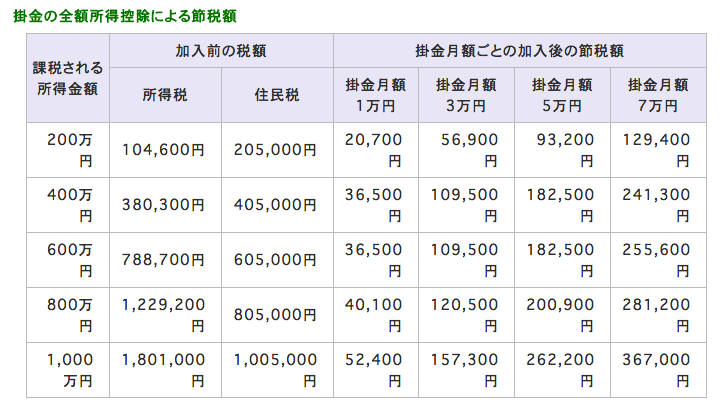
http://www.smrj.go.jp/skyosai/qa/tax/050608.html
小さいリスクに対してありあまるメリットがあって、
- 全額控除。これがデカい 💰
- 受け取り方によって税法上の扱いがかわるが、だいたいメリットがある
- 一括で受け取れば 退職所得
- 分割で受け取れば 雑所得 (年金相当)
- 解約手当金でも 一時所得 (65歳以上なら退職所得)
- 死んでも相続対象になる
- 長く積み立てれば 結構もどってきそう
制度の見直しがあれば別だけど、受け取りかたを工夫すればメリットしかないと思って 退職金や立ち行かなくなったときの保険がわりに積み立てている。
消費税の簡易課税制度
税理士いわく、こちらは知らない人もいるらしい。
消費税の扱いから書いたほうがいいかもしれないが、消費税は基本「お客さんから預かる」という建てつけなので、決算で売上を確定させたあとは納税しないといけない。
ただし、法人であれ個人事業であれ 税込で売上が1,000万以下であれば その納税義務が免除される。 これが「1,000万を超えないようにしましょう」の根拠。
1,000万の壁を超えた場合は消費税をお納めするわけだけど、いくつか考えることがある。たとえば売上に対する費用について。
売上のために支払った費用には 多くの場合すでに消費税が含まれている。決算で費用を確定したあと、預かった消費税 - 支払った消費税 を納税しましょう、というのが基本。
ここで簡易課税制度という特例があって、基本のやりかただと「支払った消費税」の計算が面倒なことが多いため、小規模事業 (法人、個人によらず税抜売上5,000万以下) であれば「みなしで仕入れ率を決めうちして、その分の消費税を払ったことにしましょう。計算ラクでしょ?」というやりかたを選べる。
みなしの仕入れ率は業種によってちがうが、われわれサービス業であれば 50%。流しのネットワークエンジニアをひとりでやってる限り 普通そんなにいかないので、節税効果がでる。昨年の自分の場合なら 20%強だった。
デメリットとして、外注が増えるなどで仕入れ実態が 50% を超えた場合に還付されなくなるが、基本のやりかた (原則課税という) と簡易課税は 申請すれば事業年度単位でパチパチ切り替えることができる。
一点、簡易課税には2年縛りがあることだけ注意。2年間は原則課税に戻せない。当然ながら申請は適用を受けたい事業年度が始まるまでに済ませておくこと。
専従者給与
複式簿記にして65万の所得控除を受けておくのは基本として、家族が事業を手伝っている場合は 専従者として給与を払うことができる。一般には住民税の壁 = 基礎控除 (33万円) + 給与所得控除 (65万円) = 98万を超えないようにするのが常套手段。
よく考えると 実はもうちょっとパラメーターがあって、「その家族には別の収入がある」「家族ぶんの確定申告がめんどくさくない」場合には、事業にかかる税率とその家族にかかる税率がちがうため最適化の余地がある。極端に振ると目立ってしまう恐れがあるので、あとで書くが税理士の出番。
どちらにせよ 専従者の分の年末調整はやらないといけないが、慣れればそんなにつらくない。
事業割合
個人事業の醍醐味 ⚡️
個人事業はあくまで個人であって、売上はともかく費用についてはどうしても 個人 / 事業の境界があいまいになる。たとえば「自宅を一部オフィスとして使ってるので、家賃の一部は費用のはず」とか。
そういうやつになるべく説得力のある理屈をつけて、「N% は事業に使ってるので費用です」と計上する。(実際は 確定申告時に理由を書く必要はなく、税務署調査が入ったら答えていく感じ )
自動車、通信費、光熱費など多岐にわたる。それぞれの理屈の付け方に (たぶん) 法律やガイドラインはなく、税務署の運用に任されている。
そう、運用の話です。税理士先生の出番ですよ。決算時にスポットで相談するとかで十分だけど、本当にプロの意見を聞いたほうがいい。
大きな理由のひとつは、税務署界隈でもあるとされる習慣や土地勘がわからないから。
「家賃はちょろまかす奴が多いから重点的にみられる。ここらではだいたい N% が相場とされる」とか「通信費は習慣的に K% でいける」とか分かるわけないです。「ここいらは高額納税者が多いから、このレベルの売上だともう一歩踏み込めると思う」とか「IT 業種多くないし極端でも目立たない可能性ある」とか。
さらに言えば税理士のなかでも「石橋を叩くタイプ」「一緒にリスクを取ってくれるタイプ」などさまざまいるみたいなので、感覚の合う税理士と出会えるかはキモ。基本は信用できる仕事仲間に紹介してもらうのがよいと思う。
事前に税理士について詳しく聞けて、気軽に相談できそうか、気が合いそうか、費用感についてもあたりをつけられるし、税理士の側も紹介を好む場合が多いらしい。
RIB / FIB コンバージェンスを可視化する方法論
高価なテスターを使わず、なんとかRIB / FIB コンバージェンスを計測することを考えています。
コンバージェンスとは
ネットワークにBGP イベントが到着してから、さまざまな計算を行い、イベントを送信し、定常状態に落ち着くまでのプロセスをコンバージェンスと呼びます。
インターネットルーティングではその所要時間 = コンバージェンスタイムに注目しながら、ネットワークや経路の設計、パラメーターチューニングをします。
