local-as と as-override を併用したときのルーティング
大抵のルーターには、local-as / as-override という機能があります。
- local-as
- 一部のneighborに対し、自分自身のオリジナルAS番号とは別のAS番号としてふるまう
- as-override
- 一部のneighborに対し、AS_PATH中の該当peer ASを自分のAS番号に置換して経路広告する
それぞれ単独ではそこそこ見るものの、コンボで使う機会はありませんでした。実際使ってみるとよくわからない動きをします。 as-overrideはAS番号を置換しますが、local-asも指定した場合「オリジナルAS番号」「local-as番号」どちらを採用するか曖昧そうですよね。オプションによってもふるまいが変わりそうです。
「公式ドキュメントを読んで筋が通っているとは思えないので全数チェックしました」がこの記事です。
試したこと
今回試したのはJuniperです。
| platform | version |
|---|---|
| VMx | 21.1R3.11 |
local-as autonomous-system <loops number> <private | alias> <no-prepend-global-as>;
local-as にはいくつかオプションがありますが、その全パターン x as-override あり / なしを試しました。
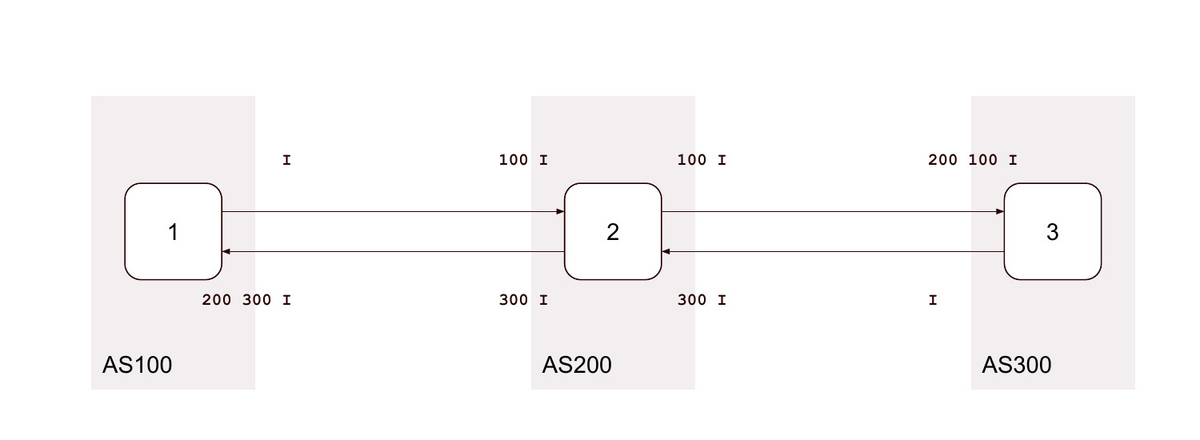
👇 はデフォルト ( local-as なし as-override なし) の状態です。
ここから AS200 の AS100 向けpeerの設定を変え、各ASの送受信経路を記録します。
参考までに Cisco でも
local-as number [no-prepend [replace-as [dual-as]]]
のようなオプションは存在します。今回調べていませんが、似たような事情があるかもしれません。
結果
# がリンクになっています。
| # | local-as XXX |
loop |
private |
alias |
no-prepend-global-as |
as-override |
|---|---|---|---|---|---|---|
| 0 | ||||||
| 1 | 無関係なAS | |||||
| 2 | 無関係なAS | ⭕️ | - | |||
| 3 | 無関係なAS | - | ⭕️ | - | ||
| 4 | 無関係なAS | - | ⭕️ | |||
| 5 | 無関係なAS | ⭕️ | - | ⭕️ | ||
| 6 | 背後のAS | |||||
| 7 | 背後のAS | ⭕️ | - | |||
| 8 | 背後のAS | - | ⭕️ | - | ||
| 9 | 背後のAS | - | ⭕️ | |||
| 10 | 背後のAS | ⭕️ | - | ⭕️ | ||
| 略 | 無関係なAS | ⭕️ | ||||
| 略 | 無関係なAS | ⭕️ | ⭕️ | - | ||
| 略 | 無関係なAS | ⭕️ | - | ⭕️ | - | |
| 略 | 無関係なAS | ⭕️ | - | ⭕️ | ||
| 略 | 無関係なAS | ⭕️ | ⭕️ | - | ⭕️ | |
| 11 | 背後のAS | ⭕️ | ||||
| 12 | 背後のAS | ⭕️ | ⭕️ | - | ||
| 13 | 背後のAS | ⭕️ | - | ⭕️ | - | |
| 14 | 背後のAS | ⭕️ | - | ⭕️ | ||
| 15 | 背後のAS | ⭕️ | ⭕️ | - | ⭕️ | |
| 16 | ⭕️ | |||||
| 17 | 無関係なAS | ⭕️ | ||||
| 18 | 無関係なAS | ⭕️ | - | ⭕️ | ||
| 19 | 無関係なAS | - | ⭕️ | - | ⭕️ | |
| 20 | 無関係なAS | - | ⭕️ | ⭕️ | ||
| 21 | 無関係なAS | ⭕️ | - | ⭕️ | ⭕️ | |
| 22 | 背後のAS | ⭕️ | ||||
| 23 | 背後のAS | ⭕️ | - | ⭕️ | ||
| 24 | 背後のAS | - | ⭕️ | - | ⭕️ | |
| 25 | 背後のAS | - | ⭕️ | ⭕️ | ||
| 26 | 背後のAS | ⭕️ | - | ⭕️ | ⭕️ | |
| 略 | 無関係なAS | ⭕️ | ⭕️ | |||
| 略 | 無関係なAS | ⭕️ | ⭕️ | - | ⭕️ | |
| 略 | 無関係なAS | ⭕️ | - | ⭕️ | - | ⭕️ |
| 略 | 無関係なAS | ⭕️ | - | ⭕️ | ⭕️ | |
| 略 | 無関係なAS | ⭕️ | ⭕️ | - | ⭕️ | ⭕️ |
| 27 | 背後のAS | ⭕️ | ⭕️ | |||
| 28 | 背後のAS | ⭕️ | ⭕️ | - | ⭕️ | |
| 29 | 背後のAS | ⭕️ | - | ⭕️ | - | ⭕️ |
| 30 | 背後のAS | ⭕️ | - | ⭕️ | ⭕️ | |
| 31 | 背後のAS | ⭕️ | ⭕️ | - | ⭕️ | ⭕️ |
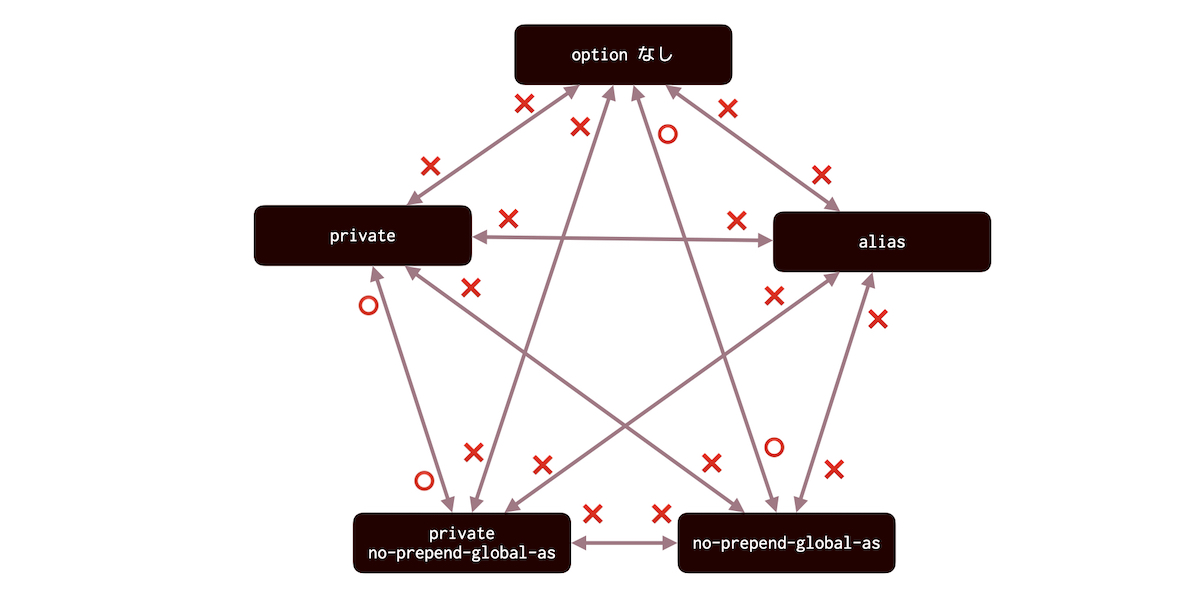
privateとaliasは排他ですaliasとno-prepend-global-asは排他です
