RIB / FIB コンバージェンスを可視化する方法論
高価なテスターを使わず、なんとかRIB / FIB コンバージェンスを計測することを考えています。
コンバージェンスとは
ネットワークにBGP イベントが到着してから、さまざまな計算を行い、イベントを送信し、定常状態に落ち着くまでのプロセスをコンバージェンスと呼びます。
インターネットルーティングではその所要時間 = コンバージェンスタイムに注目しながら、ネットワークや経路の設計、パラメーターチューニングをします。
RIB コンバージェンスという場合、多くはBGP Update を受信してからのコンバージェンスを指します。
ルーターデバイス単体でみれば
1 . BGP Update を受信する
2 . Adj-RIB-In を更新する
3 . 受信フィルターを適用する
4 . Best Path を計算する
5 . Loc-RIB を更新する
6 . FIB を更新する
さらに、BGP Update を伝搬させるべき全てピアについて
7 . 送信フィルターを適用する
8 . Adj-RIB-Out を更新する
9 . BGP Update を送信する
このようなプロセスです。 1~6 を区別して「FIB コンバージェンス」と呼ぶことがあります。
原理的には 6 と 7~9 は並列処理可能ですが、パケットのループやブラックホールを避けるため、一般には 6 の完了を待って 7~9 を処理することが期待されます。
AS 単位 / インターネット全体でみると
一段マクロな視点では、AS にBGP イベントが到着してからAS 全体として処理するべきプロセスを完了することを BGP コンバージェンスと呼ぶことが多いです。インターネット全体でも同じです。
BGP イベント数について
RIB コンバージェンスという言葉のニュアンスには、イベント数の大小は含まれていません。「Prefix x.x.x.x/y のRIB コンバージェンス」「フルルートのRIB コンバージェンス」のように文脈によります。
「BGP コンバージェンス」の定義については、Informational なRFC4098、RFC7747 などにまとまっています。
なぜコンバージェンスに注目するのか
ネットワークとしてのインターネットを制御するのに、AS 運用者はピアをし、経路フィルターを更新します。これによってBGP イベントを発生 / 伝搬させるわけですが、最近はコンバージェンスタイムが予測しづらくなってきました。
AS 内部においては
L3 スイッチに代表されるマーチャントシリコン製品が増え、ネットワークとしてカスタムシリコンのような機敏な動きが期待できない場合があります。
フルルートを食えない製品はもちろんのこと、RIB / FIB のハードウェアコンフィグレーションの個体差が大きくなっていると感じます。FIB のLPM (Longest Prefix Match) / LEM (Largest Exact Match) の塩梅まで制御するような取り組みも見られます。
正直なところ、やってみないとわからない。とくに「IPv4 unicast は128k routes までですっ」という製品に、ミスってフルルート入っちゃった場合のRIB / FIB のふるまいなどは予測できません。
また、VM ベースのルーター製品を使うことも増えました。思わぬボトルネックが存在することがあり、ネットワークに組み込む際にはコンバージェンスを気にしておく必要があります。
このような製品が悪というわけではなくて、利用可能な通信技術とハードウェアとソフトウェアをつかって、CAPEX + OPEX を最小化しつつ、要件を満たすネットワークをつくるのがネットワークエンジニアの腕の見せどころなので、避けて通るわけにはいきません。
頭の弱い製品を使ったとしても ネットワークとして安定すればいいわけです。
AS 外 / インターネット全体として
AS 内部のコンバージェンスがうまくいったとしても、インターネット全体として最適でない場合があります。コンバージェンスタイムは短いことが正義ではなく、お隣さんの処理速度に合わせてイベントをフロー制御することが理想です。
コンバージェンスが速すぎてNeighbor ルーターで無駄にCPU リソースを使い、かえって遅くなることもありますし、保守的に長く取りすぎてパケットロスを引き起こす こともあります。
ここでのフォーカス
うまくフィードバックをいれつつ インターネット全体で、特に自分のAS近辺で最適化することがゴールですが、まずはデバイス単体のRIB / FIB コンバージェンス観測を目的とします。
RIB / FIB コンバージェンスを計測する方法論
RFC7747 を参考にします。
eBGP の場合は
+------------+ +-----------+ +-----------+
| | | | | |
| | | | | |
| HLP | | DUT | | Emulator |
| (AS-X) |--------| (AS-Y) |-----------| (AS-Z) |
| | | | | |
| | | | | |
| | | | | |
+------------+ +-----------+ +-----------+
| |
| |
+--------------------------------------------+
Figure 2: Three-Node Setup for eBGP and iBGP Convergence
(https://tools.ietf.org/html/rfc7747)
このようなセットアップを使い、
5.1.2. RIB-OUT Convergence
Objective:
This test measures the convergence time taken by an implementation
to receive, install, and advertise a route using BGP.
(https://tools.ietf.org/html/rfc7747)
を計測します。
EmulatorからrouteA向けのパケットをHLPに流すEmulatorからrouteAをDUTに広告するDUTはrouteAをHLPに広告する- (1 . のパケットが
DUTに届き)DUTはrouteA向けのパケットをEmulatorに転送する
3. - 2. を routeA のRIB コンバージェンス、4. - 2. をrouteA のFIB コンバージェンスとします。
フルルートについて言えば、
最後の経路の 3. - 最初の経路の 2. がRIB コンバージェンス、最後の経路の 4. - 最初の経路の 2. がFIB コンバージェンスです。
処理するべき経路数によってふるまいが変わる場合があるため、コンバージェンスタイムの値だけで評価するのではなく、
- 単位時間あたりに受信した経路数 (上の2. に対応)
- 単位時間あたりに広告した経路数 (上の3. に対応)
- 単位時間あたりにFIB インストールした経路数
の時間変化をプロットするのがよさそうです。
単位時間あたりにFIB インストールした経路数?
