sFlow は面倒くさいが、fluent-plugin-sflow を再実装する話
背景
ネットワークデバイスからの xFlow を Fluentd で集めて分析、あるいは可視化するということをよくやります。
ルーター製品であれば fluent-plugin-netflow が使えますが、スイッチ製品はそもそも NetFlow がサポートされていません。代わりに sFlow に対応のデバイスが多いものの、現実的に動く fluent-plugin がありません。
NetFlow に比べて sFlow 実装が面倒なためですが、取り組んでみると まあまあ収まりのいい形で実装できた気がする、という記事です。
sFlow の面倒くさい点
パケットデコーダーを内包しないといけない
sFlow は L2 情報が中心で、 L3 + ルーティングの情報は普通ありません。 Ethernet ペイロードの先頭 N バイトをコレクター側でデコードしないといけません。さらに、場合によっては下のような情報を付加してやる必要があります。
- Prefix Length
- SRC / DST AS 番号
- Protocol Nexthop
- 論理 ifIndex
パフォーマンス
sFlow は IP フローを意識していません。 NetFlow ではうまく Aggregate して Export パケットを減らしたりできますが、 sFlow では Export パケットが増えがちです。
デコードしないといけないわ pps 多いわで、 NetFlow よりパフォーマンスが問題になりやすいです。
sFlow と NetFlow の名寄せ
これは sFlow の問題ではありませんが、 sFlow と NetFlow を同じ基盤で扱うときに面倒な点です。
同じ情報でも、 sFlow の流儀と NetFlow の流儀はちがいます。たとえば、パケットが入ってくるインターフェイスの ifIndex は、 sFlow v5 では input、 NetFlow v9 では input_snmp になっています。
コレクター実装を考えるとき、単純に名寄せすればいいかもしれません。が、「どっちに寄せれば…?」で悩みます。
DNS クエリーはもっと悩ましいです。
NetFlow では
{ "protocol": 17, # or 6 "l4_dst_port": 53 }
で Export されますが、 sFlow では
{ "protocol": 17, "udp_dst_port": 53 }
もしくは
{ "protocol": 6, "tcp_dst_port": 53 }
で出たりします。UDP とTCP で別キー。*1 面倒くさい!!
コレクターで UDP / TCP Port を結合して Port にするかどうかは…悩ましい。ネットワークオペレーターの事情に応じて record_transformer プラグインなどで名寄せすればよかろうと思い、今回の実装では sFlow の流儀のまま Export することにしました。
もうひとつ悩ましい例は Export パケットの SRC IP アドレス。sFlow にも Netflow にも該当するフィールドはありません。*2
fluent-plugin-netflow ではそれをhost として格納していますが、 sFlow ではhost は使えません。 HTTP HOST ヘッダーを格納するフィールドとして規定されているためです。。。面倒くさい!
このような流儀の違いが山のようにあります。 filter プラグインで名寄せしつつ、、、でパフォーマンスが出せるか十分に検討していませんが、とりえあず sFlow 流儀に従いました。
既存 fluent-plugin-sflow の BinData 問題
これも sFlow 自体の問題ではありませんが、実は fluent-plugin-sflow という gem は既に存在します。今回はそれを再実装した という形なのですが、既存のものにはいくつか問題があります。
1 . は最新の BinData では動かないのが根本原因で、仕様上むずかしそう。 2. も BinData が原因です。 ちなみに、fluent-plugin-netflow も当初は BinData ベースでしたが、パフォーマンスのために 低レベルなビット演算に変わったという経緯があります。*3
実装について
InMon 謹製の sflowtool に手を加え、 C 拡張として内包することにしました。
- 公式のパケットデコーダーを使える
- 頻度高くないが、まだメンテされているように見える
- パフォーマンス改善が見込める
- BinData とさよならできる
のがポイント。実装は こちら 。
ベンチマーク
手元の Macbook Pro Mid 2015 に 外から sFlow v5 を Export しました。
| records / sec | |
|---|---|
| 再実装版 | 14202 |
| オリジナル版 | 220 |
まあまあ実用には耐えそう。
TODO
- テストを足す
- sflowtool にパッチしたとはいえ、バグを埋めているかもしれない
- 「動かないよ」という方がいらっしゃれば、ぜひ .pcap ください 🙇
- fluent-plugin-sflow メンテナー様にコンタクトしてみる
- 別実装なので…別 gem にするべきか、プルリクしてもいいものか思案中 💦
- 出力フォーマットが変わる → プルリクするならば互換性を壊す
- BGP の情報をインポートする
フリーランスの税金対策
ネットワークエンジニアのまま脱サラし、個人事業をはじめて3年がたった。
おかげさまで ある程度の収益が出るようになったが、 節税のためにやってることのうち「これは」というやつについて書いておこうと思う。
みんな大好きお金の話です。
小規模企業共済
毎月7万円まで積み立てることができて、全額所得控除になるというもの。 わりと有名なやつなので加入者も多いと思う。
共済金の請求方法 (多くの場合は事業をたたむ理由) によって金額がかわるタイプのもので、条件を満たさなければ当然元本割れする。最低で元本の 80% だが、それほどのリスクはないと思う。
理由はいくつかあるが、