0. local-as なし as-override なし (デフォルト)
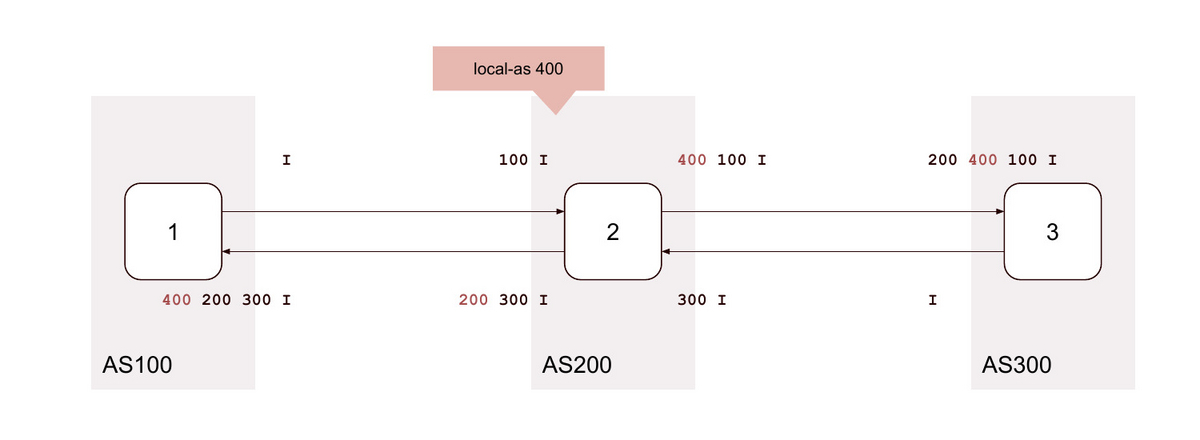
1. local-as <無関係なAS>
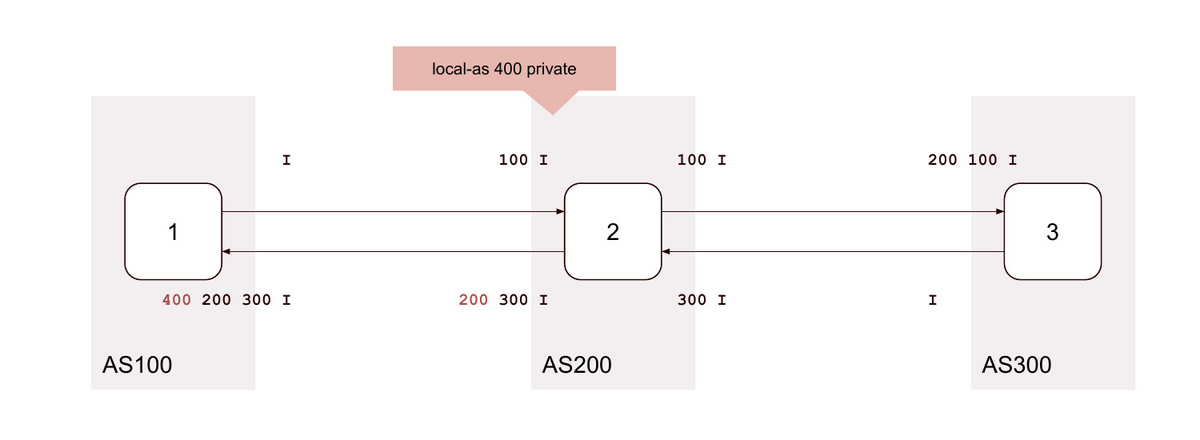
2. local-as <無関係なAS> private
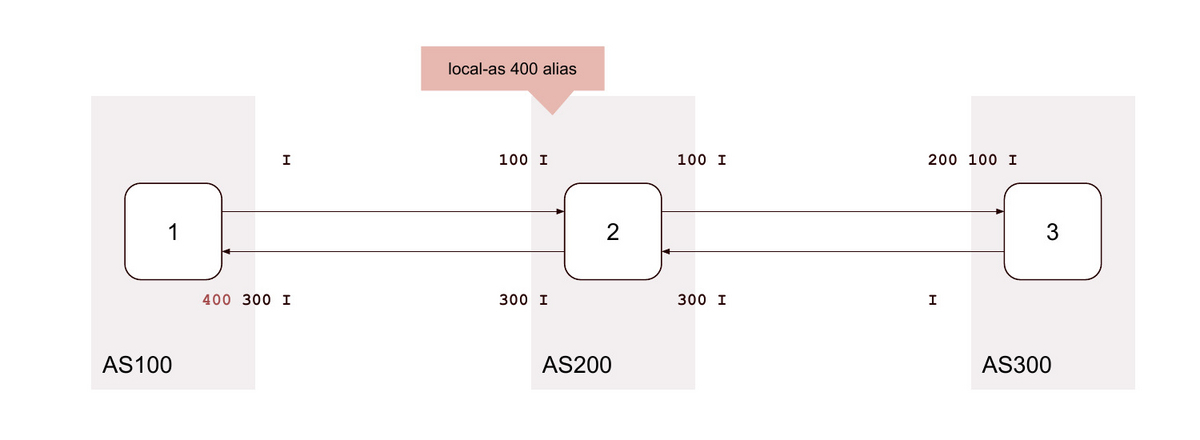
3. local-as <無関係なAS> alias
4. local-as <無関係なAS> no-prepend-global-as
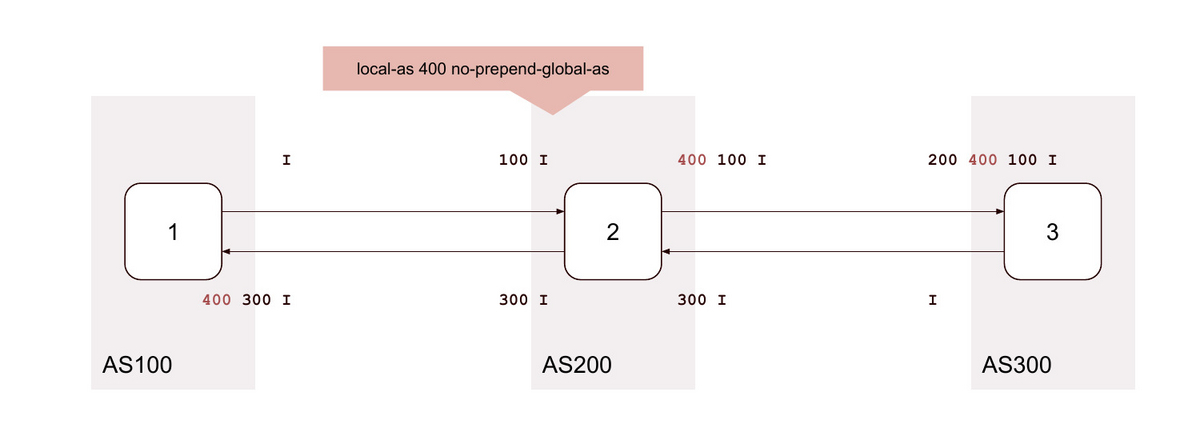
5. local-as <無関係なAS> private no-prepend-global-as
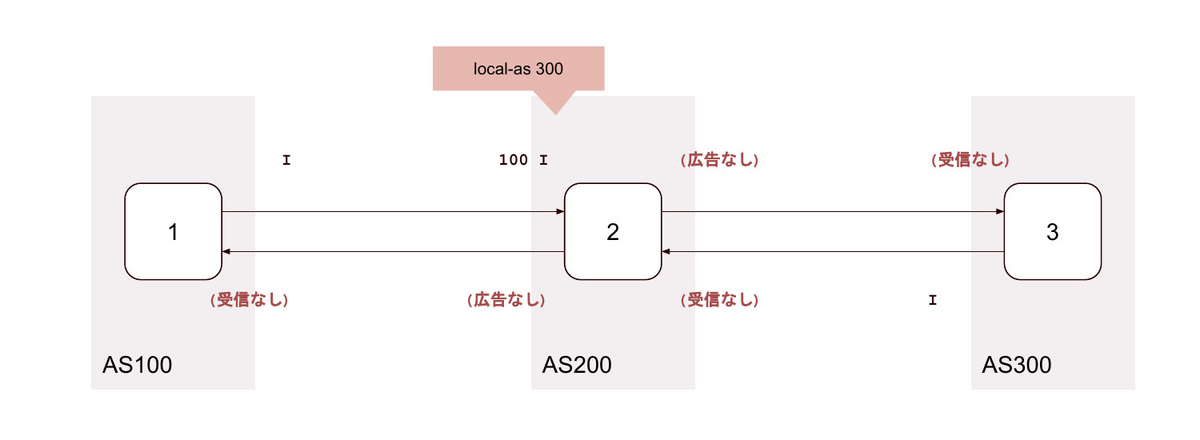
6. local-as <背後のAS>
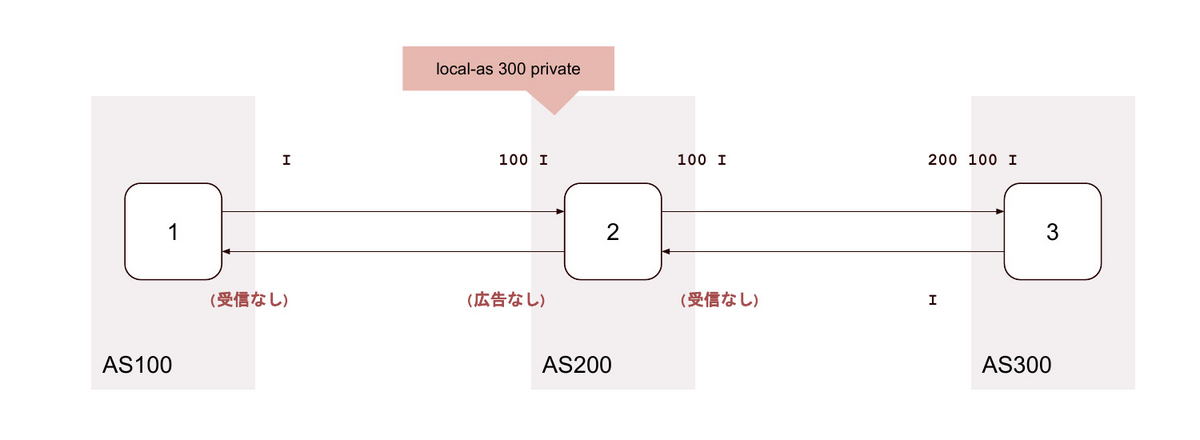
7. local-as <背後のAS> private
8. local-as <背後のAS> alias
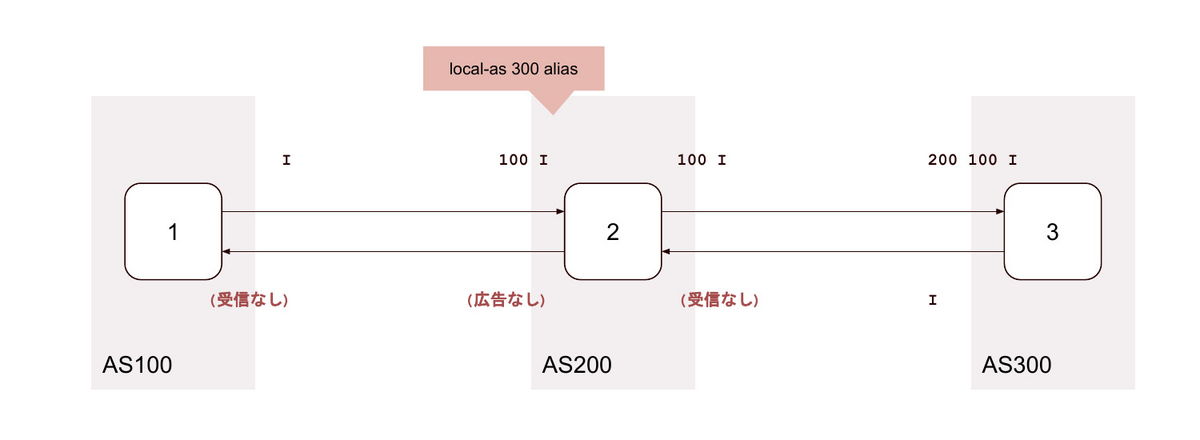
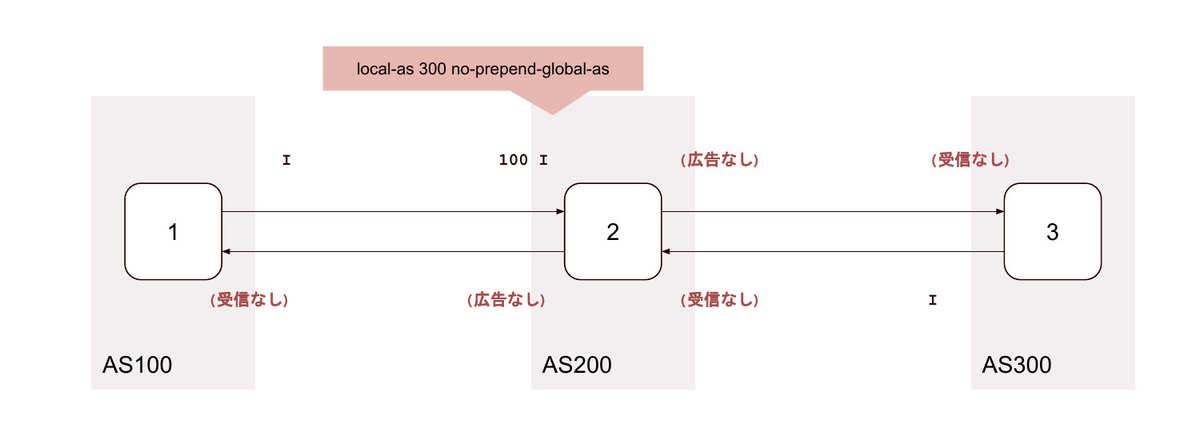
9. local-as <背後のAS> no-prepend-global-as
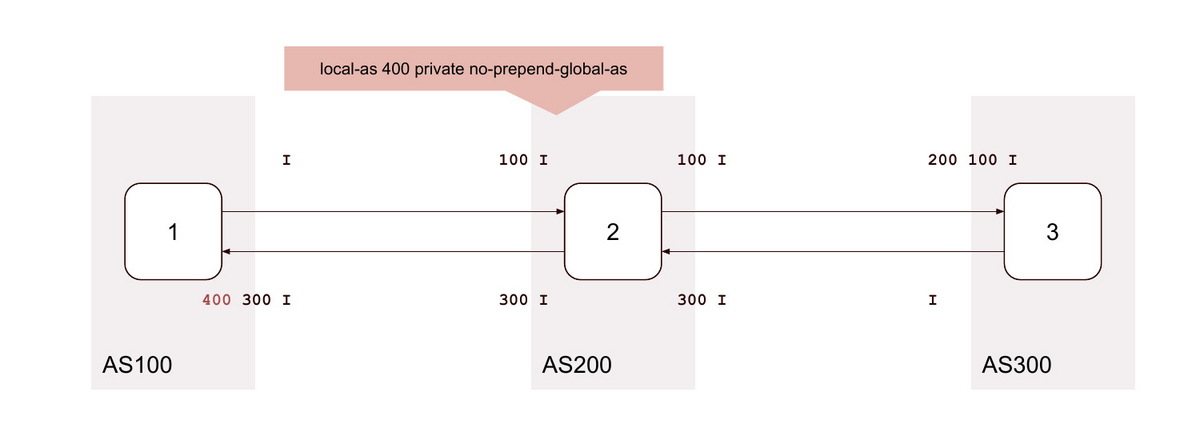
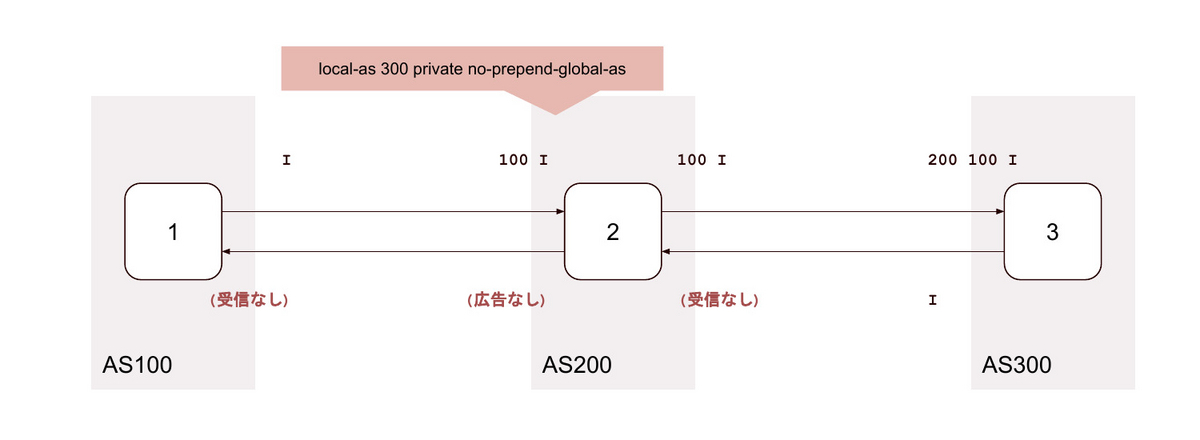
10. local-as <背後のAS> private no-prepend-global-as
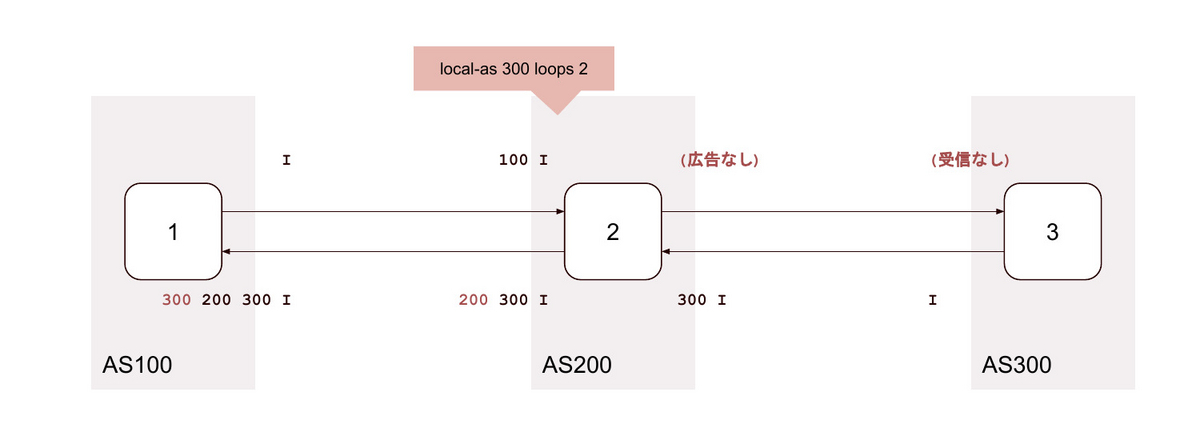
11. local-as <背後のAS> loop 2
12. local-as <背後のAS> loop 2 private
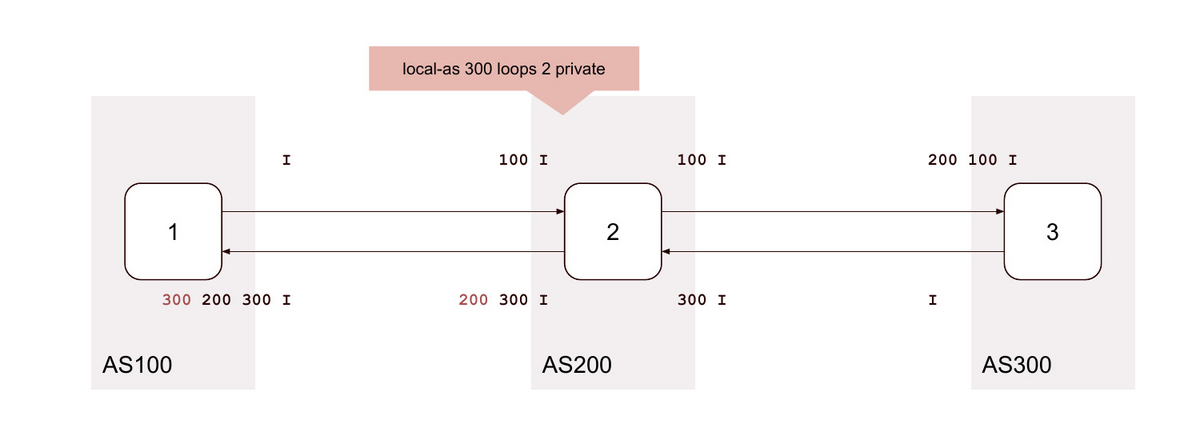
13. local-as <背後のAS> loop 2 alias
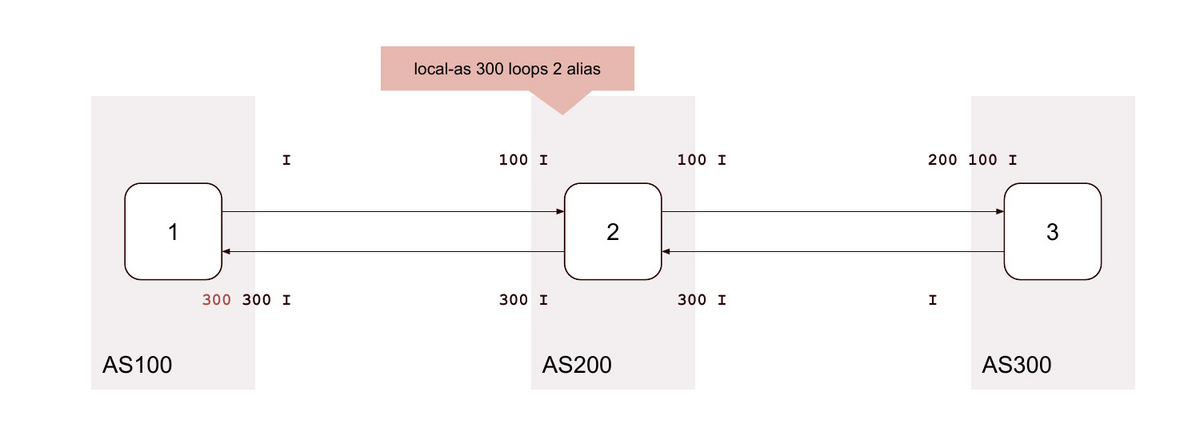
14. local-as <背後のAS> loop 2 no-prepend-global-as
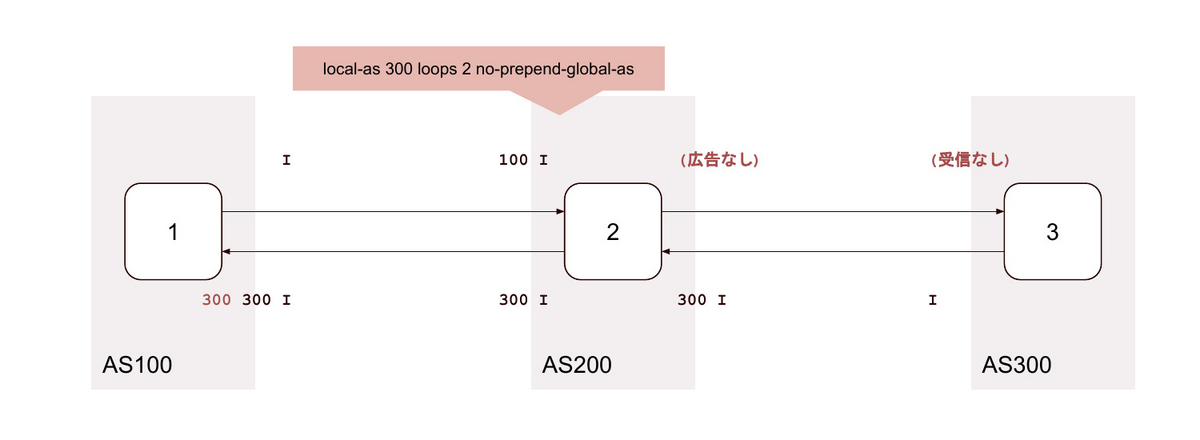
15. local-as <背後のAS> loop 2 private no-prepend-global-as
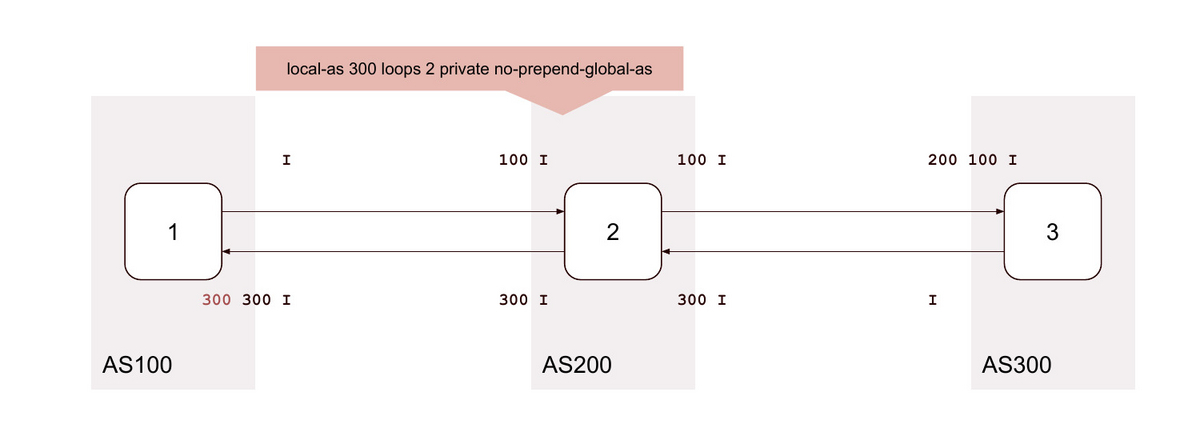
16. as-override
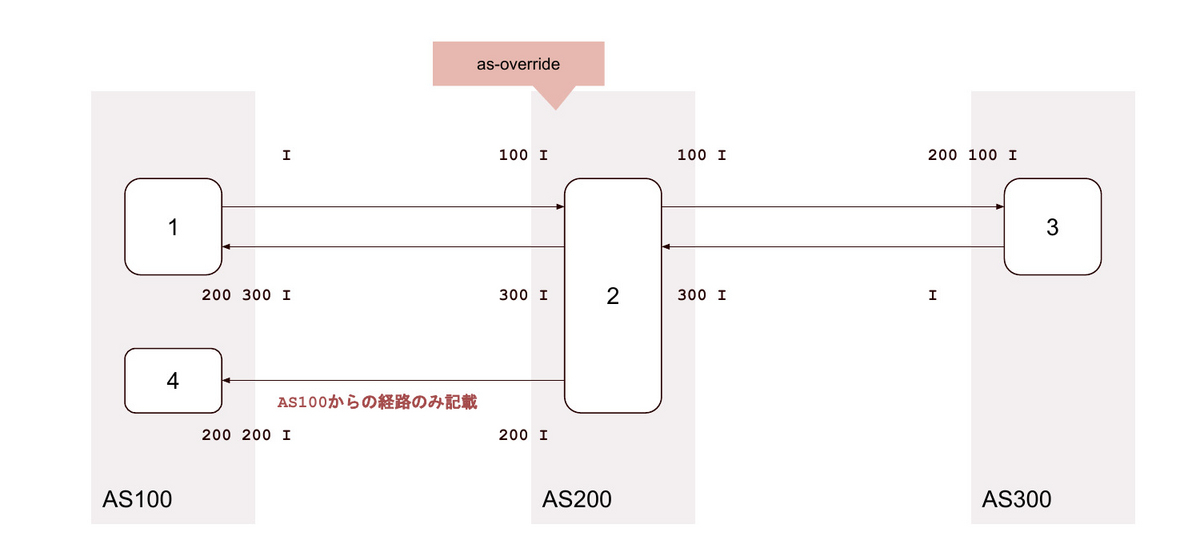
17.local-as <無関係なAS> / as-override
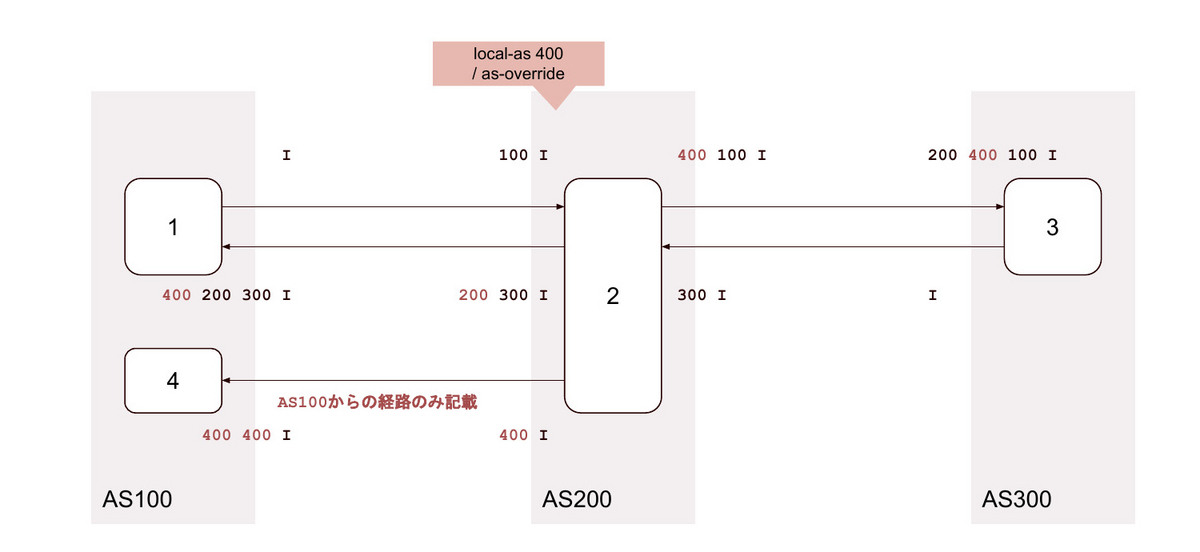
18. local-as <無関係なAS> private / as-override
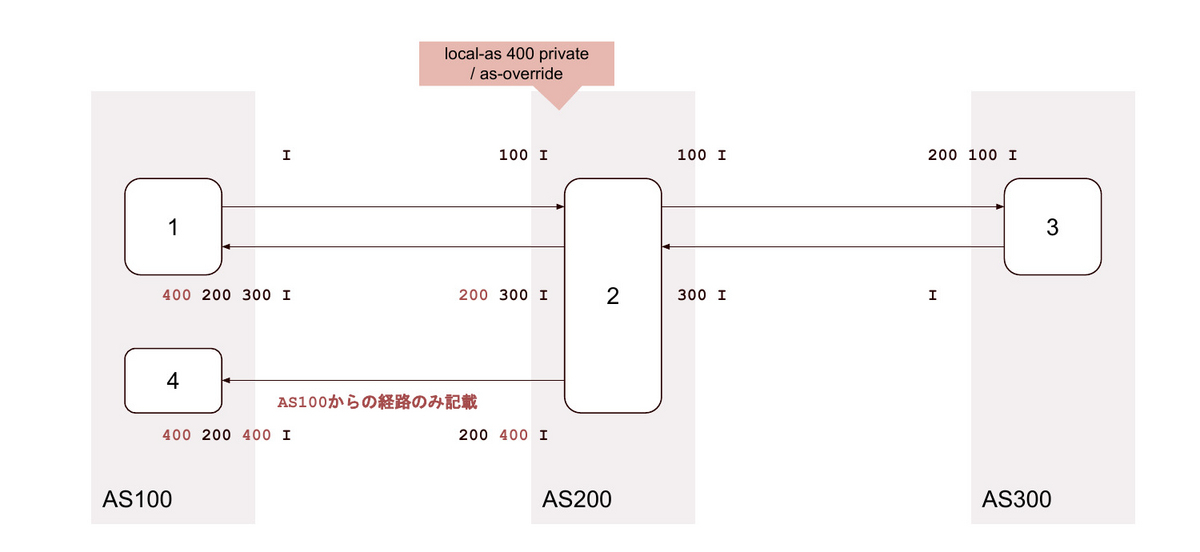
19. local-as <無関係なAS> alias / as-override
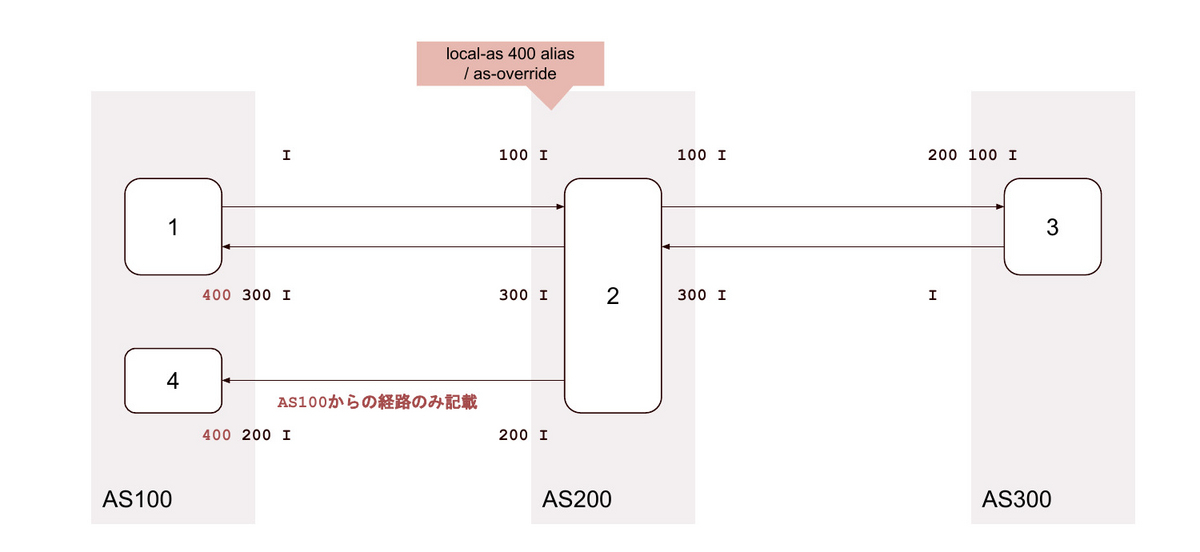
20. local-as <無関係なAS> no-prepend-global-as / as-override
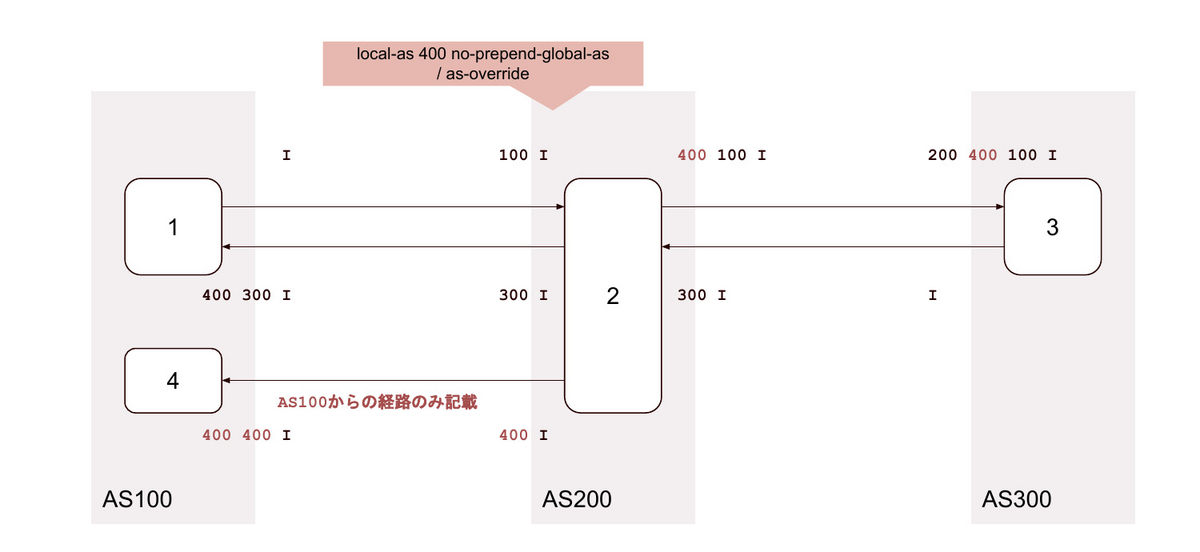
21. local-as <無関係なAS> private no-prepend-global-as / as-override
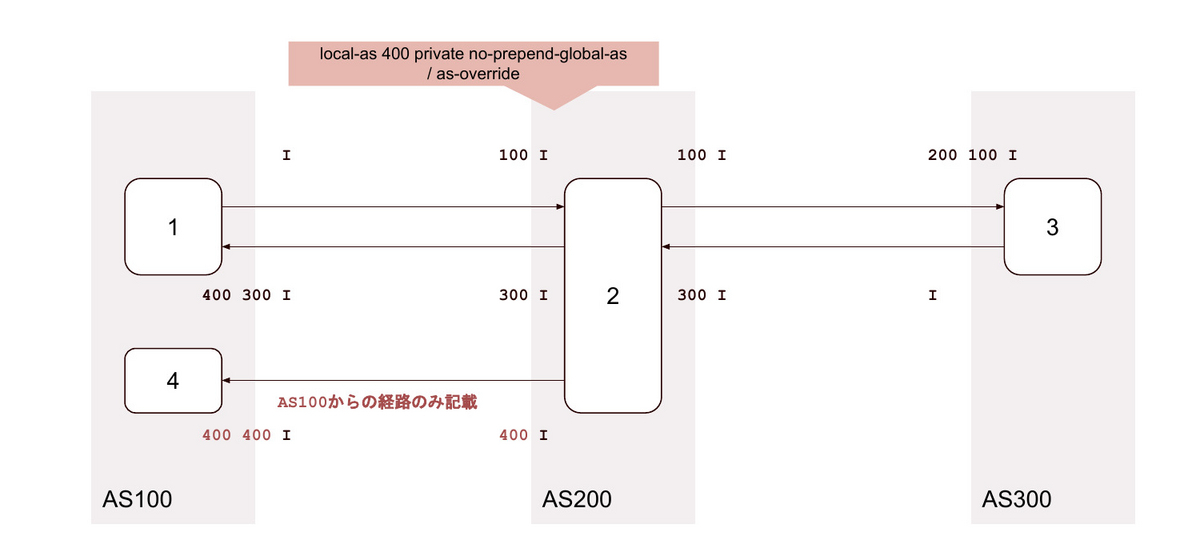
22. local-as <背後のAS> / as-override
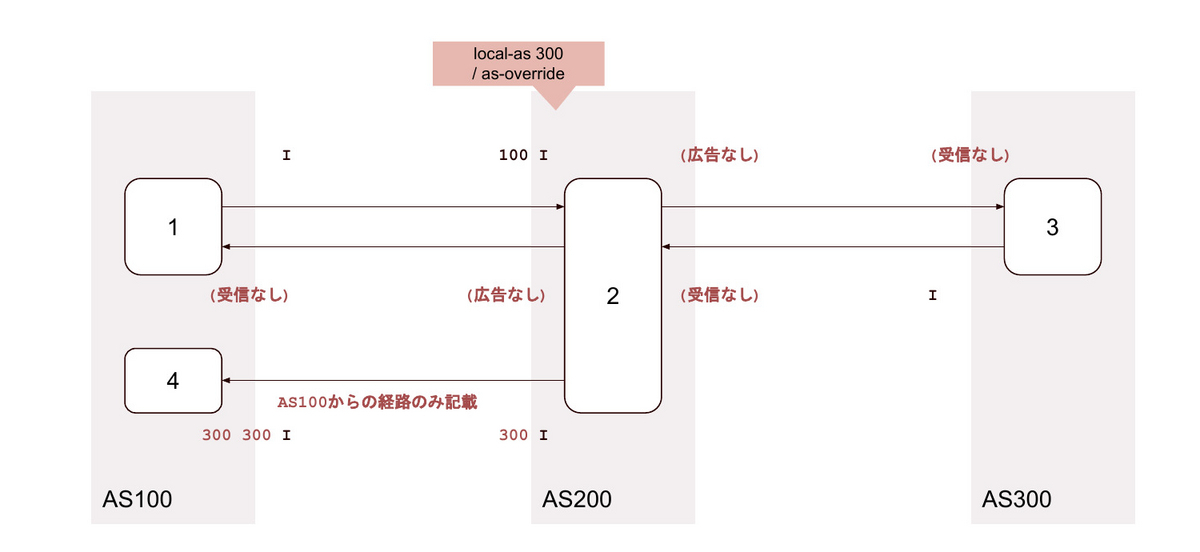
23. local-as <背後のAS> private / as-override
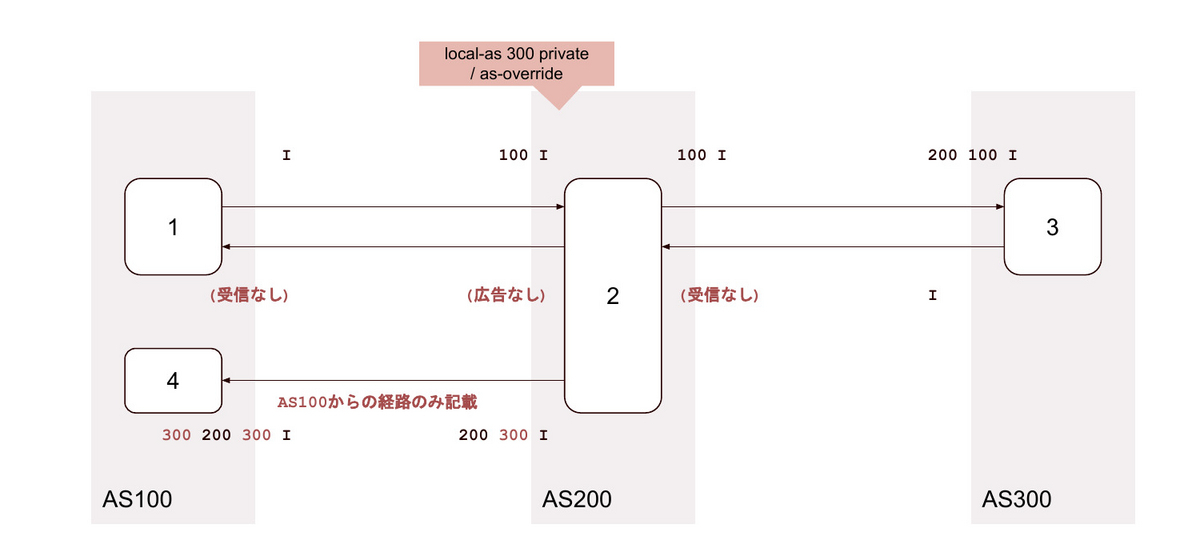
24. local-as <背後のAS> alias / as-override
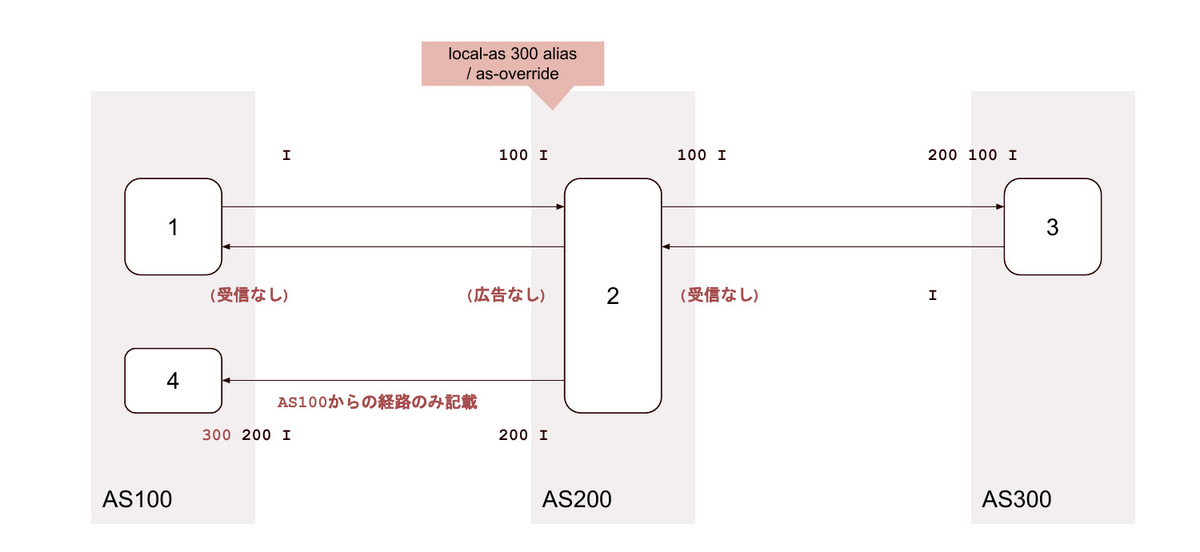
25. local-as <背後のAS> no-prepend-global-as / as-override
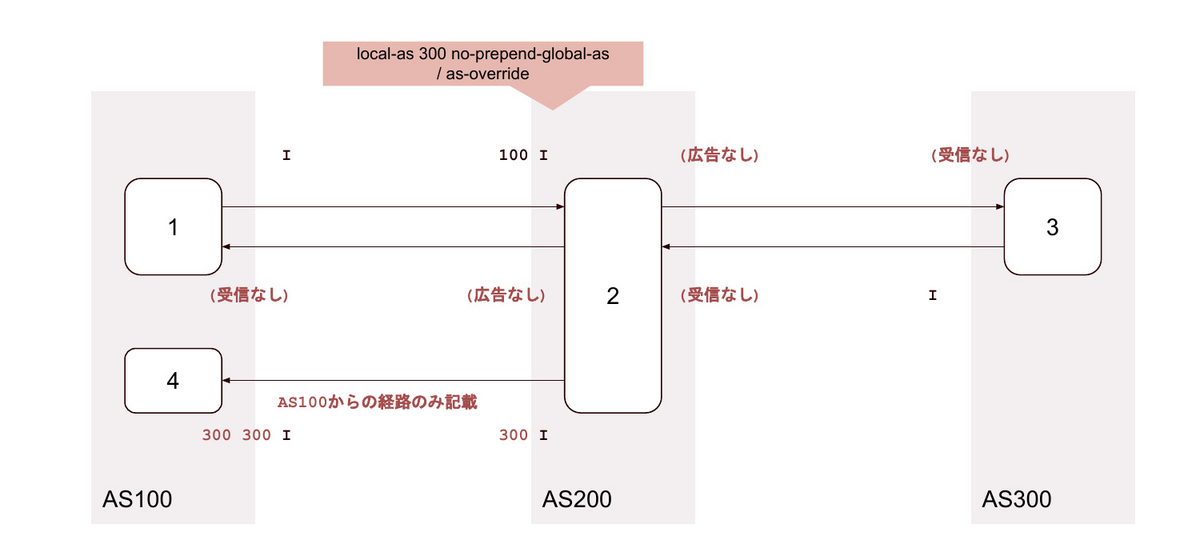
26. local-as <背後のAS> private no-prepend-global-as / as-override
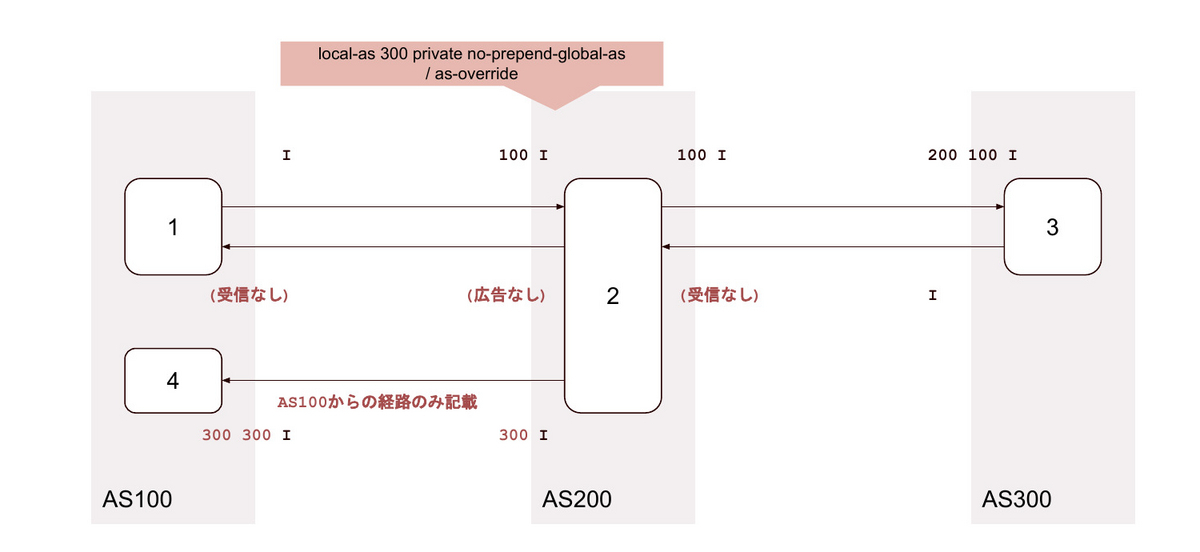
27. local-as <背後のAS> loop 2 / as-override
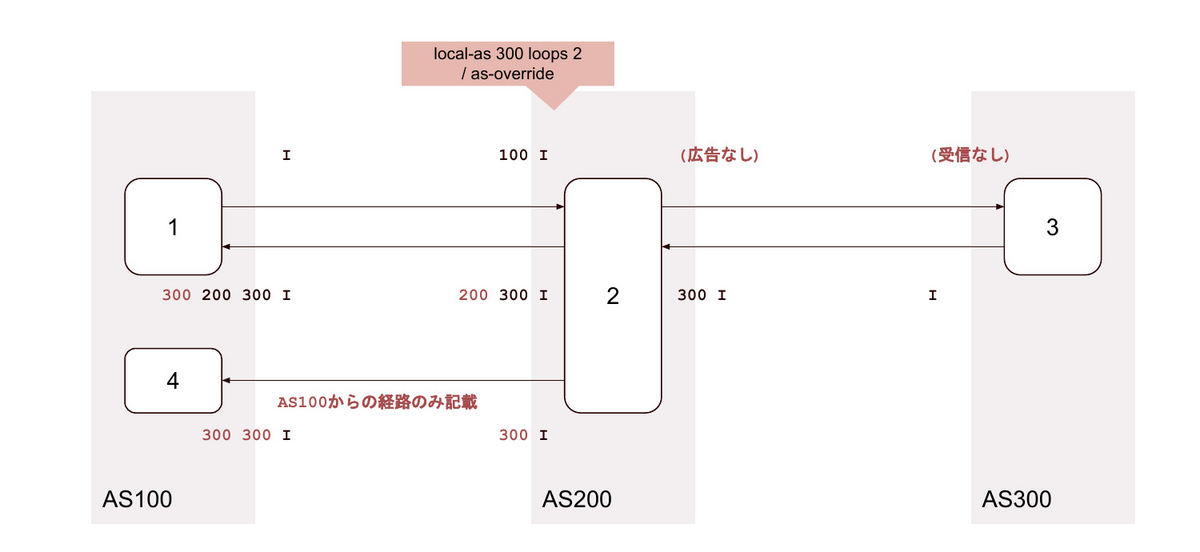
28. local-as <背後のAS> loop 2 private / as-override
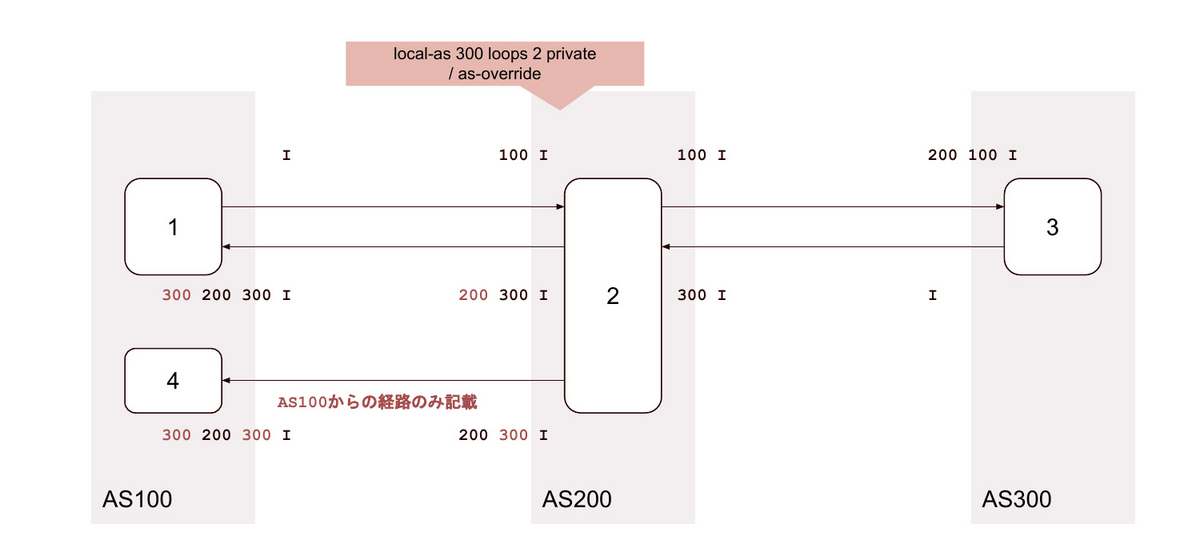
29. local-as <背後のAS> loop 2 alias / as-override
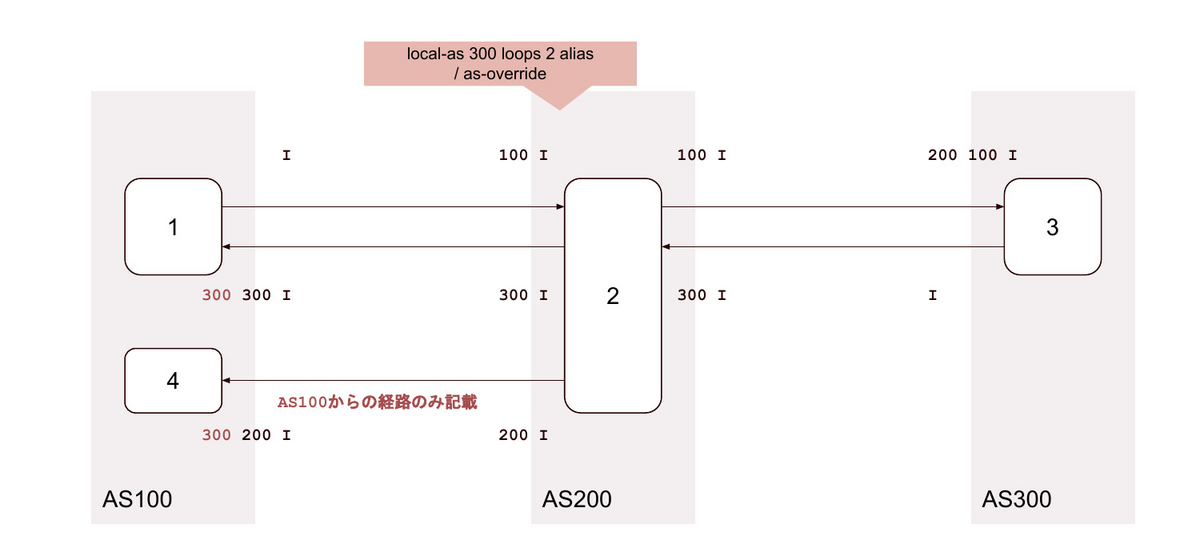