これを実現する妙案が浮かんでいません。ブラックボックステストで実現するべきなので「外部からパケットを入れて出てくるか確認する」アプローチなのは間違いありませんが、全アドレス空間宛てのパケットを常時生成するのは困難なため、
- BGP Update 直前か ほぼ同時に、該当Prefix に含まれるいくつかのアドレス宛てにパケットを送信
- DUT (Device Under Test) がフォワードするかを確認
おそらくこの形になります。
ただし、1. でどのアドレスを選択するべきかはLPM ベースなのか / LEM ベースなのかで異なりますし、100,000コ目の経路を処理した瞬間に1コ目の経路がRIB / FIB に存在するかも確認したほうがいいかもしれません。
今のところ、このあたりちょっとアイデアがありません。
デバイスのstats を取っておきたい
計測中、デバイスのCPU 使用率、メモリ / RIB / FIB 使用量などを同時取得しておくとよさそう。
実装
機敏に動き、API を備えるgobgp を中心に実装してみます。
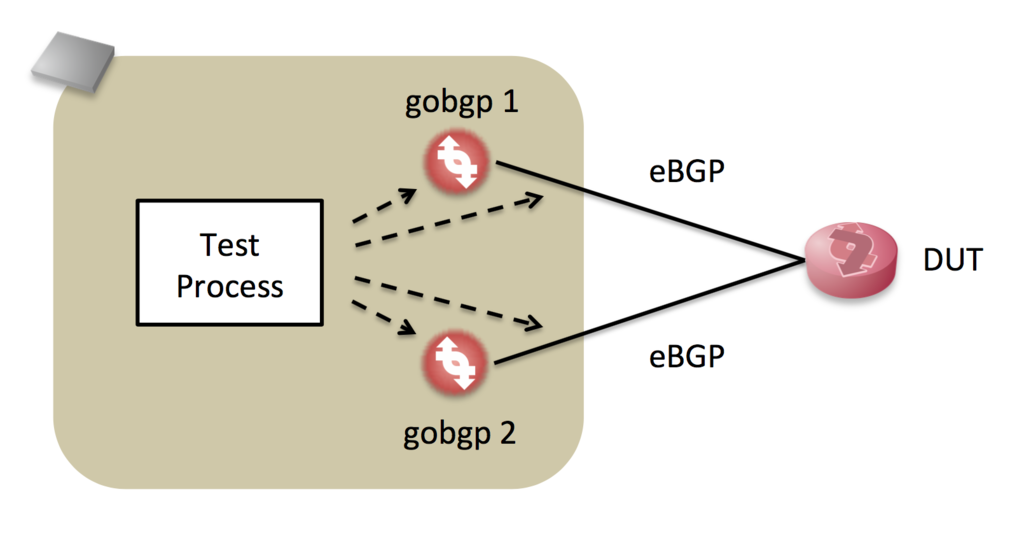
DUT で
- 新しい経路を受信した場合
- Best Path が変わった場合
- 経路がなくなった場合
それぞれ ふるまいが違う可能性があるため、次のようなシナリオでテストします。
gobgp 1からフルルートをDUTに送信gobgp 2からより強いフルルートをDUTに送信gobgp 2から2. のWithdraw をDUTに送信gobgp 1から1. のWithdraw をDUTに送信
2つのgobgp を制御して それぞれのシナリオに応じた経路を生成しつつ、それぞれの受信NLRI、送信NLRI を観測するプログラムを書きました。
経路は逐次生成ではなく、フルルートをロードしておいて送信ポリシーを reject → accept に変える、または accept → reject に変える、という方法で実装しています。
- gobgp 制御はgRPC でやる
- gobgp の動作を阻害したくないため、NLRI 観測にはlibpcap をつかう
- なるべくリアルタイムに処理し、将来的にはFIB コンバージェンス計測にパケットを生成するため、go で実装
- gobgp のgo APIとBGP パーサーを流用できるメリットもある
TCP を終端せず 観測者として動作させるためだけにTCP Reassemble を実装するのはアホらしいのですが、黙って実装します。
残念ながら、いまのところFIB コンバージェンスは計測できていません。
結果
このプログラムは上の4つのシナリオを順次実行し、結果をjson で保存します。
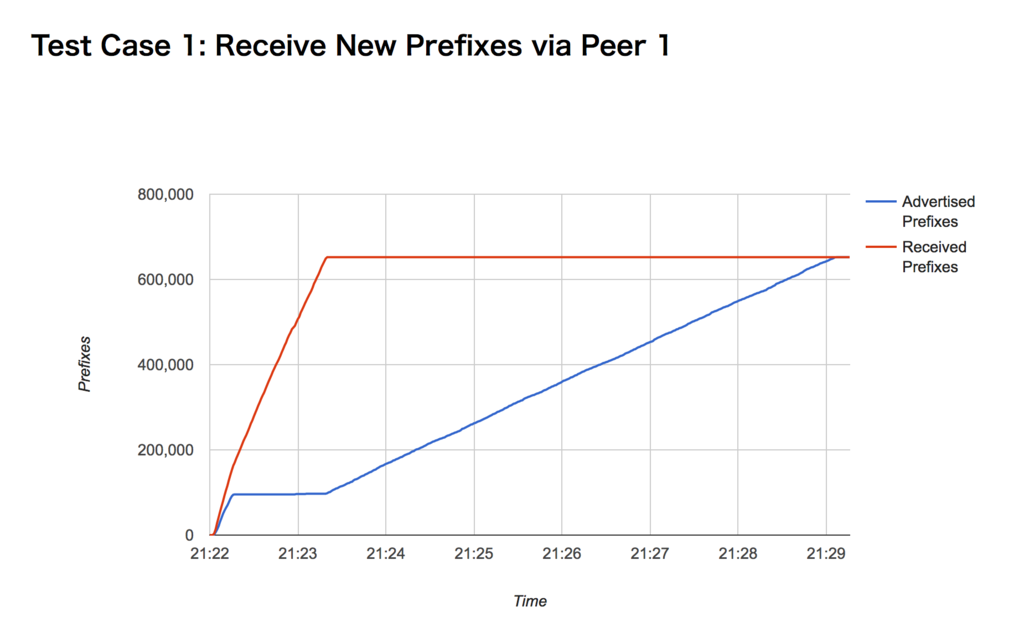
このチャートは あるVM ルーター製品のもので、毎秒の累積 送信/受信Prefix 数を描いています。テスト環境ではRIB コンバージェンスに7分かかることを示していて、経路数に対してほぼ線形であると予想できます。
コマンドラインオプションで経路数を指定できるので、実際に線形であるか確かめるシェルスクリプトも書けると思います。
余談ではありますが、この製品では、コンバージェンスまでの間CLI 上の送信経路数と実際の観測NLRI 数が大きく違っていました。
まとめ / これからやること
- 昨今のルーター製品、とくにL3 スイッチ製品のRIB コンバージェンスが予測できないため、ブラックボックステストを行う必要があると考えています
- その方法論について検討し、実装しました
- FIB コンバージェンス計測のためのアイデアがありません…コメントお待ちします!!
- gobgp がテストのボトルネックになる可能性があります。判断のヒントとなりそうな指標をチャートに載せるべきかもしれません
xlogin でコマンド自動投入→手動制御 を繰り返す
- コマンド群を入れる
- 手動制御
- 別のコマンド群を入れる
- 手動制御
- …
を大量デバイス上でやりたい、ということがありました。
これを少しいじると便利になります。
# configure.tcl source [file join [file dirname [info script]] juniper.tcl] run "configure set interfaces ge-0/0/0 description foo show | compare commit check " run " set interfaces ge-0/0/1 description bar show | compare commit check " run " exit show chassis routing-engine "
run の中身を入れ終わった後に手動制御になり、^n キーで自動制御に戻って次のrun に移ります。