RIB コンバージェンスという場合、多くはBGP Update を受信してからのコンバージェンスを指します。
ルーターデバイス単体でみれば
1 . BGP Update を受信する
2 . Adj-RIB-In を更新する
3 . 受信フィルターを適用する
4 . Best Path を計算する
5 . Loc-RIB を更新する
6 . FIB を更新する
さらに、BGP Update を伝搬させるべき全てピアについて
7 . 送信フィルターを適用する
8 . Adj-RIB-Out を更新する
9 . BGP Update を送信する
このようなプロセスです。 1~6 を区別して「FIB コンバージェンス」と呼ぶことがあります。
原理的には 6 と 7~9 は並列処理可能ですが、パケットのループやブラックホールを避けるため、一般には 6 の完了を待って 7~9 を処理することが期待されます。
AS 単位 / インターネット全体でみると
一段マクロな視点では、AS にBGP イベントが到着してからAS 全体として処理するべきプロセスを完了することを BGP コンバージェンスと呼ぶことが多いです。インターネット全体でも同じです。
BGP イベント数について
RIB コンバージェンスという言葉のニュアンスには、イベント数の大小は含まれていません。「Prefix x.x.x.x/y のRIB コンバージェンス」「フルルートのRIB コンバージェンス」のように文脈によります。
「BGP コンバージェンス」の定義については、Informational なRFC4098、RFC7747 などにまとまっています。
なぜコンバージェンスに注目するのか
ネットワークとしてのインターネットを制御するのに、AS 運用者はピアをし、経路フィルターを更新します。これによってBGP イベントを発生 / 伝搬させるわけですが、最近はコンバージェンスタイムが予測しづらくなってきました。
AS 内部においては
L3 スイッチに代表されるマーチャントシリコン製品が増え、ネットワークとしてカスタムシリコンのような機敏な動きが期待できない場合があります。
フルルートを食えない製品はもちろんのこと、RIB / FIB のハードウェアコンフィグレーションの個体差が大きくなっていると感じます。FIB のLPM (Longest Prefix Match) / LEM (Largest Exact Match) の塩梅まで制御するような取り組みも見られます。
正直なところ、やってみないとわからない。とくに「IPv4 unicast は128k routes までですっ」という製品に、ミスってフルルート入っちゃった場合のRIB / FIB のふるまいなどは予測できません。
また、VM ベースのルーター製品を使うことも増えました。思わぬボトルネックが存在することがあり、ネットワークに組み込む際にはコンバージェンスを気にしておく必要があります。
このような製品が悪というわけではなくて、利用可能な通信技術とハードウェアとソフトウェアをつかって、CAPEX + OPEX を最小化しつつ、要件を満たすネットワークをつくるのがネットワークエンジニアの腕の見せどころなので、避けて通るわけにはいきません。
頭の弱い製品を使ったとしても ネットワークとして安定すればいいわけです。
AS 外 / インターネット全体として
AS 内部のコンバージェンスがうまくいったとしても、インターネット全体として最適でない場合があります。コンバージェンスタイムは短いことが正義ではなく、お隣さんの処理速度に合わせてイベントをフロー制御することが理想です。
コンバージェンスが速すぎてNeighbor ルーターで無駄にCPU リソースを使い、かえって遅くなることもありますし、保守的に長く取りすぎてパケットロスを引き起こす こともあります。
ここでのフォーカス
うまくフィードバックをいれつつ インターネット全体で、特に自分のAS近辺で最適化することがゴールですが、まずはデバイス単体のRIB / FIB コンバージェンス観測を目的とします。
RIB / FIB コンバージェンスを計測する方法論
RFC7747 を参考にします。
eBGP の場合は
+------------+ +-----------+ +-----------+
| | | | | |
| | | | | |
| HLP | | DUT | | Emulator |
| (AS-X) |--------| (AS-Y) |-----------| (AS-Z) |
| | | | | |
| | | | | |
| | | | | |
+------------+ +-----------+ +-----------+
| |
| |
+--------------------------------------------+
Figure 2: Three-Node Setup for eBGP and iBGP Convergence
(https://tools.ietf.org/html/rfc7747)
このようなセットアップを使い、
5.1.2. RIB-OUT Convergence
Objective:
This test measures the convergence time taken by an implementation
to receive, install, and advertise a route using BGP.