- もっとも条件の悪い請求方法である解約手当金は「事業は廃業しないが解約する」とか「金銭以外の出資によって法人成りする」などおそらくレアケース
- 「事業は廃業しないし、積み立てる余裕はない」というケースもありえそうだが、積立金は月1,000円まで落とせる。それくらいは出せる…はず…
- この場合、頑張って 20年 加入し続ければ、元本割れを防げる
- 「廃業する」「死ぬ」「譲渡する」ような、一番ありそうなケースでは (調べた限り) 元本割れしない
- 「法人成り」のケースでも条件を満たせば継続可能
- めちゃくちゃ最悪のケース、元本割れして 80% になったとしても それまでの節税額を加味すると さほど条件悪くない
http://www.smrj.go.jp/skyosai/qa/tax/050608.html
小さいリスクに対してありあまるメリットがあって、
- 全額控除。これがデカい 💰
- 受け取り方によって税法上の扱いがかわるが、だいたいメリットがある
- 一括で受け取れば 退職所得
- 分割で受け取れば 雑所得 (年金相当)
- 解約手当金でも 一時所得 (65歳以上なら退職所得)
- 死んでも相続対象になる
- 長く積み立てれば 結構もどってきそう
制度の見直しがあれば別だけど、受け取りかたを工夫すればメリットしかないと思って 退職金や立ち行かなくなったときの保険がわりに積み立てている。
消費税の簡易課税制度
税理士いわく、こちらは知らない人もいるらしい。
消費税の扱いから書いたほうがいいかもしれないが、消費税は基本「お客さんから預かる」という建てつけなので、決算で売上を確定させたあとは納税しないといけない。
ただし、法人であれ個人事業であれ 税込で売上が1,000万以下であれば その納税義務が免除される。 これが「1,000万を超えないようにしましょう」の根拠。
1,000万の壁を超えた場合は消費税をお納めするわけだけど、いくつか考えることがある。たとえば売上に対する費用について。
売上のために支払った費用には 多くの場合すでに消費税が含まれている。決算で費用を確定したあと、預かった消費税 - 支払った消費税 を納税しましょう、というのが基本。
ここで簡易課税制度という特例があって、基本のやりかただと「支払った消費税」の計算が面倒なことが多いため、小規模事業 (法人、個人によらず税抜売上5,000万以下) であれば「みなしで仕入れ率を決めうちして、その分の消費税を払ったことにしましょう。計算ラクでしょ?」というやりかたを選べる。
みなしの仕入れ率は業種によってちがうが、われわれサービス業であれば 50%。流しのネットワークエンジニアをひとりでやってる限り 普通そんなにいかないので、節税効果がでる。昨年の自分の場合なら 20%強だった。
デメリットとして、外注が増えるなどで仕入れ実態が 50% を超えた場合に還付されなくなるが、基本のやりかた (原則課税という) と簡易課税は 申請すれば事業年度単位でパチパチ切り替えることができる。
一点、簡易課税には2年縛りがあることだけ注意。2年間は原則課税に戻せない。当然ながら申請は適用を受けたい事業年度が始まるまでに済ませておくこと。
専従者給与
複式簿記にして65万の所得控除を受けておくのは基本として、家族が事業を手伝っている場合は 専従者として給与を払うことができる。一般には住民税の壁 = 基礎控除 (33万円) + 給与所得控除 (65万円) = 98万を超えないようにするのが常套手段。
よく考えると 実はもうちょっとパラメーターがあって、「その家族には別の収入がある」「家族ぶんの確定申告がめんどくさくない」場合には、事業にかかる税率とその家族にかかる税率がちがうため最適化の余地がある。極端に振ると目立ってしまう恐れがあるので、あとで書くが税理士の出番。
どちらにせよ 専従者の分の年末調整はやらないといけないが、慣れればそんなにつらくない。
事業割合
個人事業の醍醐味 ⚡️
個人事業はあくまで個人であって、売上はともかく費用についてはどうしても 個人 / 事業の境界があいまいになる。たとえば「自宅を一部オフィスとして使ってるので、家賃の一部は費用のはず」とか。
そういうやつになるべく説得力のある理屈をつけて、「N% は事業に使ってるので費用です」と計上する。(実際は 確定申告時に理由を書く必要はなく、税務署調査が入ったら答えていく感じ )
自動車、通信費、光熱費など多岐にわたる。それぞれの理屈の付け方に (たぶん) 法律やガイドラインはなく、税務署の運用に任されている。
そう、運用の話です。税理士先生の出番ですよ。決算時にスポットで相談するとかで十分だけど、本当にプロの意見を聞いたほうがいい。
大きな理由のひとつは、税務署界隈でもあるとされる習慣や土地勘がわからないから。
「家賃はちょろまかす奴が多いから重点的にみられる。ここらではだいたい N% が相場とされる」とか「通信費は習慣的に K% でいける」とか分かるわけないです。「ここいらは高額納税者が多いから、このレベルの売上だともう一歩踏み込めると思う」とか「IT 業種多くないし極端でも目立たない可能性ある」とか。
さらに言えば税理士のなかでも「石橋を叩くタイプ」「一緒にリスクを取ってくれるタイプ」などさまざまいるみたいなので、感覚の合う税理士と出会えるかはキモ。基本は信用できる仕事仲間に紹介してもらうのがよいと思う。
事前に税理士について詳しく聞けて、気軽に相談できそうか、気が合いそうか、費用感についてもあたりをつけられるし、税理士の側も紹介を好む場合が多いらしい。
RIB / FIB コンバージェンスを可視化する方法論
高価なテスターを使わず、なんとかRIB / FIB コンバージェンスを計測することを考えています。
コンバージェンスとは
ネットワークにBGP イベントが到着してから、さまざまな計算を行い、イベントを送信し、定常状態に落ち着くまでのプロセスをコンバージェンスと呼びます。
インターネットルーティングではその所要時間 = コンバージェンスタイムに注目しながら、ネットワークや経路の設計、パラメーターチューニングをします。
RIB コンバージェンスという場合、多くはBGP Update を受信してからのコンバージェンスを指します。
ルーターデバイス単体でみれば
1 . BGP Update を受信する
2 . Adj-RIB-In を更新する
3 . 受信フィルターを適用する
4 . Best Path を計算する