30. local-as <背後のAS> loop 2 no-prepend-global-as / as-override

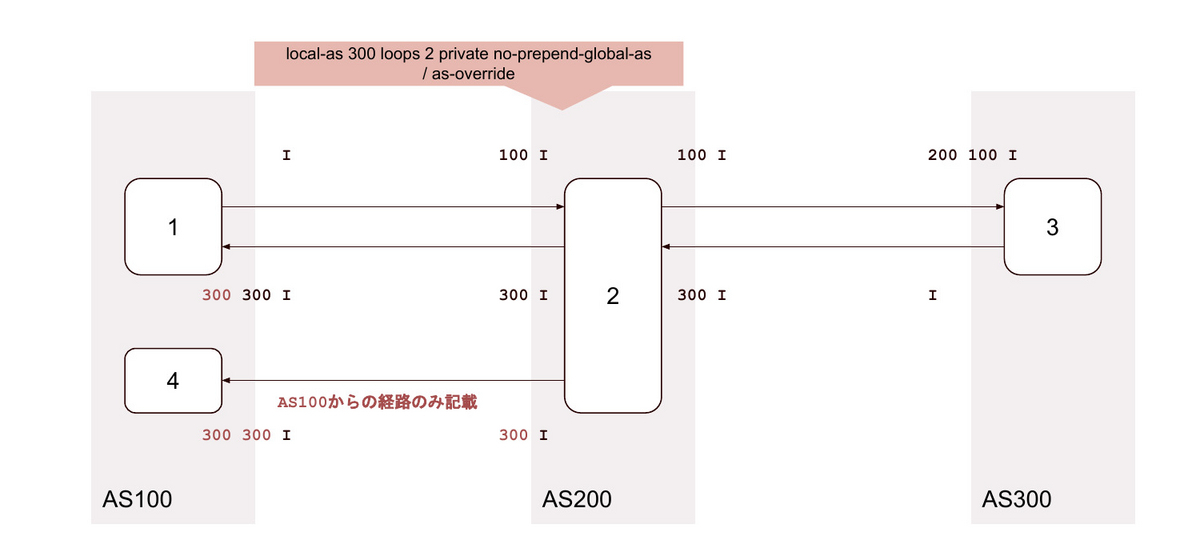
31. local-as <背後のAS> loop 2 private no-prepend-global-as / as-override
オプション変更時、BGPセッションがどうなるか
- ⭕️ 落ちません
- ❌ 落ちます。どちらが落とすかは省略します
まとめ
Juniperでlocal-as と as-override を併用したとき、どのようなルーティングになるか試しました。
理屈が通っているようには見えないのですが…納得できたら追記します。
yaml validator としてのCUE
設定やデータをファイルにするとき、どんなフォーマットを使いますか?
ファイルにアクセスする言語が決まっているなら その言語で直に書く場面も多いと思います。不特定の言語から扱うなら .json とか .yaml ですか?
可読性の観点で 個人的には .yaml が好みですが、いくつか困っていることがありました。
その困りごとを CUE で解決できそうだったので 紹介したいと思います。
yaml を扱う上での困りごと
一言でいえば「スキーマ定義の標準、もしくは強力なツールセットがない」です。スキーマは、
- 人間が読めること
- 実行できること (スキーマをもとに validate できること)
が望ましいと考えています。
yaml を書きたいが 書くべきデータ構造がわからない場合、おそらくドキュメントを参照しますよね。 逆に、データ構造を決める側はドキュメントをメンテしないといけません。とてもめんどくさく、普通は更新を忘れます。 人間が読めるスキーマファイルがあって、それ自体を使って簡単に validate できる = 更新忘れに気づける ことが理想です。
これは json であれば満たせます。 一方で「人間が何度も読むデータは可読性重要」という思いがあり、迷ったあげく yaml を選択し、がんばってドキュメントを書くということをやっていました。
CUE を使うとどうなる?
CUE が何か、何ができるかの詳細についてはここでは触れません。公式の "Use Cases" が参考になると思います。日本語であれば 👇 がわかりやすいです。
Apache License 2.0、"This is not an officially supported Google product" です。これは yaml スキーマの標準ではありませんが、少し使ってみたところ十分強力だと感じました。 4年間 active に開発が続いています。
では、具体的なデータとスキーマを使って CUE がどんな感じか見てみましょう。
validate 対象となるデータ
ネットワーク機器の設定をイメージしています。スキーマは適当に考えました。
# ./config.yaml os: junos platform: qfx10002 interfaces: - name: et-0/0/1 type: transit # 物理にだけ type / speed を書く speed: 100g description: very fast transit # optional - name: et-0/0/1.0 ipv4: # unit にだけ ip を書く address: 10.0.0.2/30 - name: et-0/0/3 type: globe wide ix speed: 40g - name: et-0/0/3.0 ipv4: address: 10.0.1.1/24
CUE によるスキーマ
# ./schemas/config.cue package config os: "junos" | "ios" platform: string
# ./schemas/interface/interface.cue
package config
import "net"
#interface: {
name: =~"^..-\\d+/\\d+/\\d+(\\.\\d+)?$"
// physical interface like et-0/0/0
if name !~ "\\." {
type: "transit" | "peer"
speed: "40g" | "100g"
description?: string
}
// sub-interface like et-0/0/0.0
if name =~ "\\." {
ipv4: {
address: net.IPCIDR & !~":"
}
}
}
interfaces: [...#interface]
interfaces: 配下はごちゃごちゃしがちなため、ファイルを分けておきます。
パッと見て、どういう文脈でどういうキーが使えるか・どういう値を取りえるか なんとなくイメージできると思います。
しかも JSON Schema よりだいぶ読みやすい。
$ cue vet schemas/config.cue schemas/interface/interface.cue config.yaml
のようにして .yaml を直接 validate できます。
通常は拡張子からファイルタイプを推測しますが、指定することも可能です。
$ cue vet schemas/config.cue schemas/interface/interface.cue yaml: config