configure.tcl の隣に juniper.tcl を置いておいてください。
実行例
codeout $ jlogin -s configure.tcl 192.168.0.81
192.168.0.81
set cli complete-on-space on
Enabling complete-on-space
codeout@vsrx> configure
Entering configuration mode
[edit]
codeout@vsrx# set interfaces ge-0/0/0 description foo
[edit]
codeout@vsrx# show | compare
[edit interfaces ge-0/0/0]
- description "new 1";
+ description foo;
[edit]
codeout@vsrx# commit check
configuration check succeeds
[edit]
codeout@vsrx# <-- ここで手動制御に
[edit]
codeout@vsrx# commit
commit complete
[edit]
codeout@vsrx# <-- ^n で自動に戻す
[edit]
codeout@vsrx# set interfaces ge-0/0/1 description bar
[edit]
codeout@vsrx# show | compare
[edit interfaces ge-0/0/1]
- description "new 2";
+ description bar;
[edit]
codeout@vsrx# commit check
configuration check succeeds
[edit]
codeout@vsrx# <-- ここで手動制御に
[edit]
codeout@vsrx# commit
commit complete
[edit]
codeout@vsrx# <-- ^n で自動に戻す
[edit]
codeout@vsrx# exit
Exiting configuration mode
codeout@vsrx> show chassis routing-engine
Routing Engine status:
Total memory 2048 MB Max 635 MB used ( 31 percent)
Control plane memory 1150 MB Max 449 MB used ( 39 percent)
Data plane memory 898 MB Max 189 MB used ( 21 percent)
CPU utilization:
User 0 percent
Background 0 percent
Kernel 0 percent
Interrupt 0 percent
Idle 100 percent
Model FIREFLY-PERIMETER RE
Start time 2017-06-13 14:34:07 UTC
Uptime 5 minutes, 48 seconds
Last reboot reason Router rebooted after a normal shutdown.
Load averages: 1 minute 5 minute 15 minute
0.01 0.10 0.07
codeout@vsrx> <-- ここで手動制御に
codeout@vsrx> % codeout $
jlogin の例でした。
Routing protocols' seed metrics for redistributing
When routes are redistributed into another routing protocol, their metrics are also translated to different values depending on vendor implementation and routing protocol which the routes are being redistributed to. Tables below show what value will be chosen when redistributing between protocols with no default metric configured explicitly, that is called as “seed metric”.