(https://tools.ietf.org/html/rfc7747)
を計測します。
EmulatorからrouteA向けのパケットをHLPに流すEmulatorからrouteAをDUTに広告するDUTはrouteAをHLPに広告する- (1 . のパケットが
DUTに届き)DUTはrouteA向けのパケットをEmulatorに転送する
3. - 2. を routeA のRIB コンバージェンス、4. - 2. をrouteA のFIB コンバージェンスとします。
フルルートについて言えば、
最後の経路の 3. - 最初の経路の 2. がRIB コンバージェンス、最後の経路の 4. - 最初の経路の 2. がFIB コンバージェンスです。
処理するべき経路数によってふるまいが変わる場合があるため、コンバージェンスタイムの値だけで評価するのではなく、
- 単位時間あたりに受信した経路数 (上の2. に対応)
- 単位時間あたりに広告した経路数 (上の3. に対応)
- 単位時間あたりにFIB インストールした経路数
の時間変化をプロットするのがよさそうです。
単位時間あたりにFIB インストールした経路数?
これを実現する妙案が浮かんでいません。ブラックボックステストで実現するべきなので「外部からパケットを入れて出てくるか確認する」アプローチなのは間違いありませんが、全アドレス空間宛てのパケットを常時生成するのは困難なため、
- BGP Update 直前か ほぼ同時に、該当Prefix に含まれるいくつかのアドレス宛てにパケットを送信
- DUT (Device Under Test) がフォワードするかを確認
おそらくこの形になります。
ただし、1. でどのアドレスを選択するべきかはLPM ベースなのか / LEM ベースなのかで異なりますし、100,000コ目の経路を処理した瞬間に1コ目の経路がRIB / FIB に存在するかも確認したほうがいいかもしれません。
今のところ、このあたりちょっとアイデアがありません。
デバイスのstats を取っておきたい
計測中、デバイスのCPU 使用率、メモリ / RIB / FIB 使用量などを同時取得しておくとよさそう。
実装
機敏に動き、API を備えるgobgp を中心に実装してみます。
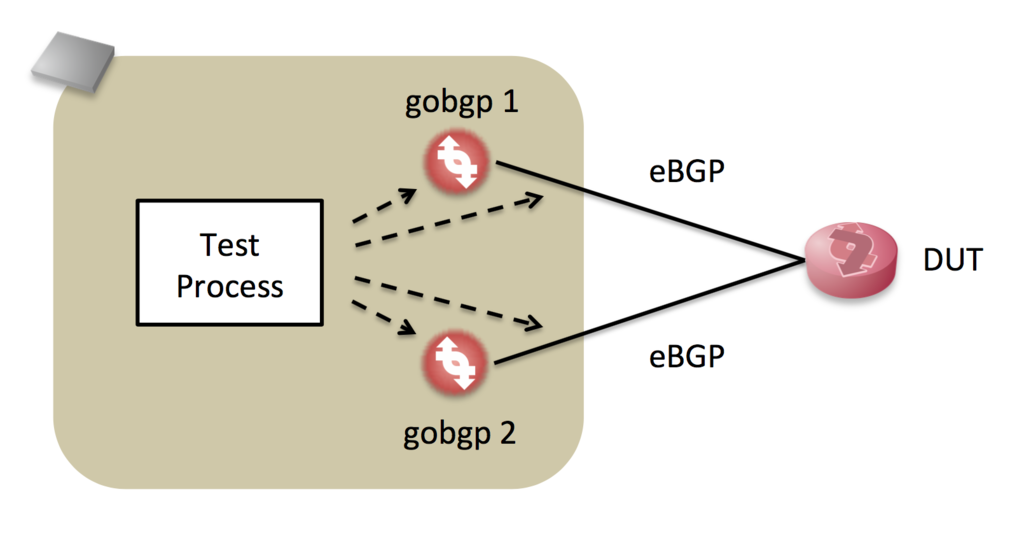
DUT で
- 新しい経路を受信した場合
- Best Path が変わった場合
- 経路がなくなった場合