サポートされているファイルタイプは cue filestypes で一覧できます。
追加の制約を適用する
CUE の面白いところは、既にあるスキーマを変更することなく外から制約を追加できる点です。 たとえば「peer は 100GE であるはず」という制約を追加します。
# ./schemas/fast-peer.cue
package config
#interface: {
type: string
speed: string
if type == "peer" {
speed: "100g"
}
}
.cue ファイルを追加指定すればOK。
$ cue vet schemas/config.cue schemas/interface/interface.cue schemas/fast-transit.cue config.yaml
わかりにくくて完全にやりすぎですが、QFX Port Mapping をCUEで表現した例。
# ./schemas/interface/qfx.cue
package config
import "list"
if platform == "qfx10002" {
#interface: {
name: string
speed?: string
if name !~ "\\." {
{
_invalid_100g: [
for i in list.Range(0, 36, 6) if name =~ "-0/0/\(i)$" && speed == "100g" {true},
for i in list.Range(0, 36, 6) if name =~ "-0/0/\(i+2)$" && speed == "100g" {true},
for i in list.Range(0, 36, 6) if name =~ "-0/0/\(i+3)$" && speed == "100g" {true},
for i in list.Range(0, 36, 6) if name =~ "-0/0/\(i+4)$" && speed == "100g" {true},
false,
][0]
} & {_invalid_100g: false}
}
}
}
_checks: {
invalid_port_mapping: {
list.Contains([ for i in list.Range(0, 36, 6) {
if [ for intf in interfaces if intf.name =~ "-0/0/\(i+1)$" {true}, false][0] {
[
for intf in interfaces if intf.name =~ "-0/0/(\(i)|\(i+2))$" {true},
false,
][0]
}
if [ for intf in interfaces if intf.name =~ "-0/0/\(i+5)$" {true}, false][0] {
[
for intf in interfaces if intf.name =~ "-0/0/(\(i+3)|\(i+4))$" {true},
false,
][0]
}
}], true)
}
} & {invalid_port_mapping: false}
ビジネスロジックよりの制約だけではなく、ネットワーキングではハードウェア制約が多いため「 platform == "qfx10002" ならばこう」のような表現ができると便利です。
エントリーポイントを量産せず、制約を付け外しできるのは良い
ここまで
- データ構造の定義
- ビジネス上の制約
- ハードウェア上の制約
それぞれ例を書きました。これを組み合わせて適用する場合、たとえば JSON Schema では 1~3 を呼び出すエントリーポイントを別に書く必要があります。 現実の制約はもっと多岐にわたり、組み合わせ数は爆発します。
一方 CUE ではエントリーポイント自体が不要です。 *1 入口に限らず どのような階層でも不要です。ここが気に入りました。
package として制約(スキーマ) に名前をつけ、ディレクトリ構成を絡めて指定できるパッケージシステムがあり、カンタンに制約を付け外しできるのは強力なアプローチです。
Standard Packages
CUE 自体に Standard Package がついており、簡単な演算ができます。
残念なのは iteration 関数が少ないこと。先ほどの QFX Port Mapping の例のように list を扱おうとするといきなり複雑になります。 半順序関係をユーザーが定義できればスッキリ書けるかもしれませんが、可読性とのトレードオフがあります。
「計算が必要なものはスキーマに含めない」くらいがバランスとしてちょうどいいのかもしれません。
スキーマとデータとlattice(束)
制約を後付けできるしくみは、特徴的なスキーマとデータの扱い方によるものです。
CUE ではスキーマもデータも lattice(束) として扱います。同じ key が現れるたびに交わり(∧、積)を取ることで評価します。
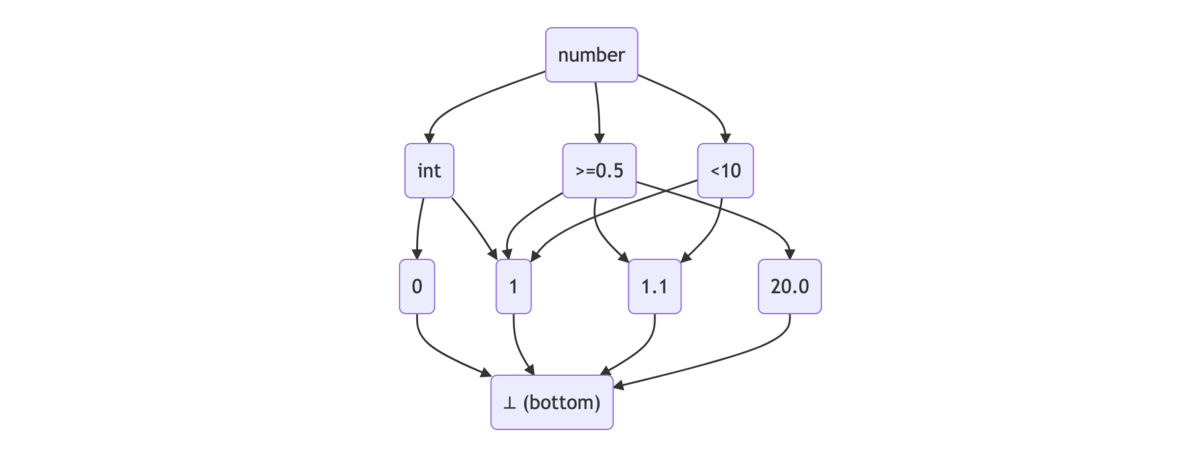
# ./valid.cue // スキーマ a: int // a: int 全体の集合 b: int // データ a: 1 // a: int 全体の集合 ∧ 1
$ cue eval valid.cue a: 1 b: int
交わりが最小元(⊥)であることは validation 失敗を意味します。