The seed metrics listed below are picked from Juniper vSRX and Cisco IOS-XRv default behavior.
Juniper vSRX
| from \ to | ospf | isis | rip | bgp (med) |
|---|---|---|---|---|
| direct | 0 (E2) |
0 (L1/L2) |
0 |
none |
| static | 0 (E2) |
0 (L1/L2) |
0 |
none |
| ospf | – | ospf metric (L1/L2) | 0 |
ospf metric |
| isis | isis metric (E2) | – | 0 |
none |
| rip | rip metric (E2) | rip metric (L1/L2) | – | rip metric |
| aggregate | 0 (E2) |
10 (L1/L2) |
0 |
none |
| bgp | bgp med (E2) | 10 (L1/L2) |
0 |
– |
Cisco IOS-XRv
| from \ to | eigrp | ospf | isis | rip | bgp (med) |
|---|---|---|---|---|---|
| connected | variable (*1) | 20 (E2) |
0 (L2) |
(x) variable | 0 |
| static | (x) 2^32-1 |
20 (E2) |
0 (L2) |
(x) variable | 0 |
| eigrp | – | 20 (E2) |
0 (L2) |
(x) variable | eigrp metric |
| ospf | (x) 2^32-1 |
– | 0 (L2) |
(x) variable | ospf metric |
| isis | (x) 2^32-1 |
20 (E2) |
– | (x) variable | isis metric |
| rip | (x) 2^32-1 |
20 (E2) |
0 (L2) |
– | rip metric |
| bgp | (x) 2^32-1 (*2) |
1 (E2) (*2) |
0 (L2) (*2) |
(x) variable | – |
- (x):
default-metricmust be configured to redistribute- (x)
2^32-1: Default metric is squashed by max value even whendefault-metricis configured. Note that redistribution cannot be done withoutdefault-metric. - (x) variable: Metric specified by
default-metricis assigned.
- (x)
- (*1): Composite metric calculated from interface metrics
- (*2):
router bgp <ASN>; bgp redistribute-internalstatement is required to restribute
inet-henge にいくつか機能を足した
2020-02-25追記: SVG DOM が変更になったため、この記事のCSS ではスタイルが壊れるかもしれません。こちら も参考にしてください。
inet-henge というネットワーク図生成ライブラリーに
- リンク太さを変えられる
- リンク両端に加え,中央にラベルを置ける
地味な機能を足した.
inet-henge とは?
JSON データを元にネットワーク図を生成してくれる js ライブラリー.オートレイアウトする.
このようなコンセプトで作っている.
- 自動更新
- 入力少なく