5 . Loc-RIB を更新する
6 . FIB を更新する
さらに、BGP Update を伝搬させるべき全てピアについて
7 . 送信フィルターを適用する
8 . Adj-RIB-Out を更新する
9 . BGP Update を送信する
このようなプロセスです。 1~6 を区別して「FIB コンバージェンス」と呼ぶことがあります。
原理的には 6 と 7~9 は並列処理可能ですが、パケットのループやブラックホールを避けるため、一般には 6 の完了を待って 7~9 を処理することが期待されます。
AS 単位 / インターネット全体でみると
一段マクロな視点では、AS にBGP イベントが到着してからAS 全体として処理するべきプロセスを完了することを BGP コンバージェンスと呼ぶことが多いです。インターネット全体でも同じです。
BGP イベント数について
RIB コンバージェンスという言葉のニュアンスには、イベント数の大小は含まれていません。「Prefix x.x.x.x/y のRIB コンバージェンス」「フルルートのRIB コンバージェンス」のように文脈によります。
「BGP コンバージェンス」の定義については、Informational なRFC4098、RFC7747 などにまとまっています。
なぜコンバージェンスに注目するのか
ネットワークとしてのインターネットを制御するのに、AS 運用者はピアをし、経路フィルターを更新します。これによってBGP イベントを発生 / 伝搬させるわけですが、最近はコンバージェンスタイムが予測しづらくなってきました。
AS 内部においては
L3 スイッチに代表されるマーチャントシリコン製品が増え、ネットワークとしてカスタムシリコンのような機敏な動きが期待できない場合があります。
フルルートを食えない製品はもちろんのこと、RIB / FIB のハードウェアコンフィグレーションの個体差が大きくなっていると感じます。FIB のLPM (Longest Prefix Match) / LEM (Largest Exact Match) の塩梅まで制御するような取り組みも見られます。
正直なところ、やってみないとわからない。とくに「IPv4 unicast は128k routes までですっ」という製品に、ミスってフルルート入っちゃった場合のRIB / FIB のふるまいなどは予測できません。
また、VM ベースのルーター製品を使うことも増えました。思わぬボトルネックが存在することがあり、ネットワークに組み込む際にはコンバージェンスを気にしておく必要があります。
このような製品が悪というわけではなくて、利用可能な通信技術とハードウェアとソフトウェアをつかって、CAPEX + OPEX を最小化しつつ、要件を満たすネットワークをつくるのがネットワークエンジニアの腕の見せどころなので、避けて通るわけにはいきません。
頭の弱い製品を使ったとしても ネットワークとして安定すればいいわけです。
AS 外 / インターネット全体として
AS 内部のコンバージェンスがうまくいったとしても、インターネット全体として最適でない場合があります。コンバージェンスタイムは短いことが正義ではなく、お隣さんの処理速度に合わせてイベントをフロー制御することが理想です。
コンバージェンスが速すぎてNeighbor ルーターで無駄にCPU リソースを使い、かえって遅くなることもありますし、保守的に長く取りすぎてパケットロスを引き起こす こともあります。
ここでのフォーカス
うまくフィードバックをいれつつ インターネット全体で、特に自分のAS近辺で最適化することがゴールですが、まずはデバイス単体のRIB / FIB コンバージェンス観測を目的とします。
RIB / FIB コンバージェンスを計測する方法論
RFC7747 を参考にします。
eBGP の場合は
+------------+ +-----------+ +-----------+
| | | | | |
| | | | | |
| HLP | | DUT | | Emulator |
| (AS-X) |--------| (AS-Y) |-----------| (AS-Z) |
| | | | | |
| | | | | |
| | | | | |
+------------+ +-----------+ +-----------+
| |
| |
+--------------------------------------------+
Figure 2: Three-Node Setup for eBGP and iBGP Convergence
(https://tools.ietf.org/html/rfc7747)
このようなセットアップを使い、
5.1.2. RIB-OUT Convergence
Objective:
This test measures the convergence time taken by an implementation
to receive, install, and advertise a route using BGP.
(https://tools.ietf.org/html/rfc7747)
を計測します。
EmulatorからrouteA向けのパケットをHLPに流すEmulatorからrouteAをDUTに広告するDUTはrouteAをHLPに広告する- (1 . のパケットが
DUTに届き)DUTはrouteA向けのパケットをEmulatorに転送する
3. - 2. を routeA のRIB コンバージェンス、4. - 2. をrouteA のFIB コンバージェンスとします。
フルルートについて言えば、
最後の経路の 3. - 最初の経路の 2. がRIB コンバージェンス、最後の経路の 4. - 最初の経路の 2. がFIB コンバージェンスです。
処理するべき経路数によってふるまいが変わる場合があるため、コンバージェンスタイムの値だけで評価するのではなく、
- 単位時間あたりに受信した経路数 (上の2. に対応)
- 単位時間あたりに広告した経路数 (上の3. に対応)
- 単位時間あたりにFIB インストールした経路数
の時間変化をプロットするのがよさそうです。
単位時間あたりにFIB インストールした経路数?