それぞれ ふるまいが違う可能性があるため、次のようなシナリオでテストします。
gobgp 1からフルルートをDUTに送信gobgp 2からより強いフルルートをDUTに送信gobgp 2から2. のWithdraw をDUTに送信gobgp 1から1. のWithdraw をDUTに送信
2つのgobgp を制御して それぞれのシナリオに応じた経路を生成しつつ、それぞれの受信NLRI、送信NLRI を観測するプログラムを書きました。
経路は逐次生成ではなく、フルルートをロードしておいて送信ポリシーを reject → accept に変える、または accept → reject に変える、という方法で実装しています。
- gobgp 制御はgRPC でやる
- gobgp の動作を阻害したくないため、NLRI 観測にはlibpcap をつかう
- なるべくリアルタイムに処理し、将来的にはFIB コンバージェンス計測にパケットを生成するため、go で実装
- gobgp のgo APIとBGP パーサーを流用できるメリットもある
TCP を終端せず 観測者として動作させるためだけにTCP Reassemble を実装するのはアホらしいのですが、黙って実装します。
残念ながら、いまのところFIB コンバージェンスは計測できていません。
結果
このプログラムは上の4つのシナリオを順次実行し、結果をjson で保存します。
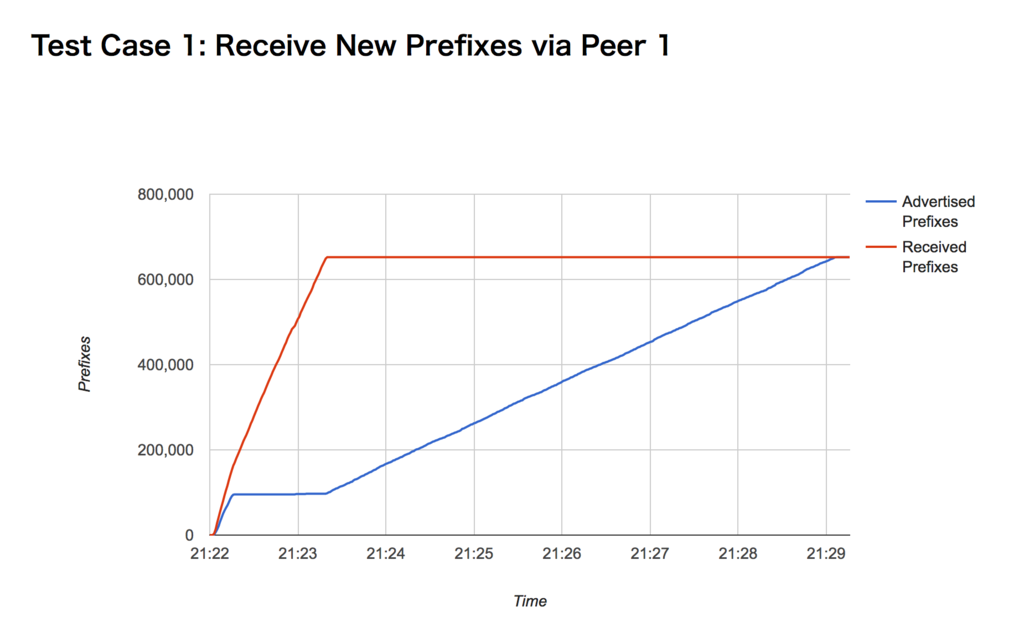
このチャートは あるVM ルーター製品のもので、毎秒の累積 送信/受信Prefix 数を描いています。テスト環境ではRIB コンバージェンスに7分かかることを示していて、経路数に対してほぼ線形であると予想できます。
コマンドラインオプションで経路数を指定できるので、実際に線形であるか確かめるシェルスクリプトも書けると思います。
余談ではありますが、この製品では、コンバージェンスまでの間CLI 上の送信経路数と実際の観測NLRI 数が大きく違っていました。
まとめ / これからやること
- 昨今のルーター製品、とくにL3 スイッチ製品のRIB コンバージェンスが予測できないため、ブラックボックステストを行う必要があると考えています
- その方法論について検討し、実装しました
- FIB コンバージェンス計測のためのアイデアがありません…コメントお待ちします!!
- gobgp がテストのボトルネックになる可能性があります。判断のヒントとなりそうな指標をチャートに載せるべきかもしれません