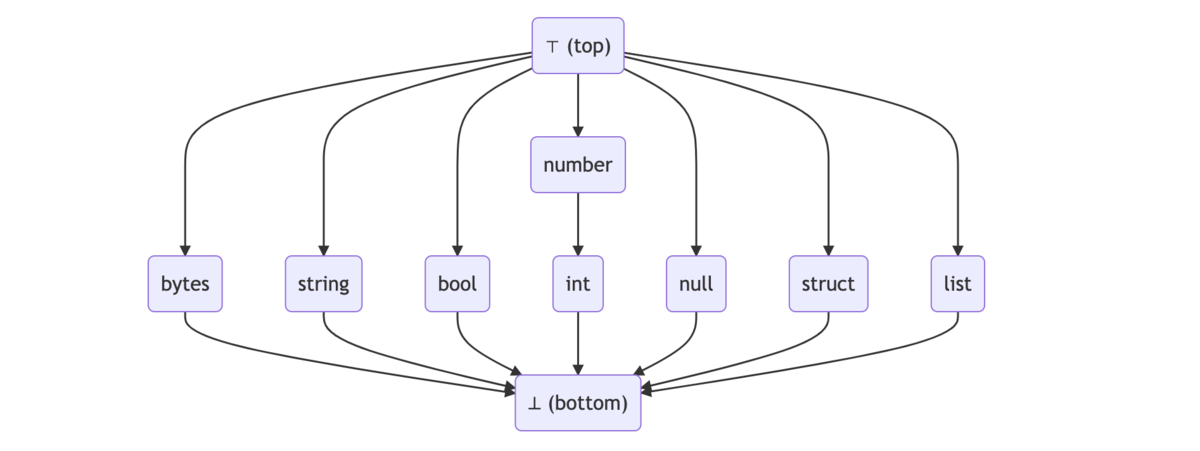
# ./invalid.cue a: string a: 1
$ cue eval invalid.cue
a: conflicting values string and 1 (mismatched types string and int):
./a.cue:1:4
./a.cue:2:4
lattice の定義から 結び(∨、和)も存在し、集合の演算が可能です。発想がすごいですね。
スキーマとデータをlatticeとみなしてよいかについては、このブログが参考になります。
CUE の学び方
ドキュメントが少ない中、Cuetorials がわかりやすいです。
👇 をざっと流し読みして
1 . Cuetorials "Overview", "First Steps"
2 . 公式 "Language Specification"
コンセプトに戻り 👇
3 . 公式 "About"
4 . 公式 "The Logic of CUE"
package, attributes, open / closed の概念で詰まったら 👇
5 . 公式 "Modules, Packages, and Instances"
6 . Cuetorials "Attributes"
7 . Cuetorials "Open and Closedness"
最後に
8 . Curtorials "Useful Patterns"
の順がオススメ。
まとめ
CUE の良い点について改めて。
- 人間にとって読みやすく、
.yamlデータを直接 validate 可能 - 演算ができる
- 制約をカンタンに付け外しできる。JSON Schema のように エントリーポイントを量産する必要がない
参考
*1:「cue コマンドがたまたまそういう仕様」と区別しにくいのですが「CUE のコンセプトレベルでこれを狙っています」との記載があり、おそらく CUE 自体の仕様です。
PeeringDBの過去データを読む
インターネットルーティングに関わっていると、まれに PeeringDB の過去データを集計したくなります。
https://www.peeringdb.com から現在の情報は取れますが、「過去に遡りたい」「特定の国・地域・事業者に注目して時間推移を見たい」といった要望を満たせません。そこで CAIDAが公開してくれている PeeringDB の daily snapshot を読み、集計し、下のようなグラフを描いてみます。東京・大阪の事業者数の推移です。
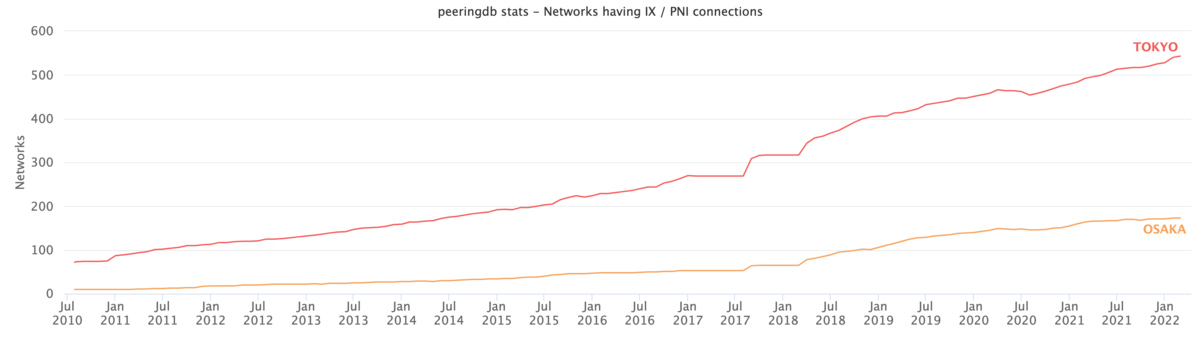
CAIDA PeeringDB Dataset
CAIDA Acceptable Use Agreement に同意し コンタクト情報と利用用途をsubmitすれば、PeeringDB アーカイブをダウンロードできます。
PeeringDBは 2016-03-15 にv2になり、スキーマが新しくなりました。バージョンごとに利用可能なアーカイブ種別も異なります。
| 時期 | PeeringDB v1 | PeeringDB v2 |
|---|---|---|
| 2010-07-29 ~ 2015-12-31 | .sql, .sqlite |
|
| 2016-01-01 ~ 2016-03-14 | .sql, .sqlite |
.sql, .sqlite |
| 2016-05-27 ~ 2018-03-10 | .sqlite |
|
| 2018-03-11 ~ | .json |
- v2 リリース直後はアーカイブがありません
- 2016-03-14 以前のv2データはβリリース版のものです
アーカイブをどう読むか
SQLで好きに集計できそうなのですが、最近の v2 データはAPIダンプになっていてDBに書き戻せず、 JOIN するのが厳しいです。また、古い v1 データは DBダンプがありますが 対応するappが公開されていません。
- 試行錯誤しつつ検索条件・集計方法・出力を変えたいので、言語は何でもいいがプログラム処理したい
- ORM があると便利
なので、ORMが使えるフレームワークを使い 最低限アーカイブを読めるappをでっちあげ、集計プログラムを書くのがよさそうです。
アーカイブを読むためのapp
DBスキーマからよしなにモデルを生成してくれる ( DBにある情報はプログラム側に書かなくてもよい ) フレームワークのひとつにRailsがあります。PeeringDB v2は Django 製ですが、v1 流用を考えた場合アーカイブを読むだけならRailsのほうがたぶんラクです。
v2 期間だけでよければ、 公式Django モデル 向けloaderを書くのが早いと思います。
Railsで読む場合、たぶんこんな感じになります。
v2 データを読む例を記載しますが、もし興味があれば使い方は README を見てください。
$ git switch peeringdb-v2 $ bundle install $ sqlite3 db/development.sqlite3 < db/598a658.sql # Download any json file of v2 as archive.json for example, then $ rails runner script/load.rb archive.json
v2 データをロードするとDBスキーマはこうなります。公式Django PeeringDB モデルと同じはずです。