これを実現する妙案が浮かんでいません。ブラックボックステストで実現するべきなので「外部からパケットを入れて出てくるか確認する」アプローチなのは間違いありませんが、全アドレス空間宛てのパケットを常時生成するのは困難なため、
- BGP Update 直前か ほぼ同時に、該当Prefix に含まれるいくつかのアドレス宛てにパケットを送信
- DUT (Device Under Test) がフォワードするかを確認
おそらくこの形になります。
ただし、1. でどのアドレスを選択するべきかはLPM ベースなのか / LEM ベースなのかで異なりますし、100,000コ目の経路を処理した瞬間に1コ目の経路がRIB / FIB に存在するかも確認したほうがいいかもしれません。
今のところ、このあたりちょっとアイデアがありません。
デバイスのstats を取っておきたい
計測中、デバイスのCPU 使用率、メモリ / RIB / FIB 使用量などを同時取得しておくとよさそう。
実装
機敏に動き、API を備えるgobgp を中心に実装してみます。
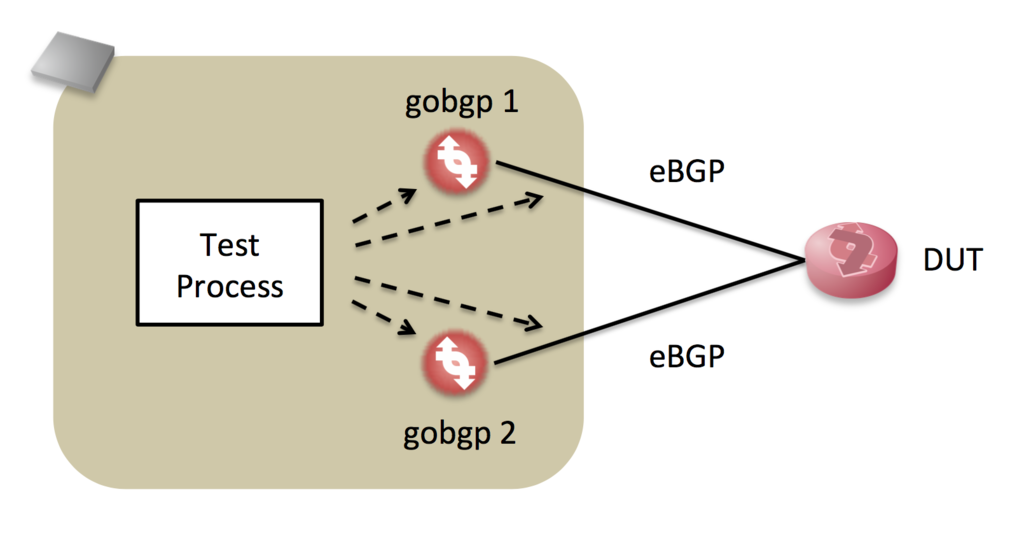
DUT で
- 新しい経路を受信した場合
- Best Path が変わった場合
- 経路がなくなった場合
それぞれ ふるまいが違う可能性があるため、次のようなシナリオでテストします。
gobgp 1からフルルートをDUTに送信gobgp 2からより強いフルルートをDUTに送信gobgp 2から2. のWithdraw をDUTに送信gobgp 1から1. のWithdraw をDUTに送信
2つのgobgp を制御して それぞれのシナリオに応じた経路を生成しつつ、それぞれの受信NLRI、送信NLRI を観測するプログラムを書きました。
経路は逐次生成ではなく、フルルートをロードしておいて送信ポリシーを reject → accept に変える、または accept → reject に変える、という方法で実装しています。
- gobgp 制御はgRPC でやる
- gobgp の動作を阻害したくないため、NLRI 観測にはlibpcap をつかう
- なるべくリアルタイムに処理し、将来的にはFIB コンバージェンス計測にパケットを生成するため、go で実装
- gobgp のgo APIとBGP パーサーを流用できるメリットもある
TCP を終端せず 観測者として動作させるためだけにTCP Reassemble を実装するのはアホらしいのですが、黙って実装します。
残念ながら、いまのところFIB コンバージェンスは計測できていません。
結果
このプログラムは上の4つのシナリオを順次実行し、結果をjson で保存します。
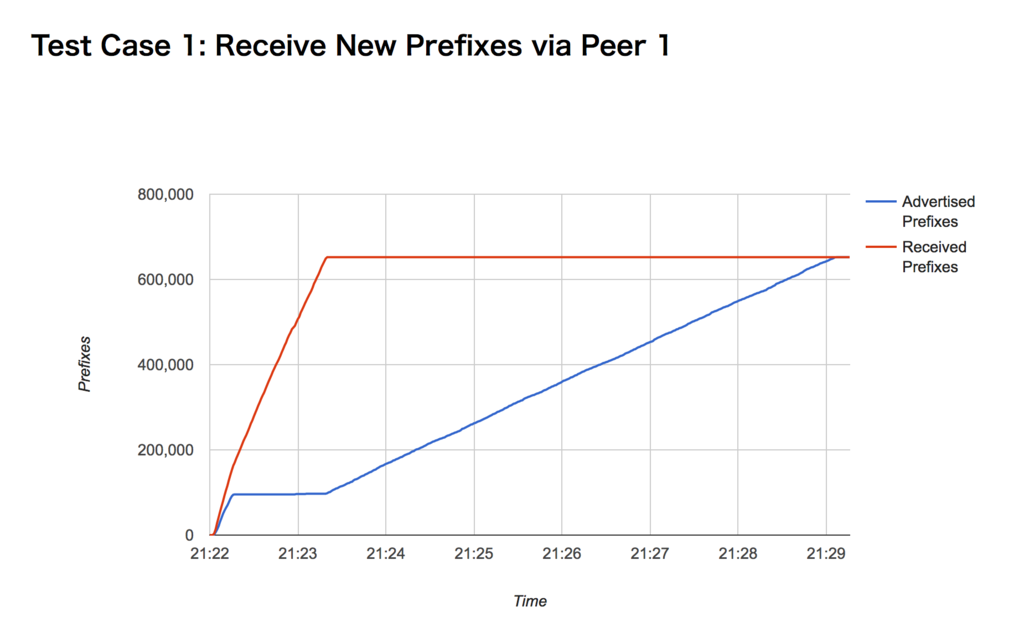
このチャートは あるVM ルーター製品のもので、毎秒の累積 送信/受信Prefix 数を描いています。テスト環境ではRIB コンバージェンスに7分かかることを示していて、経路数に対してほぼ線形であると予想できます。
コマンドラインオプションで経路数を指定できるので、実際に線形であるか確かめるシェルスクリプトも書けると思います。
余談ではありますが、この製品では、コンバージェンスまでの間CLI 上の送信経路数と実際の観測NLRI 数が大きく違っていました。
まとめ / これからやること
- 昨今のルーター製品、とくにL3 スイッチ製品のRIB コンバージェンスが予測できないため、ブラックボックステストを行う必要があると考えています
- その方法論について検討し、実装しました
- FIB コンバージェンス計測のためのアイデアがありません…コメントお待ちします!!