- このくらいの外部データから生成したい.手動でレイアウトしたくない
{ "nodes": [{ "name": "A" },{ "name": "B" }], "links": [{ "source": "A", "target": "B" }] }
美しくなくていい.見てわかる範囲でやってくれれば OK
動かしたい
- 運用しながら / 設計しながら見る.デバイスやPOP 単位でノードを動かしたい
- レイアウトは保存しなくてもいい.再計算しても毎回結果が同じならOK
- ズームしたい.ある程度拡大したときのみ細かい情報を表示したい
- ブラウザでネットワーク図を表示したその画面で実現したい.ドキュメント内でもやりたい
デモ
https://youtu.be/3ZREgY2FGBkyoutu.be
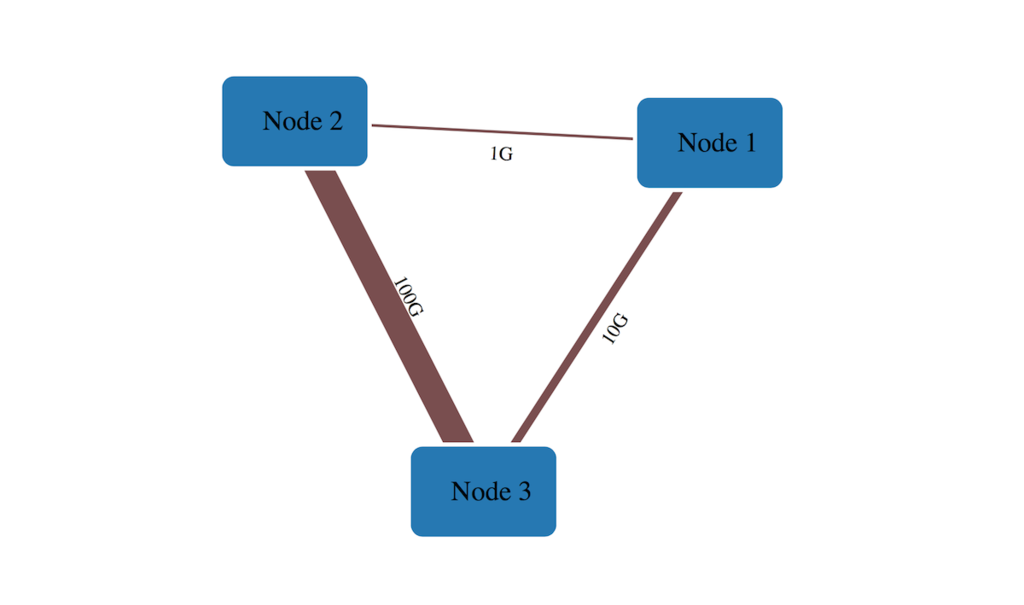
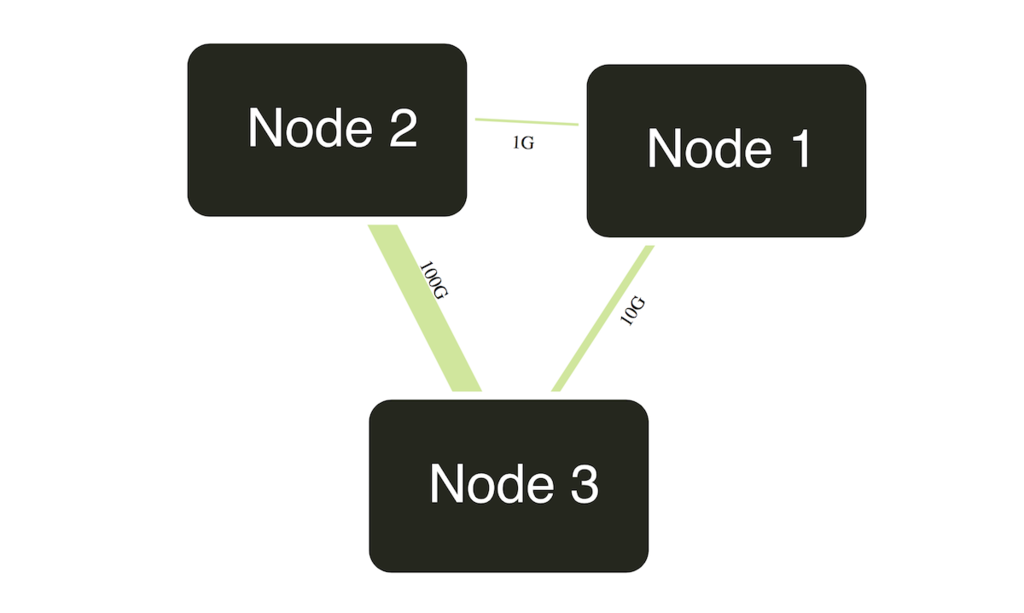
リンク太さを変える
こんな感じでメタデータを定義しておいて 👇
"links": [ { "source": "Node 1", "target": "Node 2", "meta": { "bandwidth": "1G" }}, { "source": "Node 1", "target": "Node 3", "meta": { "bandwidth": "10G" }}, { "source": "Node 2", "target": "Node 3", "meta": { "bandwidth": "100G" }} ]
こんな感じで描画する.👇 メタデータをもとにSVG のstroke-width を返す関数を渡す.
var diagram = new Diagram('#diagram', 'index.json'); diagram.link_width(function (link) { if (!link) return 1; // px else if (link.bandwidth === '100G') return 10; // px else if (link.bandwidth === '10G') return 3; // px }); diagram.init('bandwidth');
何も返さない場合はSVG のデフォルト = 1px になる.
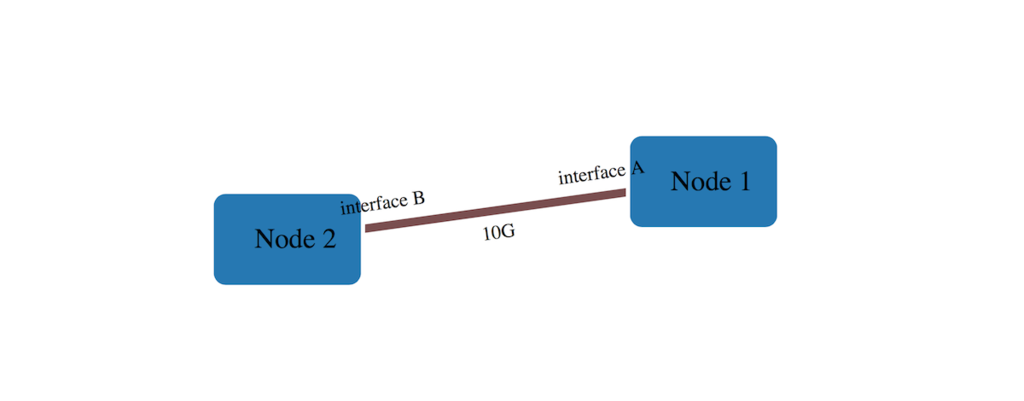
リンクにラベルを置く
こんな感じのリンク情報があったとすると 👇
"links": [ { "source": "Node 1", "target": "Node 2", "meta": { "bandwidth": "10G", "intf-name": { "source": "interface A", "target": "interface B" } } } ]
こう書くことで 👇
new Diagram('#diagram', 'index.json').init('bandwidth', 'intf-name');
こうなる 👇
スタイルを変える
(追加機能ではないけれど) inet-henge はSVG を出力するので,CSS でスタイルを変えることができる.
.node rect { fill: #25271e !important; transform: scale(2) translate(-13px, -5px); } .node text { font-family: sans-serif; fill: #fff; font-size: 20px; transform: translate(0, 5px) } .link { stroke: #d0e799; stroke-opacity: 1; }
今後
- LAG をうまく表現できない.なんとかしたい
- ノード / リンクが増えたときのパフォーマンスが問題.アルゴリズムの調整,計算結果の再利用など考えないといけない
もしご意見などありましたら…気軽にお声がけください!