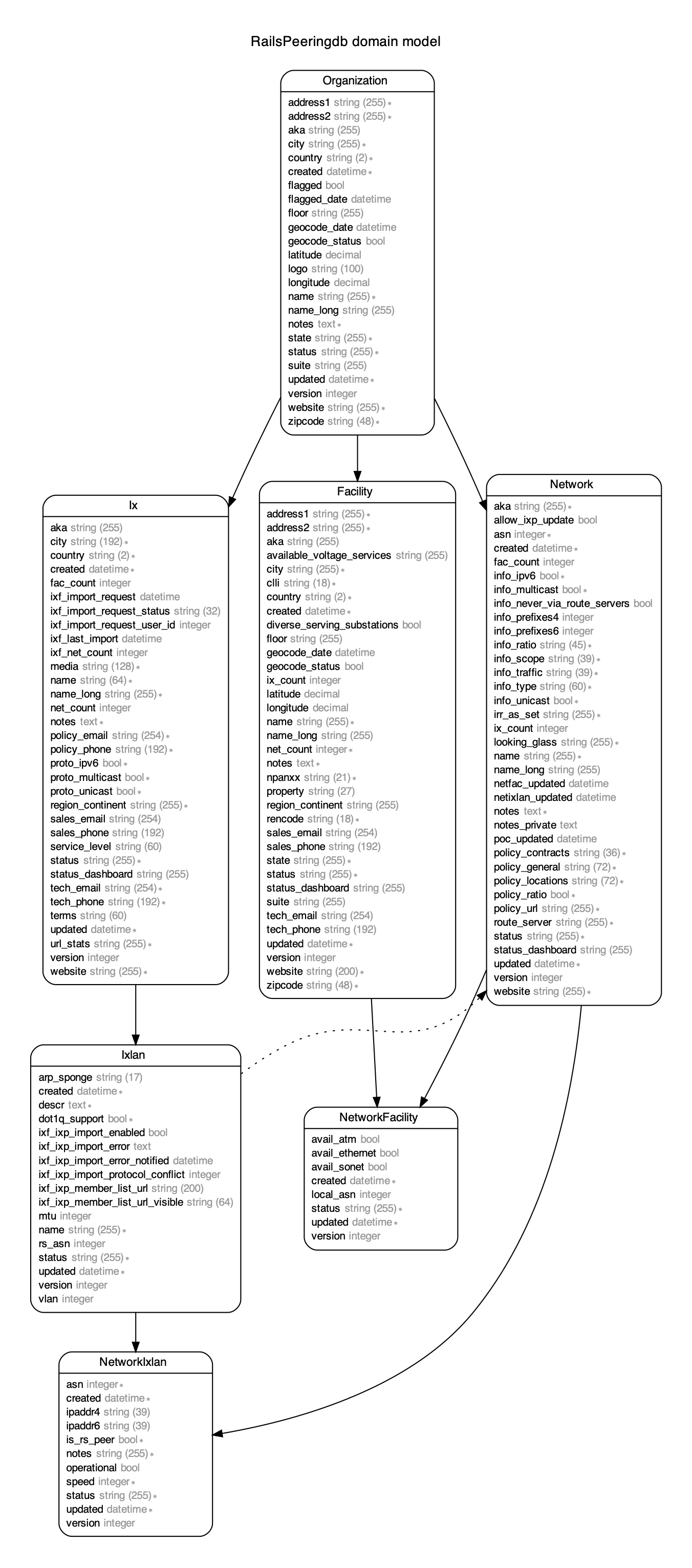
データをロードできたら、集計プログラムを書きます。たとえば「日本の都市ごとに、POPがある or IX接続がある事業者を数える」場合はこんな感じになると思います。
require 'json' ixs = Hash[Ixlan.joins(:ix).includes(:networks).where(ix: { country: 'JP' }).group_by { |i| i.ix.city }.map { |c, ixlans| [c, ixlans.map(&:networks).flatten.uniq] }] privates = Hash[Facility.includes(:networks).where(country: 'JP').group_by(&:city).map { |c, facilities| [c, facilities.map(&:networks).flatten.uniq] }] cities = (ixs.keys + privates.keys).uniq stats = Hash[cities.map { |c| [c, { ix: ixs[c]&.count || 0, private: privates[c]&.count || 0, total: ((ixs[c] || []) + (privates[c] || [])).uniq.count }] }] def upcase_keys(hash) normalized = {} hash.each do |k1, v| if normalized.has_key?(k1.upcase) v.keys.each do |k2| normalized[k1.upcase][k2] += v[k2] end else normalized[k1.upcase] = v.dup end end normalized end print JSON.dump(upcase_keys(stats))
v1 データを読みたい場合は、GitHubレポジトリに スキーマ と サンプル があります。
グラフを描画する
ここでは省略しますが、PeeringDBアーカイブから任意の時点・検索条件・集計方法でjson出力を得られるので、好きな方法でグラフ化してください。
参考
packer で vEOS Vagrant Box を作る
Arista vEOS 4.19 までは Software Download ページから .box をダウンロードできましたが、
現時点で 4.20 ~ 4.27 にはありません。
そこで jerearista/vagrant-veos を使って .vmdk から .box を作ります。
環境
| Software | version |
|---|---|
| VirtualBox | 6.1.26 |
| packer | 1.7.6 |
作り方
vEOS-lab-4.27.0F をベースに作る例です。
1 . Software Download ページからファイルをダウンロードします。
Aboot-veos-8.0.0.isovEOS-lab-4.27.0F.vmdk
後述しますが Aboot-veos-serial-8.0.0.iso ではうまく動きません。
.vmdk は 64bit 版でも OK です。
2 . vagrant-veos を実行します。
git clone https://github.com/codeout/vagrant-veos.git cd vagrant-veos/packer cp <path to Aboot-veos-8.0.0.iso> source/Aboot-vEOS.iso cp <path to vEOS-lab-4.27.0F.vmdk> packer/source/vEOS.vmdk packer build -var "version=4.27.0F" vEOS-4-i386.json
オリジナルの https://github.com/jerearista/vagrant-veos は 最新の VirtualBox + packer で動かないため、パッチが必要でした。
https://github.com/codeout/vagrant-veos がパッチ済みのものです。
( オリジナルがメンテされてなさそうで…PR してもレビューしてもらえない気がする😭 )
パッチ中身
vagrant up後にManagement1にIP アドレスが振られませんでした。明示的に DHCP enable にします/mnt/flash配下のファイルがadminオーナーの場合 EOS がうまく読んでくれません。rootにします- VirtualBox 6.1.20 から、
VBoxManage export --isoオプションは動きません。*1--options isoに変えます - 最新の VirtualBox + packer では COM1 経由の boot command 入力がうまくいきません =
Aboot-veos-serial-8.0.0.isoでは動作しません。 ふつうの key input を使います - VM 作成後 export する前に shutdown しますが ACPI を使っていないため、直前に file provisioner で送ったファイルが保存されない場合があります。 ACPI enable にします
*1:Document Bug がある様子
日本はアジアのハブになれたのか?