- gobgp がテストのボトルネックになる可能性があります。判断のヒントとなりそうな指標をチャートに載せるべきかもしれません
xlogin でコマンド自動投入→手動制御 を繰り返す
- コマンド群を入れる
- 手動制御
- 別のコマンド群を入れる
- 手動制御
- …
を大量デバイス上でやりたい、ということがありました。
これを少しいじると便利になります。
# configure.tcl source [file join [file dirname [info script]] juniper.tcl] run "configure set interfaces ge-0/0/0 description foo show | compare commit check " run " set interfaces ge-0/0/1 description bar show | compare commit check " run " exit show chassis routing-engine "
run の中身を入れ終わった後に手動制御になり、^n キーで自動制御に戻って次のrun に移ります。
configure.tcl の隣に juniper.tcl を置いておいてください。
実行例
codeout $ jlogin -s configure.tcl 192.168.0.81
192.168.0.81
set cli complete-on-space on
Enabling complete-on-space
codeout@vsrx> configure
Entering configuration mode
[edit]
codeout@vsrx# set interfaces ge-0/0/0 description foo
[edit]
codeout@vsrx# show | compare
[edit interfaces ge-0/0/0]
- description "new 1";
+ description foo;
[edit]
codeout@vsrx# commit check
configuration check succeeds
[edit]
codeout@vsrx# <-- ここで手動制御に
[edit]
codeout@vsrx# commit
commit complete
[edit]
codeout@vsrx# <-- ^n で自動に戻す
[edit]
codeout@vsrx# set interfaces ge-0/0/1 description bar
[edit]
codeout@vsrx# show | compare
[edit interfaces ge-0/0/1]
- description "new 2";
+ description bar;
[edit]
codeout@vsrx# commit check
configuration check succeeds
[edit]
codeout@vsrx# <-- ここで手動制御に
[edit]
codeout@vsrx# commit
commit complete
[edit]
codeout@vsrx# <-- ^n で自動に戻す
[edit]
codeout@vsrx# exit
Exiting configuration mode
codeout@vsrx> show chassis routing-engine
Routing Engine status:
Total memory 2048 MB Max 635 MB used ( 31 percent)
Control plane memory 1150 MB Max 449 MB used ( 39 percent)
Data plane memory 898 MB Max 189 MB used ( 21 percent)
CPU utilization:
User 0 percent
Background 0 percent
Kernel 0 percent
Interrupt 0 percent
Idle 100 percent
Model FIREFLY-PERIMETER RE
Start time 2017-06-13 14:34:07 UTC
Uptime 5 minutes, 48 seconds
Last reboot reason Router rebooted after a normal shutdown.
Load averages: 1 minute 5 minute 15 minute
0.01 0.10 0.07
codeout@vsrx> <-- ここで手動制御に
codeout@vsrx> % codeout $
jlogin の例でした。
Routing protocols' seed metrics for redistributing
When routes are redistributed into another routing protocol, their metrics are also translated to different values depending on vendor implementation and routing protocol which the routes are being redistributed to. Tables below show what value will be chosen when redistributing between protocols with no default metric configured explicitly, that is called as “seed metric”.
The seed metrics listed below are picked from Juniper vSRX and Cisco IOS-XRv default behavior.