Large BGP Community がやってくる前に,Community マッチをおさらいしよう
2017 / 02月,BGP Large Communities Attribute (RFC8092) がRFC 化された.
これは新たに 4Bytes:4Bytes:4Bytes のBGP Community を使えるようにするもので,既存の
- BGP Community (RFC1997) -
2Bytes:2Bytes - Extended BGP Community (RFC4360) -
4Bytes:2Bytesもしくは2Bytes:4Bytes
に比べて空間を広く使うことができる.BGP Community の先頭2バイト(もしくは4バイト) はGlobal Administrator と呼ばれ,ふつうは事業者のグローバルAS番号をあてる.加えて操作対象のAS番号,たとえば顧客のAS番号をBGP Community に含めたいケースがあり,これまでのBGP Community では空間が足りなかった.
近々BGP Community 空間が拡張されるにあたり「いま設定しているBGP Community 正規表現だいじょうぶなんだっけ?」と思って,いくつかの実装でマッチ方法を復習した.
Community マッチ方法
Juniper JUNOS
- Community 表現(横) がマッチ対象(縦) にマッチするか
- アルファベットはBGP Community を10進で表現したときの1ケタ.4ケタ = 2Bytes,6ケタ = 4Bytes
- Large BGP Community 実装はなさそう
| ⬇️対象 \ 表現➡️ | bbb:xxx | bbb:xxx.* | bbbL:xxx.* |
|---|---|---|---|
| bbb:xxx | ⭕️ する | ⭕️ する | ❌ しない |
| abbb:xxx | ❌ しない | ⭕️ する | ❌ しない |
| target:abbb:xxx | ❌ しない | ⭕️ する | ❌ しない |
| target:aaabbb:xxx | ❌ しない | ❌ しない | ⭕️ する |
| bbb:xxxy | ❌ しない | ⭕️ する | ❌ しない |
想像するに
Lキーワードの有無で長さマッチ\d+:\d+パターンであれば^\d+:\d+$と解釈.それ以外はそのまま
Cisco IOS-XR
- 正規表現(横) がマッチ対象(縦) にマッチするか
- アルファベットはBGP Community を10進で表現したときの1ケタ.4ケタ = 2Bytes
community-setの例.ほかにextcommunity-setキーワードがある- Large BGP Community 実装はなさそう
| ⬇️対象 \ 表現➡️ | bbb:xxx | bbb:* | ios-regex ‘bbb:xxx’ | ios-regex ‘bbb:xxx.*’ |
|---|---|---|---|---|
| bbb:xxx | ⭕️ する | ⭕️ する | ⭕️ する | ⭕️ する |
| abbb:xxx | ❌ しない | ❌ しない | ⭕️ する | ⭕️ する |
| target:abbb:xxx | ❌ しない | ❌ しない | ❌ しない | ❌ しない |
| target:aaabbb:xxx | ❌ しない | ❌ しない | ❌ しない | ❌ しない |
| bbb:xxxy | ❌ しない | ⭕️ する | ⭕️ する | ⭕️ する |
想像するに
community-setキーワード,extcommunity-setキーワードで分離.異なるものにマッチしない- ワイルドカードは 文頭 / 文末 を前提にしてマッチ
- 正規表現は 文頭 / 文末 でなくてもマッチ
gobgp
- 正規表現(横) がマッチ対象(縦) にマッチするか
- アルファベットはBGP Community を10進で表現したときの1ケタ.4ケタ = 2Bytes,6ケタ = 4Bytes
communityの例.ほかにext-community,large-communityキーワードがある- Large BGP Community 対応バージョン
| ⬇️対象 \ 表現➡️ | bbb:xxx | bbb:xxx.* |
|---|---|---|
| bbb:xxx | ⭕️ する | ⭕️ する |
| abbb:xxx | ❌ しない | ⭕️ する |
| target:abbb:xxx | ❌ しない | ❌ しない |
| target:aaabbb:xxx | ❌ しない | ❌ しない |
| bbb:xxxy | ❌ しない | ⭕️ する |
| aaa:bbb:xxx | ❌ しない | ❌ しない |
community,ext-community,large-communityキーワードで分離.異なるものにマッチしない\d+:\d+パターンであれば^\d+:\d+$と解釈.それ以外はそのまま
Quagga
- 正規表現(横) がマッチ対象(縦) にマッチするか
- アルファベットはBGP Community を10進で表現したときの1ケタ.4ケタ = 2Bytes,6ケタ = 4Bytes
community-listの例.ほかにextcommunity-list,large-community-listキーワードがある- Large BGP Community 対応バージョン
| ⬇️対象 \ 表現➡️ | bbb:xxx | bbb:xxx.* |
|---|---|---|
| bbb:xxx | ⭕️ する | ⭕️ する |
| abbb:xxx | ⭕️ する | ⭕️ する |
| target:abbb:xxx | ❌ しない | ❌ しない |
| target:aaabbb:xxx | ❌ しない | ❌ しない |
| bbb:xxxy | ⭕️ する | ⭕️ する |
| aaa:bbb:xxx | ❌ しない | ❌ しない |
community-list,extcommunity-list,large-community-listキーワードで分離.異なるものにマッチしない- そのまま正規表現マッチ
Large BGP Community に対する懸念
2バイトの5ケタAS事業者が^ccccc:xxx$ と書くべきところを「ふつう2Bytes:2Bytes だし」とサボってccccc:xxx$ と書いてしまった場合に,意図しないLarge BGP Community にマッチして誤動作しないかを気にしていた.aaa:ccccc:xxx やaaa:bccccc:xxx にマッチするかもなと.