通信キャリアや IX に勤務していたころ、よく「日本をアジアのハブにしよう」と言っていました。
データを整理する機会があったので「実際のところどうなの?」をまとめてみます。
話の背景は文末に回しました。もしご興味あればどうぞ。
パブリックデータから、国際ハブとしての大きさを探る
通信のために事業者が相互接続するとき、検討段階ではどんな事業者がどこにいるかを知っておく必要があります。 接続時・接続後も、たとえば経路数やPOPなど、継続的に情報インプットが必要です。 各種情報がまとまったデータベースとして PeeringDB が有名ですが、そこに登録されている
- 事業者(AS) 数
- 事業者(AS) が拠点を持つ国
- 事業者(AS) が接続するIX がある国
から、「アジア各国で、どれくらいの事業者と接続できそうか」を推測してみます。
( ある事業者がその国に拠点を持っている or その国のIX に接続していれば、「接続できそう」とします )
- CAIDA が PeeringDB の daily snapshot を公開してくれており、これを時系列プロット
- 事業者(AS) の所属国は Geoff Huston のリスト を参考にする
アジア各国の事業者数 (国際 + 国内)

見づらいですが、現時点で次のようになっています。 ここには各国内に閉じる事業者も含まれている点に注意ですが、以降、この5ヵ国に注目します。
インド・インドネシアの伸びがすごいですね。
| # | 国 | 事業者数 |
|---|---|---|
| 1 | インド | 647 |
| 2 | 日本 | 437 |
| 3 | シンガポール | 427 |
| 4 | インドネシア | 418 |
| 5 | 香港 | 383 |
アジア5ヵ国の事業者数 (国際)
ここが本題です。シンガポール・香港は古くからアジアのハブとして機能していました。「これに追いつこう」というのが日本のスタンスでしたが、このデータでは残念ながら、差は縮まってないようですね。
一方、インドへの国際事業者への参入が目立ちます。

ちなみに、インターネットの中心とされる US を含めると これくらいのスケールになります。

アジア5ヵ国の事業者数 (国内)
参考までに、国内事業者だけをプロットしてみます。
インド・インドネシアがすごく伸びていますが、増えたのは国内事業者であることがよく分かります。

「日本をアジアのハブに」の話
企業の枠を超えた、業界全体のスローガンのようなものです。一般に言われているかは分かりませんが、 たとえば US・EU の通信事業者がアジアと接続したいときに「日本につなごう」「日本に拠点を持とう」と 思ってもらえるようなエコシステムを作ろう、という意味です。
逆もしかりで、アジアの通信事業者がUS・EU と接続したいときに 「日本には事業者が集まっているので、足を伸ばす・拠点を持つ価値がある」と思ってもらいたい。
インターネットな BGP を運用している事業者が言う「接続したい」は、「物理的に直接つないでトラフィック交換したい」です。 Gbps ~ Tbps のトラフィックを持つ事業者にとって、間に別の事業者が挟まっているのは割に合いません。 特定の事業者と大量トラフィックを交換したい場合、直接接続することで
- トータル、コストが下がる
- ビジネス面での交渉・技術的な調整・トラフィック制御がしやすくなる
- 遅延の解消
のようなメリットが見込めます。
そう考える国際事業者に対して 日本がアジアのハブとして機能することは、国内事業者にとってもメリットがあります。 「少しの投資で国際事業者と接続できる」などです。日本であれば簡単にクラウド事業者と接続できますが、もし国内で接続できなかったらどうでしょう? 影響は通信業界だけではなく、自国に国際ハブがあることは日本全体にとっても経済面・ 国際競争の面で有利にはたらきます。
このような背景があって通信事業者のひとたちは「日本をアジアのハブにしよう」と言っていました。 検索してみると、かれこれ20年 にもなるようです。
立地的に有利とされていたはずが…
この文脈でよく言われるのが海底ケーブルの陸揚げです。「USから見てアジアへの経路上にあるので、中継点としては最適」とされていました。
 https://www.submarinecablemap.com/
https://www.submarinecablemap.com/
しかし長年国際ハブになりきれない点について
- 言語バリアーがあって、消費者は英語コンテンツをあまり見ない
- シンガポール・香港に比べ、通信政策・法制度・税制度が行き届いていない
- 国内キャリアの競争戦略
いろんな意見を聞きますが、個人的にはよく分かっていません。
別のグラフを出しますが、これは事業者の IX 接続帯域合計です。日本は、IX 先進国であるドイツ・オランダ・英国に近いレベルで伸びています。

次にヨーロッパ各国 + 日本の国際事業者数推移です。

通信インフラが成熟しているドイツ・オランダ・英国・日本、各国とも通信政策に力を入れている中、国際ハブの観点ではドイツだけが大きく伸びています。US から見て言語バリアーがなく大西洋ケーブルを多く終端している英国より、ドイツが伸びている点は面白いですね。
トラフィックは重力のように、大きなところに事業者が集まる傾向がありましたが、ドイツやシンガポールが国際ハブとして活発である点からすると、近年は
といういうことかもしれません。
参考
inet-henge for large scale network diagrams
inet-henge is a d3.js based network diagram generator that calculates node positions automatically. The input is a simple json like below, it requires no position information such as x-y coordinates.
{ "nodes": [ { "name": "A" }, { "name": "B" } ], "links": [ { "source": "A", "target": "B" } ] }
The auto-layout works good and fast enough for small networks but it gets more complex and painfully slow when you have many nodes and links in a diagram. It'll take a couple of minutes to calculate the position of 300+ nodes and 1400 links for instance.
As a performance improvement, I've introduced a new option to tweak the auto-layout algorithm, especially for large scale network diagrams. When I tried my test data comprised of 800 nodes and 950 links, it only took <20 secs to determine node positions. I know it's still slow but acceptable hopefully, as it should be a one-shot calculation - inet-henge can cache the result for further rendering.
So why was it so slow?
Besides inet-henge calculates the node positions repeatedly in each time slice just like force layout of d3.js, extra constraints are added to iteration:
- Group nodes with bounding boxes
- Prevent nodes and groups from overlapping with each other
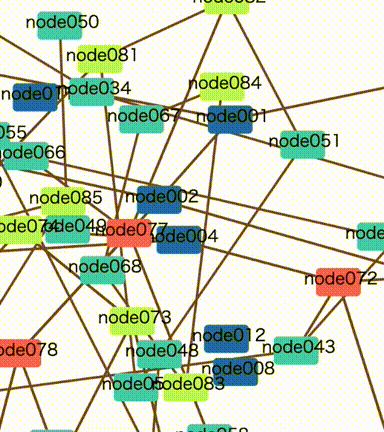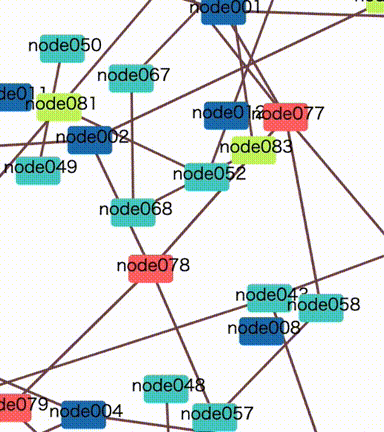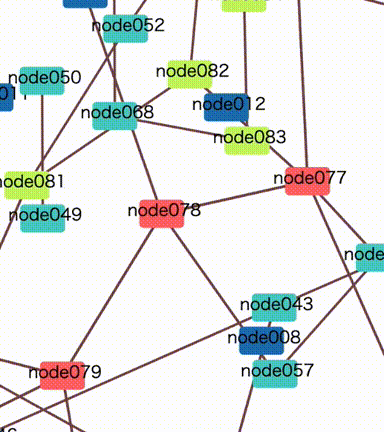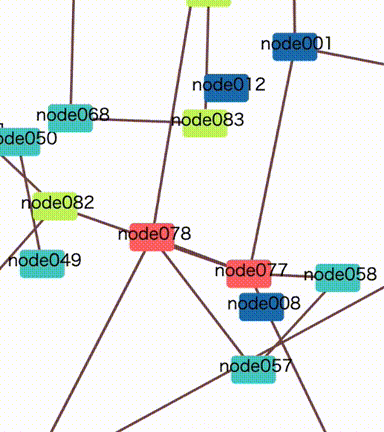
If you have huge groups having many nodes, it sometimes wastes ticks to pass by each other. In an example diagram below, it looks hard for a blue group to pass through a red one. It might get stuck for many ticks or never pass in the worst case.
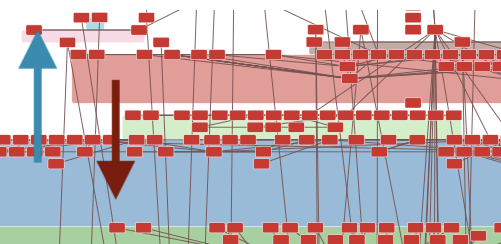
The same thing will happen even in a no group diagram. Every node collides with each other many times and it prevents position calculation from fast convergence.
The new option initialTicks
For such a large scale network diagram, you can specify the number of initial "unconstrained" ticks.
const diagram = new Diagram('#diagram', 'data.json', {initialTicks: 100, ticks: 100});
With this option, inet-henge calculates the layout in two iteration phases:
- Initial iteration with no constraints. ( default: 0 tick )
- Every group or node can transparently pass through each other in this phase.
- The main iteration with constraints that apply groups as bounding boxes, prevent nodes and groups from overlapping with each other, and so on. ( default: 1000 ticks )
Note: If you increase initialTicks, inet-henge calculates faster in exchange for network diagram precision so that you can decrease ticks which is the number of main iteration steps.
20 ~ 100 initialTicks and 70 ~ 100 ticks should be good start for 800 nodes with 950 links for example. It takes 20 seconds to render in my benchmark environment.
Draw your own diagram
The initialTicks option is very new and not tested enough due to a lack of actual network topology data. If you're interested in this project and drawing your network diagram, please reach out to me ( Twitter ) with your use case. Any feedback will be appreciated.