Juniper vSRX
| from \ to | ospf | isis | rip | bgp (med) |
|---|---|---|---|---|
| direct | 0 (E2) |
0 (L1/L2) |
0 |
none |
| static | 0 (E2) |
0 (L1/L2) |
0 |
none |
| ospf | – | ospf metric (L1/L2) | 0 |
ospf metric |
| isis | isis metric (E2) | – | 0 |
none |
| rip | rip metric (E2) | rip metric (L1/L2) | – | rip metric |
| aggregate | 0 (E2) |
10 (L1/L2) |
0 |
none |
| bgp | bgp med (E2) | 10 (L1/L2) |
0 |
– |
Cisco IOS-XRv
| from \ to | eigrp | ospf | isis | rip | bgp (med) |
|---|---|---|---|---|---|
| connected | variable (*1) | 20 (E2) |
0 (L2) |
(x) variable | 0 |
| static | (x) 2^32-1 |
20 (E2) |
0 (L2) |
(x) variable | 0 |
| eigrp | – | 20 (E2) |
0 (L2) |
(x) variable | eigrp metric |
| ospf | (x) 2^32-1 |
– | 0 (L2) |
(x) variable | ospf metric |
| isis | (x) 2^32-1 |
20 (E2) |
– | (x) variable | isis metric |
| rip | (x) 2^32-1 |
20 (E2) |
0 (L2) |
– | rip metric |
| bgp | (x) 2^32-1 (*2) |
1 (E2) (*2) |
0 (L2) (*2) |
(x) variable | – |
- (x):
default-metricmust be configured to redistribute- (x)
2^32-1: Default metric is squashed by max value even whendefault-metricis configured. Note that redistribution cannot be done withoutdefault-metric. - (x) variable: Metric specified by
default-metricis assigned.
- (x)
- (*1): Composite metric calculated from interface metrics
- (*2):
router bgp <ASN>; bgp redistribute-internalstatement is required to restribute
inet-henge にいくつか機能を足した
2020-02-25追記: SVG DOM が変更になったため、この記事のCSS ではスタイルが壊れるかもしれません。こちら も参考にしてください。
inet-henge というネットワーク図生成ライブラリーに
- リンク太さを変えられる
- リンク両端に加え,中央にラベルを置ける
地味な機能を足した.
inet-henge とは?
JSON データを元にネットワーク図を生成してくれる js ライブラリー.オートレイアウトする.
このようなコンセプトで作っている.
- 自動更新
- 入力少なく
- このくらいの外部データから生成したい.手動でレイアウトしたくない
{ "nodes": [{ "name": "A" },{ "name": "B" }], "links": [{ "source": "A", "target": "B" }] }
美しくなくていい.見てわかる範囲でやってくれれば OK
動かしたい
- 運用しながら / 設計しながら見る.デバイスやPOP 単位でノードを動かしたい
- レイアウトは保存しなくてもいい.再計算しても毎回結果が同じならOK
- ズームしたい.ある程度拡大したときのみ細かい情報を表示したい
- ブラウザでネットワーク図を表示したその画面で実現したい.ドキュメント内でもやりたい
デモ
https://youtu.be/3ZREgY2FGBkyoutu.be
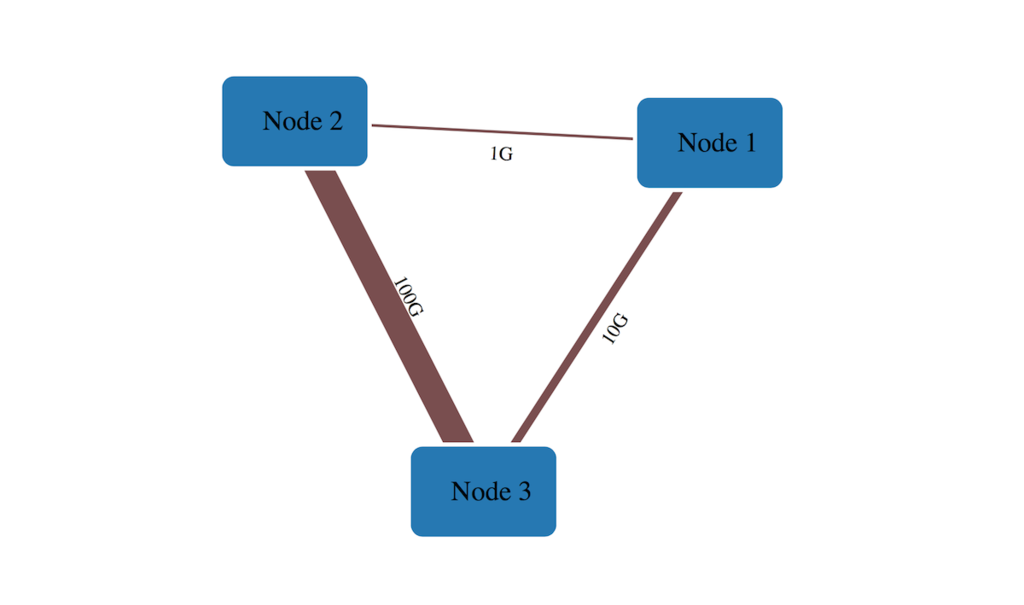
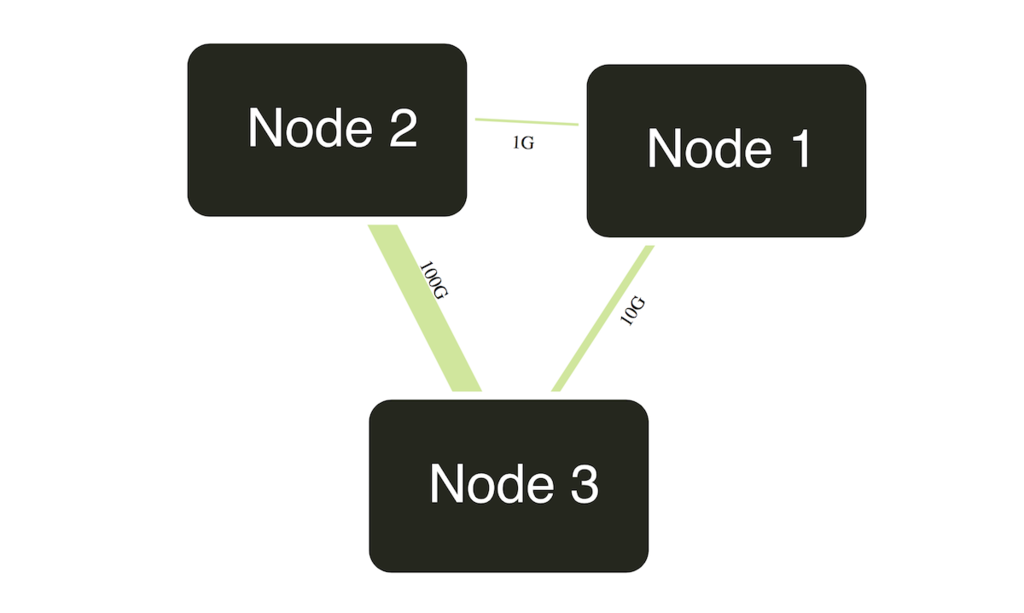
リンク太さを変える
こんな感じでメタデータを定義しておいて 👇
"links": [ { "source": "Node 1", "target": "Node 2", "meta": { "bandwidth": "1G" }}, { "source": "Node 1", "target": "Node 3", "meta": { "bandwidth": "10G" }}, { "source": "Node 2", "target": "Node 3", "meta": { "bandwidth": "100G" }} ]
こんな感じで描画する.👇 メタデータをもとにSVG のstroke-width を返す関数を渡す.