4ケタ以下事業者は^ 忘れてないだろうし,4バイト事業者はうまくBGP Community を使えていないのでは と思われるので,問題になるとすれば2バイト5ケタかなと.
上記のようにまとめてみると,各実装とも既存の2Bytes:2Bytes Community と4Bytes:4Bytes:4Bytes のLarge BGP Community をキーワードで分離させる方針のようなので,杞憂かもしれない.
(JUNOS でExtended Community にマッチしてしまう細かな問題はあるかもしれない)
JUNOS のL キーワードはこれでいいんだっけ?
「4バイトの場合はL キーワードを使え」とドキュメントに書いているが,4Bytes:2Bytes もしくは 2Bytes:4Bytes だけであればこれでよかった.ところが4Bytes:4Bytes:4Bytes になると破綻するように思う.
aaa:bbb:ccc のうち,aaa はAS番号固定かもしれないが,bbb, ccc は2バイトレンジかもしれないし,4バイトレンジかもしれない.L の有無について4パターン併記しないといけない? それはつらい.
どういう実装で出してくるか楽しみだが,「L キーワードは捨てて,あらゆるCommunity について文頭~文末まで正規表現で文字列マッチします」というのがかえって分かりやすい気がする.
*1:手元に古いのしかなかった 😭
ステルスWiFi AP を駆逐した
macos がステルスWiFi AP に接続したときに脅してくるこれ,しばらく意味が分からなくて放置していた.
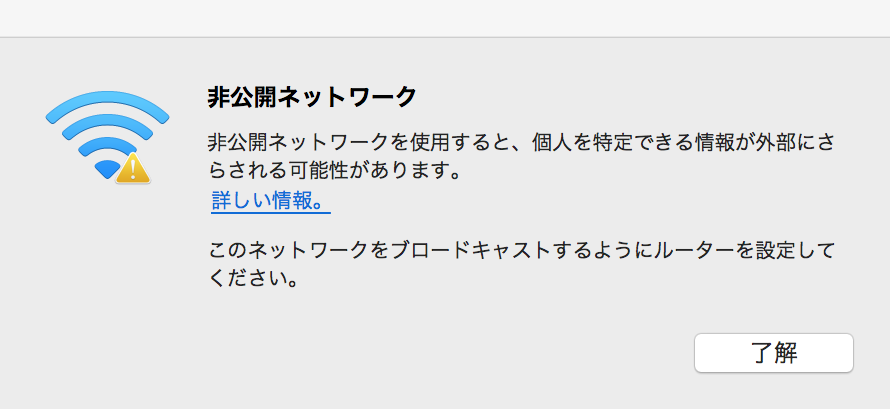
たぶんこういうことかな,というのを教えてもらって「なるほど,良くないかもしれん」と思い駆逐した.
SSIDをstealth設定にしているAPにつなぐと、以後
— Seigo Yoshino (@syoshino) 2017年1月7日
その端末は、そのSSIDを探すprobeをactiveに投げるようになるので、黙っている端末よりリスクあるよ、という事だと思います
ステルスAP が接続リストにいるリスク
アクティブにProbe Request を投げるため,接続可能なSSID の一部が漏れるから.せっかくMac Randomization してもSSID がリストで漏れており,個体識別されるリスクが高まる.ステルスじゃなくしたら漏れないかというと そうではないので「漏れやすさ」の問題.
ステルスAP が設定されているmacos 10.12.2 とIOS 10.2 の動き
ちゃんと調べたわけではありません.もし違っていたらご指摘ください.あれこれ操作したときの振る舞いを1時間くらい観察しました.
- ステルスなSSID を探して,すべてのSSID についてProbe Request を投げまくる
ステルスAP に接続中のときも,そのSSID を含めて投げまくる
違うAP がそのSSID を偽装したら
- 正規のステルスAP がいない環境で,偽のステルスAP (SSID 同じ,認証なし) をつくる
- 自動でそいつに接続することはなかった
ステルスAP が設定されていないmacos 10.12.2 とIOS 10.2 の動き
- WiFi をON にした瞬間はActive Scan する = Probe Request を投げる
- 放っておくとIOS 10.2 はActive Scan する
- 端末がSleep しているのと関係あるかも (くわしく調べてない)
- macos はそんな動きをしない (こちらはSleep していない)
- それ以外SSID を投げていない.
かなりProbe Request が減った.
ステルスをやめる
そもそもステルスにしていたのは視界に入れたくなかったから.ほとんどメンテ不要なやつは消えていてほしい.とはいうものの,どこに持ち込むかわからない端末のほうのセキュリティリスクを下げたい.ステルスをやめることでAP のセキュリティリスクはさほど上がらない.
a/b/g/n/ac など広く802.11 を受けられる端末で
sudo tcpdump -I -ien0 -e -s0 type mgt subtype probe-req
を実行しつつ,一台ずつWiFI off/on してヘンなSSID を投げなくなるまで設定を削除した.