ネットワーク標準化ギプス
テキストやファイルで設定管理されるようなネットワークの、設定標準化・テンプレート化・Validation について書きます。 経験上、ISP・コンテンツプロバイダなどのネットワークでうまくいった手法ですが、よりよい方法があるかもしれません。ご指摘・コメント頂けるとうれしいです。
- 現在自動化できていないが、自動化を目指したい
- 移行過渡期は、もしくは移行後であっても運用上の都合で、手動投入は許容したい
- ネットワークが正しく設定されているか? を常にチェックしたい
このようなネットワーク運用を想定します。
やりたいこと
ネットワークデバイスはシステム側からもオペレーターからも変更されうる という環境で、
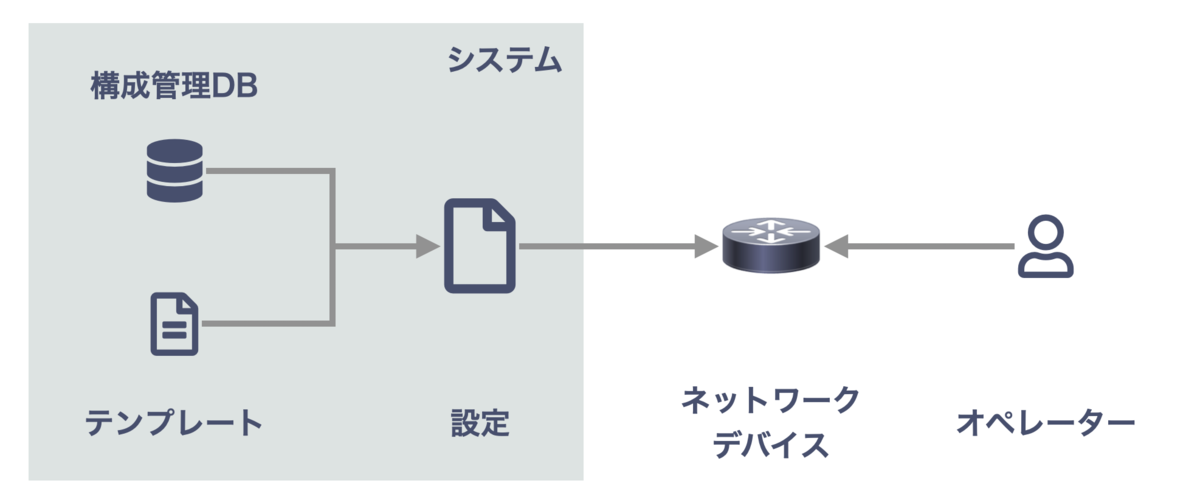
- ネットワークポリシー・設定を標準化し、テンプレートとして実装する
→ テンプレートが強制力としてはたらき、ポリシーが維持できる - 何かのトリガーで 構成管理DB + テンプレートから設定を生成し、自動 or 手動によりネットワークデバイスにロードする
→ オペレーターが手動投入した (= テンプレート化されていない) 設定との調整は よしなにやる - オペレーターが投入した設定がポリシーに即しているかチェックする
- ネットワーク全体として、意図どおり設定されているかチェックする
👆 がやりたいことの概要です。
自動化によって運用コストを下げるのは当然として、手動オペレーションを許容しつつも ネットワークポリシー(標準設定) を強制することが目的です。
1. 手動オペレーションを許容する
やりたいことについて、いくつか補足します。 この項目は、従来のネットワーク運用から漸進的にシステム導入するために必要です。
手動オペレーションで運用している or 部分的に自動化している という状態から、ネットワークが標準化されていて テンプレートがあり、すべてをシステム経由で行う運用に一足で移行するのは、運用的にはかなり大きなチャレンジで、できれば避けたいところです。
2. 個々の業務を自動化するのではなく、完全な設定をテンプレート出力 & ロードする
こうする必要があるのは、手動オペレーションを許容しつつも、テンプレートにネットワークポリシー強制力を期待するからです。
たとえば「よくやる業務はテンプレートで自動化されているが、まれな作業は手で設定する」ようなケースを想像してください。 この場合、手で入れた設定も含めてポリシーに準拠しているかを判定するのは大変です。
よくやる業務(下図グレー部分) はポリシー準拠ですが、手動設定時(下図ピンク部分) は何が設定されているか分かりません。手動設定の特定でさえ難易度が高いと思います。
- アクセスできるのは、各業務のテンプレート + 現在の設定(= 各業務の累積) のみ
- ポリシーは変化する
点にも注意してください。
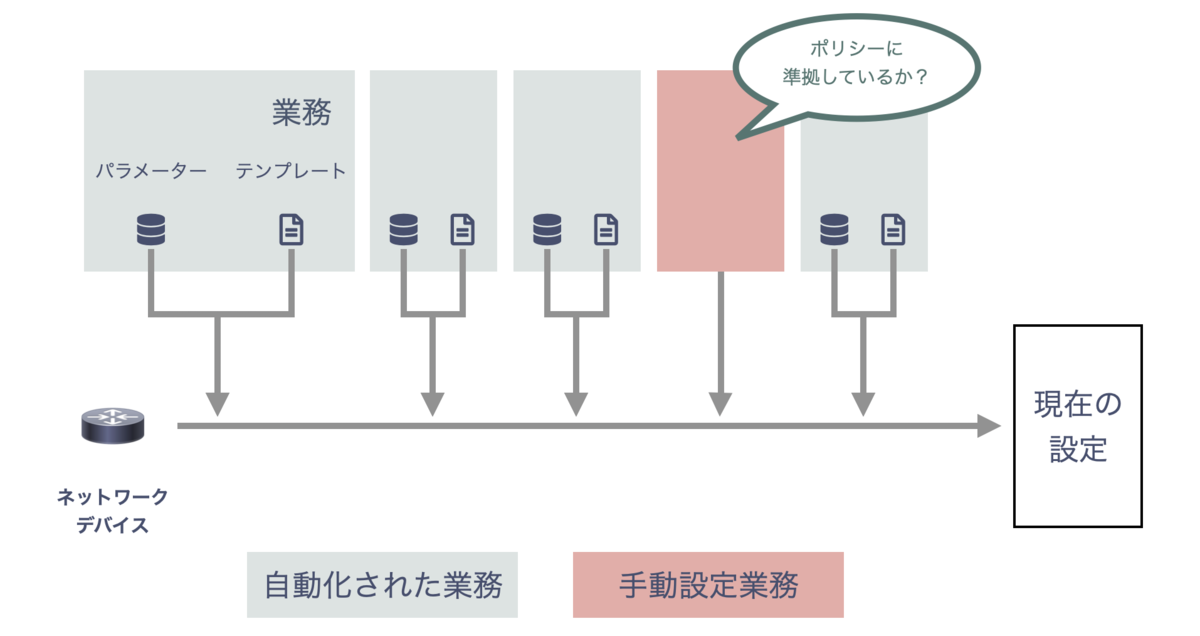
今回の目的で言えば、「業務を積み重ねた結果である現在の設定」をチェックするほうがシンプルで、「各業務を自動化する」の延長では複雑になりそうです。 完全な設定をテンプレート出力したいのは、こういった理由からです。
実装のためのアプローチ
さて、テンプレートシステムを実装するにあたり、どのようなアプローチを取るかについて。 ここでは具体的な実装例について触れませんが、進め方の指針をいくつか記載します。
1. 標準化とテンプレート開発を同時進行する
「自動化の前に標準化しましょう」というのは基本ですが、個人的な経験でいえば実装前に標準化しきれたことはありません💦
ここでいう標準化とは、ネットワークポリシー・あるべき設定の標準形を制定するだけではなく、実機上の設定を統一するところまでを指します。 手動オペレーションな歴史のあるネットワークであれば、名前の表記揺れ (例: policy-statement / route-map) にはじまり、微妙な設定の揺れがおそらく多々残っていると思います。
これらの標準化に取り組む間もどんどん揺れは混入されますので、もぐらたたきになりがちです。 具体的にどう進めるかは後述しますが、標準化と実装は 同時進行すると良いと思っています。
2. ポリシー外の設定を許容する
別の重要なポイントとして、ビジネスを止めたくありません。 ネットワークポリシーを標準化し、実装し、できればキレイな状態で維持したいのですが、どんどん変わるビジネス要件に対応する必要があります。 「ユーザーの新たな要望に応えたい」だったり、「バグ対応で設定や運用を変えたい」だったり、要件は様々です。
そのたびに「ポリシーとして標準化して、ツール化しないとネットワークに入れられません」ではスピード感を損ないます。 これまでの「ネットワークポリシーを強制したい」と矛盾するのですが、「この設定はポリシー違反だけど例外としてオッケー」というステージを作るということです。
- 一時的な設定
- ビジネスとしてGO 判定されたが、ネットワークポリシー・標準とするか判断されていない設定
向けのステージですね。「この設定ブロックがそうですよ」と明記しつつ、一時的に許容します。
実装のヒント
多くのネットワークデバイスの設定は宣言的であり、それ自体設定ではないが設定を削除するコマンド ( no, delete など ) があることを利用し、
- 標準化済みの設定を出力 (構成管理DB + テンプレートから)
- その後に標準化されていない設定を出力 (自由記述)
とするだけで、結構うまくいきます。
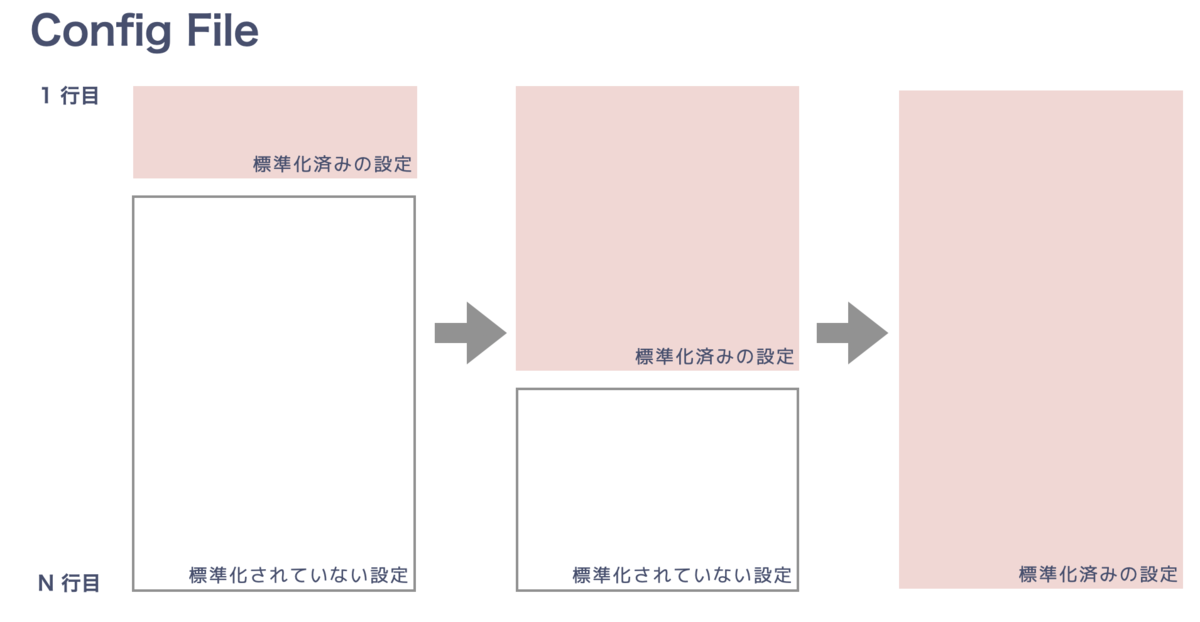
標準化済みの設定 (ピンクの部分) をテンプレートが生成し、別管理してある標準化されていない自由記述設定 (白の部分) と結合するだけですね。結合してうまくいくように、白の部分は工夫して書く必要があります。
個人的には 自由記述枠のことを昔「hack」と呼んでいましたが、最近は「patch」と呼んでいます。
標準化・実装が間に合わない部分をパッチすることで 1. 標準化とテンプレート開発を同時進行する ことができ、2. ポリシー外の設定を管理する ことができます。当初はパッチが大半ですが、テンプレート実装と実機設定の標準化を進めながら、ピンク部分を100% にすることを目指します。
実機設定とのdiff
パッチのしくみで、テンプレート出力 (パッチ含む) は簡単に手に入りますが、これだけでは「手で入れた設定」が抽出できません。別途うまいことdiff するしくみが必要になります。

テンプレート出力(左) と実機設定(右) をdiff する際、パッチブロックをうまくマージしつつ、同一のものとして扱います。これによって「手で入れた設定」が抽出でき、 それをテンプレート実装する or パッチに入れるの判断が下せるようになります。
パッチには no や delete が混じっている可能性もあり、うまくdiff するには構文解析が必要になります。
ここはそれなりに手間がかかりますが、うまいことやってください。
なお、Juniper の構文解析機能は OSS として公開しています。興味があればご覧ください。
パッチの運用
手で入れた設定は、テンプレート出力(パッチ含む) をロードしてしまうと失われます。 なので定期的に、もしくは何か Event を hook してチェックし、テンプレート実装する or パッチに入れる 判断を促す必要があります。
手で入れた設定は、👇 のようなライフサイクルをたどるイメージになります。
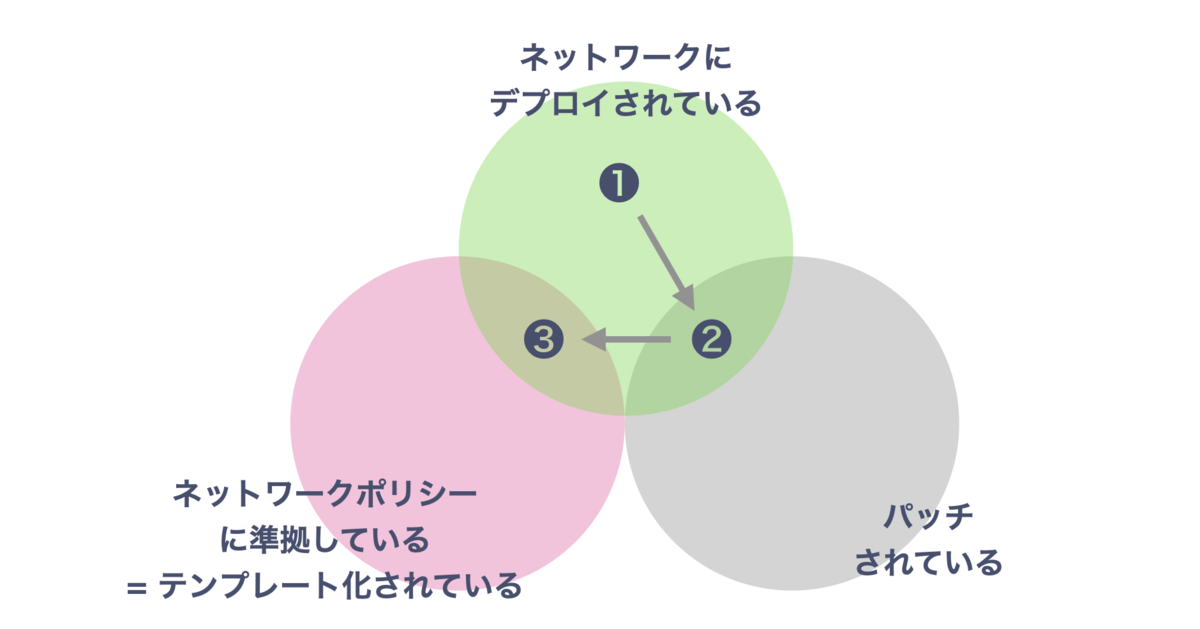
- ビジネス判断により、ネットワークに入れる
- diff によって検知され、パッチする = 永続化される
- 標準として認められれば、テンプレート実装する
パッチを個別に管理することは「ポリシー外がこれだけありますよ」と定量評価できる点で重要だと思っています。
運用的な観点でいえば、例外は想定外なルーティングをし、事故の原因になるかもしれません。 一方で全てテンプレート化するのも毒で、パターンの多さはコードが複雑になるだけではなく、オペレーターを混乱させてしまいます。
何を標準とするか、どれくらいのパターンを許容するか、どのくらいの量のパッチを許容するかは 各社のビジネスや運用によるため「これ」という基準を提示できませんが、定期的に棚卸しする場を持つことは重要だと思います。
「このパッチは標準にいれるべきか」「このパッチは消すべきではないか」などを議論する場ですね。
まとめ
手動オペレーションを許容しつつ、テンプレートシステムによってネットワークポリシーを強制するアプローチについて書きました。これは、従来のネットワーク運用から漸進的に自動運用に移行することを意識しています。
ここでは「全体として、意図どおり設定されているか」のチェックに留まっていますが、本来のNetwork Validation はふるまいの確認であり、さらに先にあります。それについてはまた別で書きたいと思います。