var diagram = new Diagram('#diagram', 'index.json'); diagram.link_width(function (link) { if (!link) return 1; // px else if (link.bandwidth === '100G') return 10; // px else if (link.bandwidth === '10G') return 3; // px }); diagram.init('bandwidth');
何も返さない場合はSVG のデフォルト = 1px になる.
リンクにラベルを置く
こんな感じのリンク情報があったとすると 👇
"links": [ { "source": "Node 1", "target": "Node 2", "meta": { "bandwidth": "10G", "intf-name": { "source": "interface A", "target": "interface B" } } } ]
こう書くことで 👇
new Diagram('#diagram', 'index.json').init('bandwidth', 'intf-name');
こうなる 👇
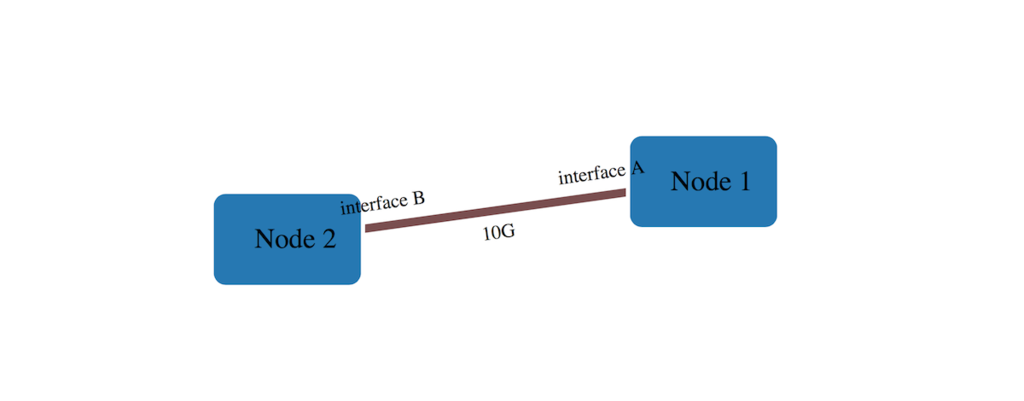
スタイルを変える
(追加機能ではないけれど) inet-henge はSVG を出力するので,CSS でスタイルを変えることができる.
.node rect { fill: #25271e !important; transform: scale(2) translate(-13px, -5px); } .node text { font-family: sans-serif; fill: #fff; font-size: 20px; transform: translate(0, 5px) } .link { stroke: #d0e799; stroke-opacity: 1; }
今後
- LAG をうまく表現できない.なんとかしたい
- ノード / リンクが増えたときのパフォーマンスが問題.アルゴリズムの調整,計算結果の再利用など考えないといけない
もしご意見などありましたら…気軽にお声がけください!
Large BGP Community がやってくる前に,Community マッチをおさらいしよう
2017 / 02月,BGP Large Communities Attribute (RFC8092) がRFC 化された.
これは新たに 4Bytes:4Bytes:4Bytes のBGP Community を使えるようにするもので,既存の
- BGP Community (RFC1997) -
2Bytes:2Bytes - Extended BGP Community (RFC4360) -
4Bytes:2Bytesもしくは2Bytes:4Bytes
に比べて空間を広く使うことができる.BGP Community の先頭2バイト(もしくは4バイト) はGlobal Administrator と呼ばれ,ふつうは事業者のグローバルAS番号をあてる.加えて操作対象のAS番号,たとえば顧客のAS番号をBGP Community に含めたいケースがあり,これまでのBGP Community では空間が足りなかった.
近々BGP Community 空間が拡張されるにあたり「いま設定しているBGP Community 正規表現だいじょうぶなんだっけ?」と思って,いくつかの実装でマッチ方法を復習した.