IOS はAP が存在しないと消せないので面倒だが,めちゃくちゃ古いSSID を探していて「おお…こいつ…こんなになっても〇〇を覚えてるのか…」って感傷的になれるのでオススメです.
BGP Community を透過する事業者がどれくらいいるか調べた
11月末にInternet Week 2016 というイベントで,「BGP Community の基本設計」について発表してきた.内容については 発表スライド をご覧いただければ良いかな と思うが,壇上から挙手アンケートを取ってみてびっくりした.
「顧客から受信したBGP Community を消さずに透過しているかた,どのくらいいますか?」の結果が 1%ほどだった.
該当するけど手を上げられなかった方もいると思うし,母数として全員がAS 運用者じゃなかったかもしれない.が,「えっ! 少なすぎる!」と思った.世の中そんなもんなのかな,と思ってざっと調査した内容を書いておく.
結果から書いておくと「割合的にはまあそんなもん」だった.
BGP Community は API なんですよ
BGP Community は「便利なタグ」だったり「他社ネットワーク内での自社経路のふるまいを定義できるノブ」だったりする.たとえば
- 経路がネットワークに入ってきたのはどの国か,顧客に伝えるタグ
- 他社ネットワーク内でLocal Preference を下げるためのノブ
のように,BGP プロトコルの範囲のなかで付加価値をつけることができる.「HTTP(S) でやれば?」という考えも頭をよぎるが,IP レイヤーの操作をさらに上のレイヤーに依存するのは危険かもしれないし,レイヤーをまたぎすぎている感がある.「HTTP(S) でもできる」が理想だけれど,IP ならではの柔軟性と拡張性を得るためにもBGP プロトコルでやりたいところ.

上のように AS65000 がBGP Community に乗せて便利情報を提供してくれている場合,AS65001 の立場からすると「自社に不利益がある」「AS65000 の利用規約に反する」ような場合を除いてAS65002 に透過しない理由はないはず.逆もしかりで,AS65002 が「AS65000 内での経路のふるまいを制御したい」と考えているとしてAS65001 がそれを遮断する理由はないように思う.
が,アンケート結果では「でも止めてる」だし,観測範囲内でも止めてる事業者がほとんどに見える.
特にAS65002 がAS65001 の顧客だった場合,情報を透過するほうがAS65001 サービスの付加価値につながりそうだし,ぜんぶ透過しなくても工夫してやればいいのに…と思う.
「将来,トランジット事業者(上の絵でいえばAS65000) を変えるかもしれない」という懸念はあるが,トランジット事業者が似たAPI を提供してさえすればAS65001 で変換するのがよさそう.他社のサービスや製品を組み合わせてうまいこと抽象化することは,サービスを作る側の手腕の見せ所かな と思う.
調査結果
AS間の関係を transit / peer / customer / unknown に分類し「X から受信したBGP Community をY に透過する事業者数」を数えた.調査の方法はあとで.
たとえば transit からcustomer に向かう矢印は93 だが,「transit から受信したBGP Community をcustomer に透過するAS は93 個あった」という意味.4バイトAS は除外してカウントしている.

BGPlay コレクターの配置的にすべてのAS をカバーしていないかもしれないが,フルルートの1/11 ほどのサンプル数.
- customer から受信した経路を透過する事業者が比較的多そう
- 送信先によって透過 / 不透過を区別してそう
- 特にtransit 方向にはフィルターしてそう
- 実際に使われている2バイトAS 約6万個に対して,透過しているAS はおよそ1% 程度しかない
ということがわかる.unknown が多いのは,参照したAS間の関係データベースが良くなかったかもしれない.
調査方法
BGPlay と The CAIDA UCSD as-relationships - 20161201 のデータを使った.
2バイトAS のすべてについて
- そのAS がoriginate している適当な1 prefix を選ぶ
- BGPlay でBGP Community が透過しているかどうか調べ,AS_PATH 上の各AS について transit / peer / customer のどれからどれに送信する際に透過するかをマークする
- AS 間の関係についてはCAIDA のas-relationships を参照する
仮定として
- BGPlay コレクターはcustomer 相当と考える
- BGP Community のGlobal Administrator がAS_PATH 上に現れるもののみをカウント
- 現れない場合,BGP Community がどこでつけられたか判別できない
- そのBGP Community は,AS_PATH 上のGlobal Administrator より右でつけられたものと考える
たとえば
- AS_PATH: 65000 65001 65002 65003
- BGP Community: 65002:100
の場合
- Community は65002 か65003 でつけられたと仮定
- → 65001 はCommunity を透過する
- 65001 から見て65002 は transit で,65000 は customer
- → 65001 は transit から受信したBGP Community を customer に透過する
- 65000 から見て65001 は customer で,BGPlay コレクターも customer
- → 65000 は customer から受信したBGP Community をcustomer に透過する
経路数でいえばフルルート68万経路に対して6万経路分,1/11 サンプルを調査した.BGPlay コレクターの配置から「透過しているんだけど観測できない」AS があることにも注意.
なお,今回は割合を概算したかったので 4バイトAS は除外してカウントしている.
Internet Week 2016 発表スライド
発表スライドをリンクしておきます.
- AS 運用者向け
- BGP Community 設計のコツ
- API と思って設計しよう
のような内容です.よければご覧ください.
https://speakerdeck.com/codeout/bgp-communityfalse-ji-ben-she-ji