Community マッチ方法
Juniper JUNOS
- Community 表現(横) がマッチ対象(縦) にマッチするか
- アルファベットはBGP Community を10進で表現したときの1ケタ.4ケタ = 2Bytes,6ケタ = 4Bytes
- Large BGP Community 実装はなさそう
| ⬇️対象 \ 表現➡️ | bbb:xxx | bbb:xxx.* | bbbL:xxx.* |
|---|---|---|---|
| bbb:xxx | ⭕️ する | ⭕️ する | ❌ しない |
| abbb:xxx | ❌ しない | ⭕️ する | ❌ しない |
| target:abbb:xxx | ❌ しない | ⭕️ する | ❌ しない |
| target:aaabbb:xxx | ❌ しない | ❌ しない | ⭕️ する |
| bbb:xxxy | ❌ しない | ⭕️ する | ❌ しない |
想像するに
Lキーワードの有無で長さマッチ\d+:\d+パターンであれば^\d+:\d+$と解釈.それ以外はそのまま
Cisco IOS-XR
- 正規表現(横) がマッチ対象(縦) にマッチするか
- アルファベットはBGP Community を10進で表現したときの1ケタ.4ケタ = 2Bytes
community-setの例.ほかにextcommunity-setキーワードがある- Large BGP Community 実装はなさそう
| ⬇️対象 \ 表現➡️ | bbb:xxx | bbb:* | ios-regex ‘bbb:xxx’ | ios-regex ‘bbb:xxx.*’ |
|---|---|---|---|---|
| bbb:xxx | ⭕️ する | ⭕️ する | ⭕️ する | ⭕️ する |
| abbb:xxx | ❌ しない | ❌ しない | ⭕️ する | ⭕️ する |
| target:abbb:xxx | ❌ しない | ❌ しない | ❌ しない | ❌ しない |
| target:aaabbb:xxx | ❌ しない | ❌ しない | ❌ しない | ❌ しない |
| bbb:xxxy | ❌ しない | ⭕️ する | ⭕️ する | ⭕️ する |
想像するに
community-setキーワード,extcommunity-setキーワードで分離.異なるものにマッチしない- ワイルドカードは 文頭 / 文末 を前提にしてマッチ
- 正規表現は 文頭 / 文末 でなくてもマッチ
gobgp
- 正規表現(横) がマッチ対象(縦) にマッチするか
- アルファベットはBGP Community を10進で表現したときの1ケタ.4ケタ = 2Bytes,6ケタ = 4Bytes
communityの例.ほかにext-community,large-communityキーワードがある- Large BGP Community 対応バージョン
| ⬇️対象 \ 表現➡️ | bbb:xxx | bbb:xxx.* |
|---|---|---|
| bbb:xxx | ⭕️ する | ⭕️ する |
| abbb:xxx | ❌ しない | ⭕️ する |
| target:abbb:xxx | ❌ しない | ❌ しない |
| target:aaabbb:xxx | ❌ しない | ❌ しない |
| bbb:xxxy | ❌ しない | ⭕️ する |
| aaa:bbb:xxx | ❌ しない | ❌ しない |
community,ext-community,large-communityキーワードで分離.異なるものにマッチしない\d+:\d+パターンであれば^\d+:\d+$と解釈.それ以外はそのまま
Quagga
- 正規表現(横) がマッチ対象(縦) にマッチするか
- アルファベットはBGP Community を10進で表現したときの1ケタ.4ケタ = 2Bytes,6ケタ = 4Bytes
community-listの例.ほかにextcommunity-list,large-community-listキーワードがある- Large BGP Community 対応バージョン
| ⬇️対象 \ 表現➡️ | bbb:xxx | bbb:xxx.* |
|---|---|---|
| bbb:xxx | ⭕️ する | ⭕️ する |
| abbb:xxx | ⭕️ する | ⭕️ する |
| target:abbb:xxx | ❌ しない | ❌ しない |
| target:aaabbb:xxx | ❌ しない | ❌ しない |
| bbb:xxxy | ⭕️ する | ⭕️ する |
| aaa:bbb:xxx | ❌ しない | ❌ しない |
community-list,extcommunity-list,large-community-listキーワードで分離.異なるものにマッチしない- そのまま正規表現マッチ
Large BGP Community に対する懸念
2バイトの5ケタAS事業者が^ccccc:xxx$ と書くべきところを「ふつう2Bytes:2Bytes だし」とサボってccccc:xxx$ と書いてしまった場合に,意図しないLarge BGP Community にマッチして誤動作しないかを気にしていた.aaa:ccccc:xxx やaaa:bccccc:xxx にマッチするかもなと.
4ケタ以下事業者は^ 忘れてないだろうし,4バイト事業者はうまくBGP Community を使えていないのでは と思われるので,問題になるとすれば2バイト5ケタかなと.
上記のようにまとめてみると,各実装とも既存の2Bytes:2Bytes Community と4Bytes:4Bytes:4Bytes のLarge BGP Community をキーワードで分離させる方針のようなので,杞憂かもしれない.
(JUNOS でExtended Community にマッチしてしまう細かな問題はあるかもしれない)
JUNOS のL キーワードはこれでいいんだっけ?
「4バイトの場合はL キーワードを使え」とドキュメントに書いているが,4Bytes:2Bytes もしくは 2Bytes:4Bytes だけであればこれでよかった.ところが4Bytes:4Bytes:4Bytes になると破綻するように思う.
aaa:bbb:ccc のうち,aaa はAS番号固定かもしれないが,bbb, ccc は2バイトレンジかもしれないし,4バイトレンジかもしれない.L の有無について4パターン併記しないといけない? それはつらい.
どういう実装で出してくるか楽しみだが,「L キーワードは捨てて,あらゆるCommunity について文頭~文末まで正規表現で文字列マッチします」というのがかえって分かりやすい気がする.
*1:手元に古いのしかなかった 😭